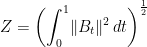Spitzer’s formula is a remarkable result giving the precise joint distribution of the maximum and terminal value of a random walk in terms of the marginal distributions of the process. I have already covered the use of the reflection principle to describe the maximum of Brownian motion, and the same technique can be used for simple symmetric random walks which have a step size of ±1. What is remarkable about Spitzer’s formula is that it applies to random walks with any step distribution.
We consider partial sums
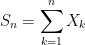 |
for an independent identically distributed (IID) sequence of real-valued random variables X1, X2, …. This ranges over index n = 0, 1, … starting at S0 = 0 and has running maximum
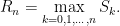 |
Spitzer’s theorem is typically stated in terms of characteristic functions, giving the distributions of (Rn, Sn) in terms of the distributions of the positive and negative parts, Sn+ and Sn–, of the random walk.
Theorem 1 (Spitzer) For α, β ∈ ℝ,
(1) where ϕn, wn are the characteristic functions
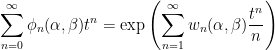
![\displaystyle \begin{aligned} \phi_n(\alpha,\beta)&={\mathbb E}\left[e^{i\alpha R_n+i\beta(R_n-S_n)}\right],\\ w_n(\alpha,\beta)&={\mathbb E}\left[e^{i\alpha S_n^++i\beta S_n^-}\right]\\ &={\mathbb E}\left[e^{i\alpha S_n^+}\right]+{\mathbb E}\left[e^{i\beta S_n^-}\right]-1. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cphi_n%28%5Calpha%2C%5Cbeta%29%26%3D%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7Bi%5Calpha+R_n%2Bi%5Cbeta%28R_n-S_n%29%7D%5Cright%5D%2C%5C%5C+w_n%28%5Calpha%2C%5Cbeta%29%26%3D%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7Bi%5Calpha+S_n%5E%2B%2Bi%5Cbeta+S_n%5E-%7D%5Cright%5D%5C%5C+%26%3D%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7Bi%5Calpha+S_n%5E%2B%7D%5Cright%5D%2B%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7Bi%5Cbeta+S_n%5E-%7D%5Cright%5D-1.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
As characteristic functions are bounded by 1, the infinite sums in (1) converge for |t|< 1. However, convergence is not really necessary to interpret this formula, since both sides can be considered as formal power series in indeterminate t, with equality meaning that coefficients of powers of t are equated. Comparing powers of t gives
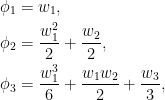 |
(2) |
and so on.
Spitzer’s theorem in the form above describes the joint distribution of the nonnegative random variables (Rn, Rn - Sn) in terms of the nonnegative variables (Sn+, Sn–). While this does have a nice symmetry, it is often more convenient to look at the distribution of (Rn, Sn) in terms of (Sn+, Sn), which is achieved by replacing α with α + β and β with –β in (1). This gives a slightly different, but equivalent, version of the theorem.
Theorem 2 (Spitzer) For α, β ∈ ℝ,
(3) where ϕ̃n, w̃n are the characteristic functions

![\displaystyle \begin{aligned} \tilde\phi_n(\alpha,\beta)&={\mathbb E}\left[e^{i\alpha R_n+i\beta S_n}\right],\\ \tilde w_n(\alpha,\beta)&={\mathbb E}\left[e^{i\alpha S_n^++i\beta S_n}\right]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Ctilde%5Cphi_n%28%5Calpha%2C%5Cbeta%29%26%3D%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7Bi%5Calpha+R_n%2Bi%5Cbeta+S_n%7D%5Cright%5D%2C%5C%5C+%5Ctilde+w_n%28%5Calpha%2C%5Cbeta%29%26%3D%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7Bi%5Calpha+S_n%5E%2B%2Bi%5Cbeta+S_n%7D%5Cright%5D.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Taking β = 0 in either (1) or (3) gives the distribution of Rn in terms of Sn+,
![\displaystyle \sum_{n=0}^\infty {\mathbb E}\left[e^{i\alpha R_n}\right]t^n=\exp\left(\sum_{n=1}^\infty {\mathbb E}\left[e^{i\alpha S_n^+}\right]\frac{t^n}n\right)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7Bn%3D0%7D%5E%5Cinfty+%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7Bi%5Calpha+R_n%7D%5Cright%5Dt%5En%3D%5Cexp%5Cleft%28%5Csum_%7Bn%3D1%7D%5E%5Cinfty+%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7Bi%5Calpha+S_n%5E%2B%7D%5Cright%5D%5Cfrac%7Bt%5En%7Dn%5Cright%29+&bg=ffffff&fg=000000&s=0&c=20201002) |
(4) |
I will give a proof of Spitzer’s theorem below. First, though, let’s look at some consequences, starting with the following strikingly simple result for the expected maximum of a random walk.
Corollary 3 For each n ≥ 0,
(5)
![\displaystyle {\mathbb E}[R_n]=\sum_{k=1}^n\frac1k{\mathbb E}[S_k^+].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7B%5Cmathbb+E%7D%5BR_n%5D%3D%5Csum_%7Bk%3D1%7D%5En%5Cfrac1k%7B%5Cmathbb+E%7D%5BS_k%5E%2B%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: As Rn ≥ S1+ = X1+, if Xk+ have infinite mean then both sides of (5) are infinite. On the other hand, if Xk+ have finite mean then so do Sn+ and Rn. Using the fact that the derivative of the characteristic function of an integrable random variable at 0 is just i times its expected value, compute the derivative of (4) at α = 0,
![\displaystyle \begin{aligned} \sum_{n=0}^\infty i{\mathbb E}[R_n]t^n &=\exp\left(\sum_{n=1}^\infty \frac{t^n}n\right)\sum_{n=1}^\infty i{\mathbb E}[S_n^+]\frac{t^n}n\\ &=\exp\left(-\log(1-t)\right)\sum_{n=1}^\infty i{\mathbb E}[S_n^+]\frac{t^n}n\\ &=(1-t)^{-1}\sum_{n=1}^\infty i{\mathbb E}[S_n^+]\frac{t^n}n\\ &=(1+t+t^2+\cdots)\sum_{n=1}^\infty i{\mathbb E}[S_n^+]\frac{t^n}n. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Csum_%7Bn%3D0%7D%5E%5Cinfty+i%7B%5Cmathbb+E%7D%5BR_n%5Dt%5En+%26%3D%5Cexp%5Cleft%28%5Csum_%7Bn%3D1%7D%5E%5Cinfty+%5Cfrac%7Bt%5En%7Dn%5Cright%29%5Csum_%7Bn%3D1%7D%5E%5Cinfty+i%7B%5Cmathbb+E%7D%5BS_n%5E%2B%5D%5Cfrac%7Bt%5En%7Dn%5C%5C+%26%3D%5Cexp%5Cleft%28-%5Clog%281-t%29%5Cright%29%5Csum_%7Bn%3D1%7D%5E%5Cinfty+i%7B%5Cmathbb+E%7D%5BS_n%5E%2B%5D%5Cfrac%7Bt%5En%7Dn%5C%5C+%26%3D%281-t%29%5E%7B-1%7D%5Csum_%7Bn%3D1%7D%5E%5Cinfty+i%7B%5Cmathbb+E%7D%5BS_n%5E%2B%5D%5Cfrac%7Bt%5En%7Dn%5C%5C+%26%3D%281%2Bt%2Bt%5E2%2B%5Ccdots%29%5Csum_%7Bn%3D1%7D%5E%5Cinfty+i%7B%5Cmathbb+E%7D%5BS_n%5E%2B%5D%5Cfrac%7Bt%5En%7Dn.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
Equating powers of t gives the result. ⬜
The expression for the distribution of Rn in terms of Sn+ might not be entirely intuitive at first glance. Sure, it describes the characteristic functions and, hence, determines the distribution. However, we can describe it more explicitly. As suggested by the evaluation of the first few terms in (2), each ϕn is a convex combination of products of the wn. As is well known, the characteristic function of the sum of random variables is equal to the product of their characteristic functions. Also, if we select a random variable at random from a finite set, then its characteristic function is a convex combination of those of the individual variables with coefficients corresponding to the probabilities in the random choice. So, (3) expresses the distribution of (Rn, Sn) as a random choice of sums of independent copies of (Sk+, Sk).
In fact, expressions such as (1,3) are common in many branches of maths, such as zeta functions associated with curves over finite fields. We have a power series which can be expressed in two different ways,
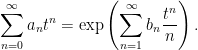 |
The left hand side is the generating function of the sequence an. The right hand side is a kind of zeta function associated with the sequence bn, and is sometimes referred to as the combinatorial zeta function. The logarithmic derivative gives Σnbntn-1, which is the generating function of bn+1. Continue reading “Spitzer’s Formula”


![\displaystyle \begin{aligned} {\mathbb E}[f(X_1)\vert\;W_1 > 0] &={\mathbb E}[f(M_1/2-W_1)]\\ &=2\int_{-\infty}^\infty\int_{x_+}^\infty f(y/2-x)\varphi'(x-2y)\,dydx\\ &=4\int_{-\infty}^\infty\int_{(-x)\vee(-x/2)}^\infty f(z)\varphi'(-3x-4z)\,dzdx\\ &=4\int_{-\infty}^\infty\int_{(-z)\vee(-2z)}^\infty f(z)\varphi'(-3x-4z)\,dxdz\\ &=\frac43\int_{-\infty}^\infty f(z)\varphi(2z)\,dz+\frac43\int_0^\infty f(z)\varphi(z)\,dz. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5Bf%28X_1%29%5Cvert%5C%3BW_1+%3E+0%5D+%26%3D%7B%5Cmathbb+E%7D%5Bf%28M_1%2F2-W_1%29%5D%5C%5C+%26%3D2%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty%5Cint_%7Bx_%2B%7D%5E%5Cinfty+f%28y%2F2-x%29%5Cvarphi%27%28x-2y%29%5C%2Cdydx%5C%5C+%26%3D4%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty%5Cint_%7B%28-x%29%5Cvee%28-x%2F2%29%7D%5E%5Cinfty+f%28z%29%5Cvarphi%27%28-3x-4z%29%5C%2Cdzdx%5C%5C+%26%3D4%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty%5Cint_%7B%28-z%29%5Cvee%28-2z%29%7D%5E%5Cinfty+f%28z%29%5Cvarphi%27%28-3x-4z%29%5C%2Cdxdz%5C%5C+%26%3D%5Cfrac43%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+f%28z%29%5Cvarphi%282z%29%5C%2Cdz%2B%5Cfrac43%5Cint_0%5E%5Cinfty+f%28z%29%5Cvarphi%28z%29%5C%2Cdz.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
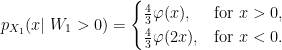
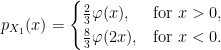

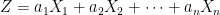

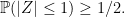

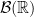 , which I will also shorten to
, which I will also shorten to 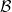 . An explicit construction of a non-Borel set was given by Lusin in 1927. Every irrational real number can be expressed uniquely as a
. An explicit construction of a non-Borel set was given by Lusin in 1927. Every irrational real number can be expressed uniquely as a 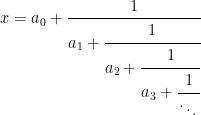

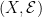 consisting of sigma-algebra
consisting of sigma-algebra  on set
on set  consists of all subsets
consists of all subsets  with
with 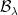 is the Lebesgue sigma-algebra, which I will denote by
is the Lebesgue sigma-algebra, which I will denote by 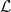 . Usually, when saying that a subset of the reals is measurable without further qualification, it is understood to mean that it is in
. Usually, when saying that a subset of the reals is measurable without further qualification, it is understood to mean that it is in  consists of the subsets of
consists of the subsets of 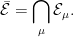
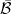 .
. consisting of all subsets of a set
consisting of all subsets of a set 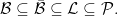
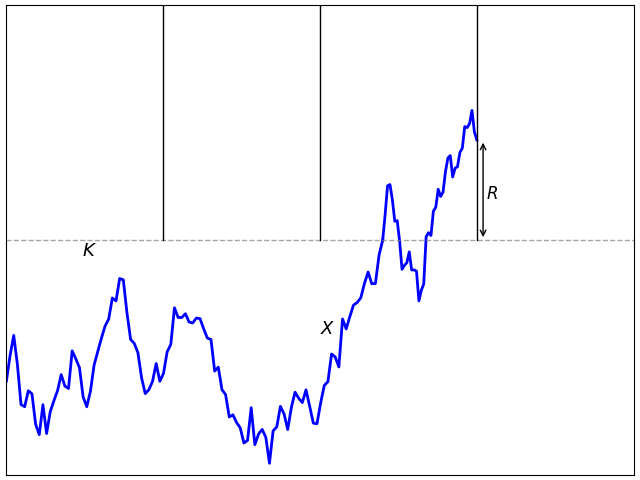
![\displaystyle V={\mathbb E}\left[f(X_T);\;\sup{}_{t\le T}X_t \ge K\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+V%3D%7B%5Cmathbb+E%7D%5Cleft%5Bf%28X_T%29%3B%5C%3B%5Csup%7B%7D_%7Bt%5Cle+T%7DX_t+%5Cge+K%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle V={\mathbb E}\left[f(X_T);\;\sup{}_{i=1,\ldots,n}X_{t_i}\ge K\right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+V%3D%7B%5Cmathbb+E%7D%5Cleft%5Bf%28X_T%29%3B%5C%3B%5Csup%7B%7D_%7Bi%3D1%2C%5Cldots%2Cn%7DX_%7Bt_i%7D%5Cge+K%5Cright%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle V={\mathbb E}\left[f(X_T);\;\sup{}_{i=1,\ldots,n}M_i\ge K\right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+V%3D%7B%5Cmathbb+E%7D%5Cleft%5Bf%28X_T%29%3B%5C%3B%5Csup%7B%7D_%7Bi%3D1%2C%5Cldots%2Cn%7DM_i%5Cge+K%5Cright%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)

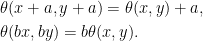
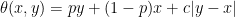
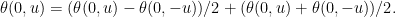


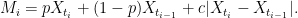

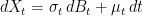

 . As with
. As with 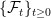 . It is important to do this in a way which does not destroy properties of existing processes, such as their distributions conditional on the filtration at each time.
. It is important to do this in a way which does not destroy properties of existing processes, such as their distributions conditional on the filtration at each time.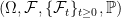 . An enlargement
. An enlargement
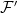 and
and  , and preserving probabilities. So
, and preserving probabilities. So 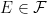 . In addition, it is required to be
. In addition, it is required to be 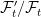 measurable for each time
measurable for each time  for all
for all 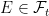 . Consequently, any adapted process
. Consequently, any adapted process  consisting of sets
consisting of sets 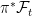 . This is essentially a no-op, since events and random variables on the original filtered probability space are in one-to-one correspondence with those on the enlarged space, up to zero probability events. Next, the sigma-algebras are enlarged to
. This is essentially a no-op, since events and random variables on the original filtered probability space are in one-to-one correspondence with those on the enlarged space, up to zero probability events. Next, the sigma-algebras are enlarged to  and
and 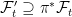 . This is where new random events are added to the event space and filtration.
. This is where new random events are added to the event space and filtration.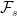 . Does it necessarily lift to a Brownian motion on the enlarged space? The answer to this is no! It need not be the case that
. Does it necessarily lift to a Brownian motion on the enlarged space? The answer to this is no! It need not be the case that 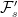 . For an extreme case, consider the situation where
. For an extreme case, consider the situation where 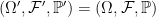 and
and 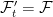 , consider what happens to our Brownian motion. The increment
, consider what happens to our Brownian motion. The increment  , the entire path of
, the entire path of ![{ Y={\mathbb E}[X\vert\mathcal F_t]}](https://s0.wp.com/latex.php?latex=%7B+Y%3D%7B%5Cmathbb+E%7D%5BX%5Cvert%5Cmathcal+F_t%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) for random variables
for random variables ![{ Y^*={\mathbb E}[X^*\vert\mathcal F'_t]}](https://s0.wp.com/latex.php?latex=%7B+Y%5E%2A%3D%7B%5Cmathbb+E%7D%5BX%5E%2A%5Cvert%5Cmathcal+F%27_t%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . This is exactly relative independence of
. This is exactly relative independence of 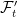 and
and 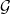 and
and 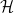 are
are 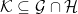 if
if![\displaystyle {\mathbb P}(A\cap B) = {\mathbb E}\left[{\mathbb P}(A\vert\mathcal K){\mathbb P}(B\vert\mathcal K)\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7B%5Cmathbb+P%7D%28A%5Ccap+B%29+%3D+%7B%5Cmathbb+E%7D%5Cleft%5B%7B%5Cmathbb+P%7D%28A%5Cvert%5Cmathcal+K%29%7B%5Cmathbb+P%7D%28B%5Cvert%5Cmathcal+K%29%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
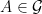 and
and 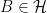 . The following properties are each equivalent to this definition;
. The following properties are each equivalent to this definition;![{{\mathbb E}[XY\vert\mathcal K]={\mathbb E}[X\vert\mathcal K]{\mathbb E}[Y\vert\mathcal K]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BXY%5Cvert%5Cmathcal+K%5D%3D%7B%5Cmathbb+E%7D%5BX%5Cvert%5Cmathcal+K%5D%7B%5Cmathbb+E%7D%5BY%5Cvert%5Cmathcal+K%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) for all bounded
for all bounded ![{{\mathbb E}[X\vert\mathcal G]={\mathbb E}[X\vert\mathcal K]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BX%5Cvert%5Cmathcal+G%5D%3D%7B%5Cmathbb+E%7D%5BX%5Cvert%5Cmathcal+K%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) for all bounded
for all bounded ![{{\mathbb E}[X\vert\mathcal H]={\mathbb E}[X\vert\mathcal K]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BX%5Cvert%5Cmathcal+H%5D%3D%7B%5Cmathbb+E%7D%5BX%5Cvert%5Cmathcal+K%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) for all bounded
for all bounded 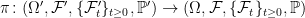
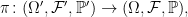
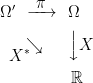
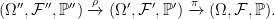
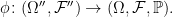
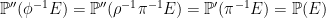

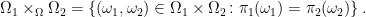
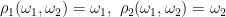
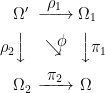

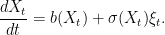
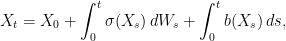



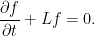
![\displaystyle {\mathbb E}[g(X_t)\;\vert\mathcal F_s]=f(X_s,s).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7B%5Cmathbb+E%7D%5Bg%28X_t%29%5C%3B%5Cvert%5Cmathcal+F_s%5D%3Df%28X_s%2Cs%29.+&bg=ffffff&fg=000000&s=0&c=20201002)
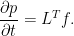
![\displaystyle {\mathbb E}[X^s]=2\xi(s),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5BX%5Es%5D%3D2%5Cxi%28s%29%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle {\mathbb E}[X^s]=\frac{1-2^{1-s}}{s-1}2\xi(s)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5BX%5Es%5D%3D%5Cfrac%7B1-2%5E%7B1-s%7D%7D%7Bs-1%7D2%5Cxi%28s%29+&bg=ffffff&fg=000000&s=0&c=20201002)