Update: This conjecture has now been solved! See A simple proof of the Gaussian correlation conjecture extended to multivariate gamma distributions by T. Royen, and Royen’s proof of the Gaussian correlation inequality by Rafał Latała, and Dariusz Matlak.
We continue investigating the Gaussian correlation conjecture in this post. This states that if 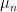 is the standard Gaussian measure on
is the standard Gaussian measure on  then
then
 |
(1) |
for all symmetric and convex sets  . In this entry, we consider a stronger `local’ version of the conjecture, which has the advantage that it can be approached using differential calculus. Inequality (1) can alternatively be stated in terms of integrals,
. In this entry, we consider a stronger `local’ version of the conjecture, which has the advantage that it can be approached using differential calculus. Inequality (1) can alternatively be stated in terms of integrals,
 |
(2) |
This is clearly equivalent to (2) when  are indicator functions of convex symmetric sets. More generally, using linearity, it extends to all nonnegative functions such that
are indicator functions of convex symmetric sets. More generally, using linearity, it extends to all nonnegative functions such that  and
and  are symmetric and convex subsets of for positive
are symmetric and convex subsets of for positive  . A class of functions lying between these two extremes, which I consider here, are the log-concave functions. The reason for concentrating on this class of functions is that they satisfy the following stability result, due to Prékopa (available here) and Leindler.
. A class of functions lying between these two extremes, which I consider here, are the log-concave functions. The reason for concentrating on this class of functions is that they satisfy the following stability result, due to Prékopa (available here) and Leindler.
Theorem 1 If  is log-concave then so is
is log-concave then so is  .
.
The approach used in this post is as follows; Given an nxn matrix  , the idea is to consider a probability measure
, the idea is to consider a probability measure 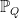 with respect to which we have joint normal random variables
with respect to which we have joint normal random variables 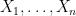 and
and 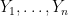 , all with zero mean and unit variance, and covariances given by
, all with zero mean and unit variance, and covariances given by

The random variables 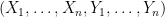 then have covariance matrix
then have covariance matrix

This must be positive semidefinite or, equivalently,  in the operator norm. Writing
in the operator norm. Writing  for expectation with respect to the probability measure , the Gaussian correlation conjecture is equivalent to the statement
for expectation with respect to the probability measure , the Gaussian correlation conjecture is equivalent to the statement
![\displaystyle {\mathbb E}\!_I[f(X)g(Y)]\ge{\mathbb E}\!_0[f(X)g(Y)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5C%21_I%5Bf%28X%29g%28Y%29%5D%5Cge%7B%5Cmathbb+E%7D%5C%21_0%5Bf%28X%29g%28Y%29%5D.+&bg=ffffff&fg=000000&s=0&c=20201002) |
(3) |
Furthermore, considering ![{{\mathbb E}_Q[f(X)g(Y)]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D_Q%5Bf%28X%29g%28Y%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) as a function of , its partial derivatives can be calculated as follows,
as a function of , its partial derivatives can be calculated as follows,
![\displaystyle \frac{\partial}{\partial Q_{ij}}{\mathbb E}\!_Q\left[f(X)g(Y)\right]={\mathbb E}\!_Q\left[D_if(X)D_jg(Y)\right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+Q_%7Bij%7D%7D%7B%5Cmathbb+E%7D%5C%21_Q%5Cleft%5Bf%28X%29g%28Y%29%5Cright%5D%3D%7B%5Cmathbb+E%7D%5C%21_Q%5Cleft%5BD_if%28X%29D_jg%28Y%29%5Cright%5D.+&bg=ffffff&fg=000000&s=0&c=20201002) |
(4) |
Using this, the Taylor expansion to second order about Q=0 can be written as,
![\displaystyle {\mathbb E}\!_Q\left[f(X)g(Y)\right] = {\mathbb E}\!_0\left[f(X)g(Y)\right]+Q_{i_1j_1}Q_{i_2j_2}\mu_n(D_{i_1i_2}f)\mu_n(D_{j_1j_2}g)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5C%21_Q%5Cleft%5Bf%28X%29g%28Y%29%5Cright%5D+%3D+%7B%5Cmathbb+E%7D%5C%21_0%5Cleft%5Bf%28X%29g%28Y%29%5Cright%5D%2BQ_%7Bi_1j_1%7DQ_%7Bi_2j_2%7D%5Cmu_n%28D_%7Bi_1i_2%7Df%29%5Cmu_n%28D_%7Bj_1j_2%7Dg%29+&bg=ffffff&fg=000000&s=0&c=20201002)
(we use the summation convention where repeated indices in a product are summed over). From Theorem 1, the function  is log-concave and, therefore the matrix
is log-concave and, therefore the matrix  is positive semidefinite. So, to second order in Q,
is positive semidefinite. So, to second order in Q,
![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rcl} \displaystyle {\mathbb E}\!_Q\left[f(X)g(Y)\right] - {\mathbb E}\!_0\left[f(X)g(Y)\right] &\displaystyle =&\displaystyle {\rm Tr}(Q^tA_fQA_g)\\ &\displaystyle=&\displaystyle {\rm Tr}(A_g^{1/2}Q^tA_fQA_g^{1/2})\ge 0. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brcl%7D+%5Cdisplaystyle+%7B%5Cmathbb+E%7D%5C%21_Q%5Cleft%5Bf%28X%29g%28Y%29%5Cright%5D+-+%7B%5Cmathbb+E%7D%5C%21_0%5Cleft%5Bf%28X%29g%28Y%29%5Cright%5D+%26%5Cdisplaystyle+%3D%26%5Cdisplaystyle+%7B%5Crm+Tr%7D%28Q%5EtA_fQA_g%29%5C%5C+%26%5Cdisplaystyle%3D%26%5Cdisplaystyle+%7B%5Crm+Tr%7D%28A_g%5E%7B1%2F2%7DQ%5EtA_fQA_g%5E%7B1%2F2%7D%29%5Cge+0.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
If are strictly log-concave, so that  are positive definite, then this shows that has a local minimum at
are positive definite, then this shows that has a local minimum at 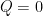 . This suggests the following conjecture, which is stronger than the Gaussian correlation inequality.
. This suggests the following conjecture, which is stronger than the Gaussian correlation inequality.
Conjecture: For log-concave functions on , then over all matrices , the function ![{Q\mapsto{\mathbb E}_Q[f(X)g(Y)]}](https://s0.wp.com/latex.php?latex=%7BQ%5Cmapsto%7B%5Cmathbb+E%7D_Q%5Bf%28X%29g%28Y%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is minimized at . In fact, we conjecture that it never has a (strict) local minimum at any
is minimized at . In fact, we conjecture that it never has a (strict) local minimum at any  .
.
Certainly, this conjecture would imply (3). Being a stronger version of the Gaussian correlation inequality, we can be less sure that this statement holds than the original conjecture. However, if it is true then it has one advantage. That is, it can be approached locally with respect to the covariances, only considering infinitesimal changes in Q. In fact, it can be shown to be equivalent to the following (for any fixed log-concave and differentiable  ). I do not give the proof here, to save space, but it is just an application of equation (4).
). I do not give the proof here, to save space, but it is just an application of equation (4).
Conjecture: For all log-concave functions  , the matrix
, the matrix 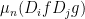 is never symmetric and negative definite.
is never symmetric and negative definite.
If this can be proven, then the correlation conjecture follows. As demonstrated in 1977 by Pitt, the Gaussian correlation conjecture will follow if this matrix always has nonnegative trace (this was used to prove the two dimensional case of the conjecture), which would certainly imply that it can’t be negative definite. It is easily shown that the matrix will indeed have nonnegative trace if the Gaussian measure is replaced by the standard (Lebesgue) measure. This is because  is log-concave and symmetric in
is log-concave and symmetric in  (by Theorem 1), and is therefore maximized at
(by Theorem 1), and is therefore maximized at 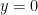 . Expanding to second order in y shows that
. Expanding to second order in y shows that  is symmetric and positive semidefinite. In fact, in two dimensions it can be shown that
is symmetric and positive semidefinite. In fact, in two dimensions it can be shown that

has nonnegative trace (see Pitt). From this it follows that  has nonnegative trace for all decreasing functions
has nonnegative trace for all decreasing functions  . In particular, letting
. In particular, letting 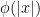 be the Gaussian density, the above conjecture follows. I don’t know whether a similar argument can be carried across to an arbitrary number of dimensions.
be the Gaussian density, the above conjecture follows. I don’t know whether a similar argument can be carried across to an arbitrary number of dimensions.
Consider, for example, the case where  is a function of
is a function of  for a positive definite matrix
for a positive definite matrix  . This includes the cases where
. This includes the cases where  is a centered ellipsoid (proven in 1999 by Hargé) and, as a limit of centered ellipsoids, where it is a symmetric slab (i.e., the region between two parallel hyperplanes, independently proven in 1967 by both Khatri and Šidák). Say,
is a centered ellipsoid (proven in 1999 by Hargé) and, as a limit of centered ellipsoids, where it is a symmetric slab (i.e., the region between two parallel hyperplanes, independently proven in 1967 by both Khatri and Šidák). Say, 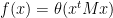 . Then,
. Then,
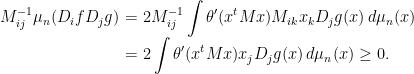
The final inequality follows because and are necessarily decreasing along lines going radially out from the origin, implying that  and
and  are both nonpositive. Consequently, is not positive definite in this case and the Gaussian correlation inequality follows for centered ellipsoids.
are both nonpositive. Consequently, is not positive definite in this case and the Gaussian correlation inequality follows for centered ellipsoids.


Arrgh! I’ve been using the evil we throughout my initial posts. I’ll do better in future.
It is perfectly OK to use “we” about yourself and your tapeworm — which should of course be properly credited.
By the way, is it just me, or are we lacking an RSS feed for new posts? (I.e. do we have to resort to e-mail notification?)
Thanks Porcus, I’ll bear that in mind.
And no, it’s not just you (or your tapeworm), but I’ve added RSS feeds now.
Hi,
You might be interested in this paper
Click to access 1012.0676v1.pdf
Regards
Thanks.
However, I do see a problem in that paper. How does proving the result for sets with Gaussian measure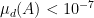 imply it for all sets? It mentions "contracting the sets linearly", but how does that work? Certainly
imply it for all sets? It mentions "contracting the sets linearly", but how does that work? Certainly  for c less than one. Also, for sets contained in
for c less than one. Also, for sets contained in  ,
, 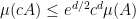 holds. If I try scaling the sets down so that they have probability no more than 10-7, this leads to a factor of
holds. If I try scaling the sets down so that they have probability no more than 10-7, this leads to a factor of 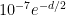 which, rather crucially, depends on d. You can probably do better than that, but I don’t know where the claimed
which, rather crucially, depends on d. You can probably do better than that, but I don’t know where the claimed  comes from.
comes from.
There is something else in Guan’s paper, I do not understand:
On Page 2, line 4, he seems to apply the CLT to the set , and in the definition of
, and in the definition of  the
the , so one would need some uniformity of the convergence in the CLT. I do not see
, so one would need some uniformity of the convergence in the CLT. I do not see
left depends on
that, can anybody help me?
Thomas Schlunprecht:
That’s a very good point! It does look like a problem. In fact, conditioning on the event (i.e., the event
(i.e., the event  in the paper), the law of large numbers implies that the term on the left hand side of the inequality defining
in the paper), the law of large numbers implies that the term on the left hand side of the inequality defining  almost surely grows at rate
almost surely grows at rate
This is at least as large as)/(\mathbb{E}[X_1^4\mid X_1\in D]^{1/2}\mu(D)^{1/2})](https://s0.wp.com/latex.php?latex=%5Csqrt%7Bn%7D%5Cmathbb%7BE%7D%5BX_1%5E2%5Cvert+X_1%5Cin+D%5D%281-%5Cmu%28D%29%29%2F%28%5Cmathbb%7BE%7D%5BX_1%5E4%5Cmid+X_1%5Cin+D%5D%5E%7B1%2F2%7D%5Cmu%28D%29%5E%7B1%2F2%7D%29&bg=ffffff&fg=000000&s=0&c=20201002) , and is larger than the right hand side of the inequality whenever
, and is larger than the right hand side of the inequality whenever ![\mathbb{E}[X_1^2\mid X_1\in D] > 10^{-2}\mathbb{E}[X_1^4\mid X_1\in D]^{1/2}/(1-\mu_d(D))](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_1%5E2%5Cmid+X_1%5Cin+D%5D+%3E+10%5E%7B-2%7D%5Cmathbb%7BE%7D%5BX_1%5E4%5Cmid+X_1%5Cin+D%5D%5E%7B1%2F2%7D%2F%281-%5Cmu_d%28D%29%29&bg=ffffff&fg=000000&s=0&c=20201002) (and I see no reason why that shouldn’t be the case). Then,
(and I see no reason why that shouldn’t be the case). Then,  , which means that the CLT cannot give the claimed bound. Using this expression instead of the CLT gives zero on the right hand side of (2.4), which isn’t very useful, and I don’t see how the rest of the argument can follow.
, which means that the CLT cannot give the claimed bound. Using this expression instead of the CLT gives zero on the right hand side of (2.4), which isn’t very useful, and I don’t see how the rest of the argument can follow.
So, unless I am mistaken, this does seem like a major problem in the argument.
Hi,
Thanks for your observations, they seem quite clear and serious enough to have legitimate doubts about the proof. Unfortunately, I couldn’t find the author’s e-mail so he could discuss his argument with you.
Best Regards
The author of the paper seems to be this: http://159.226.47.50:8080/iam/guanqingyang/
Loved reading this thank yyou