In the previous post, I used the property of bounded convergence in probability to define stochastic integration for bounded predictable integrands. For most applications, this is rather too restrictive, and in this post the integral will be extended to unbounded integrands. As bounded convergence is not much use in this case, the dominated convergence theorem will be used instead.
The first thing to do is to define a class of integrable processes for which the integral with respect to  is well-defined. Suppose that
is well-defined. Suppose that 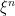 is a sequence of predictable processes dominated by any such -integrable process
is a sequence of predictable processes dominated by any such -integrable process  , so that
, so that 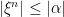 for each
for each  . If this sequence converges to a limit
. If this sequence converges to a limit  , then dominated convergence in probability states that the integrals converge in probability,
, then dominated convergence in probability states that the integrals converge in probability,
 |
(1) |
as 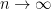 .
.
We can now define the -integrable processes as the largest class of predictable processes for which dominated convergence can possibly hold. That is, they are `good dominators’. This ensures that we include all possible integrands, and it is easy to show that stochastic integration is indeed well defined for such integrands. The definition necessarily only involves integration with respect to bounded predictable integrands, as that is all we have defined so far.
Definition 1 Let be a semimartingale. Then,  consists of the set of predictable processes such that, for each
consists of the set of predictable processes such that, for each  and sequence of bounded predictable processes
and sequence of bounded predictable processes 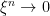 with
with  , then
, then 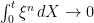 in probability as
in probability as  .
.
Alternatively, processes in are called -integrable.
Alternative approaches to stochastic integration often define the class of -integrable processes with regard to specific decompositions of . Alternatively, as I shall show in a later post, a predictable process is -integrable if and only if
is bounded in probability for each . However, I prefer the definition above, as it seems to be much more direct and it is clear that all integrands should satisfy this definition. Furthermore, the properties of stochastic integrals follow easily from this. Note that, by bounded convergence, includes all bounded predictable processes. As we would hope, it is closed under taking linear combinations.
Lemma 2 Let be a semimartingale. Then, the class of -integrable processes is a vector space. Furthermore, if  for any predictable process and -integrable process
for any predictable process and -integrable process  , then is also -integrable.
, then is also -integrable.
Proof: First, the `furthermore’ statement is a trivial consequence of the definition. To prove the result, it is enough to show that 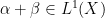 for all
for all 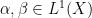 . Then, suppose that
. Then, suppose that  is a sequence of bounded predictable processes tending to zero. Setting
is a sequence of bounded predictable processes tending to zero. Setting
gives  and
and 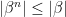 and
and  . So, applying dominated convergence to
. So, applying dominated convergence to  individually gives
individually gives
in probability as 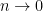 . By definition, this shows that . ⬜
. By definition, this shows that . ⬜
Now that we have chosen the largest possible class of predictable processes which can work as integrands, stochastic integration is defined in a similar way as for bounded integrands. That is, it agrees with the explicit expression for the elementary integrands, and satisfies dominated convergence.
Definition 3 Let be a semimartingale and . Then, the stochastic integral up to  is a map
is a map
As we would hope, this definition is indeed enough to uniquely specify the stochastic integral.
Lemma 4 Let be a semimartingale. Then, the stochastic integral given by Definition 3 is uniquely defined, is linear in the integrand, and agrees with the previous definition for bounded predictable integrands.
Proof: As contains the bounded predictable processes, bounded convergence in probability is just a special case of dominated convergence. So, if it exists, the integral must coincide with that given by the previous definition for bounded integrands.
Conversely, as is a semimartingale, the integral is defined for bounded integrands. It just needs to be extended to all -integrable processes. For any  choose a sequence
choose a sequence  of bounded predictable processes which is dominated by some process
of bounded predictable processes which is dominated by some process  . For example, this can be achieved by setting
. For example, this can be achieved by setting  , so
, so 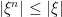 . Given such a sequence it follows that
. Given such a sequence it follows that  is dominated by
is dominated by 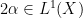 and tends to zero as
and tends to zero as  . So,
. So,
in probability as . By completeness under convergence in probability, this allows us to define
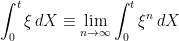 |
(2) |
under convergence in probability. It needs to be shown that this definition is independent of the sequence chosen. So, suppose that 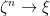 is any other sequence of bounded predictable processes dominated by some
is any other sequence of bounded predictable processes dominated by some 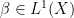 . Then,
. Then,  is dominated by
is dominated by  and
and
so equation (2) uniquely defines the integral. Furthermore, if is bounded, taking  shows that the integral is consistent with the definition for bounded integrands.
shows that the integral is consistent with the definition for bounded integrands.
Now, let us prove linearity. If and 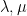 are real numbers, then choose sequences of bounded predictable processes
are real numbers, then choose sequences of bounded predictable processes 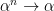 ,
,  which are dominated by some -integrable process. As is a vector space,
which are dominated by some -integrable process. As is a vector space,  will also be dominated by an element of . Linearity for bounded integrands gives
will also be dominated by an element of . Linearity for bounded integrands gives
as required.
Finally, we can prove that dominated convergence in probability holds. Let be predictable processes dominated by some . Then, by equation (2), there exist bounded predictable processes 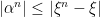 satisfying
satisfying
Then, 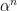 tends to zero and is dominated by
tends to zero and is dominated by  giving,
giving,
in probability as , as required. ⬜
Choosing a good version
As stochastic integration of an integrand with respect to a semimartingale exists up to all times , it defines a new stochastic process  . Note, however, that the integral takes values in the space
. Note, however, that the integral takes values in the space 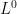 , of random variables defined up to almost sure equivalence. Therefore, the value of the process
, of random variables defined up to almost sure equivalence. Therefore, the value of the process  at each time is only defined up to probability one. As discussed in a previous post, this means that the sample paths
at each time is only defined up to probability one. As discussed in a previous post, this means that the sample paths 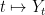 are not well defined (even up to a set of zero probability), and it is important to choose a good version of the process. In fact, it is always possible to choose cadlag versions of stochastic integrals, which are then uniquely defined up to evanescence. The following result shows that stochastic integrals do indeed have cadlag modifications and, in fact, are semimartingales.
are not well defined (even up to a set of zero probability), and it is important to choose a good version of the process. In fact, it is always possible to choose cadlag versions of stochastic integrals, which are then uniquely defined up to evanescence. The following result shows that stochastic integrals do indeed have cadlag modifications and, in fact, are semimartingales.
Lemma 5 Let be a semimartingale, be an -integrable process, and set 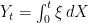 for each time .
for each time .
Then, is an adapted process with respect to which the stochastic integral is well defined for all bounded predictable processes, satisfying
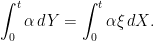 |
(3) |
Furthermore, has a cadlag version.
Proof: For elementary predictable processes  , equality (3) follows directly from the explicit expression for the integrals. It needs to be shown that this extends to all -integrable processes , which can be done using the functional monotone class theorem.
, equality (3) follows directly from the explicit expression for the integrals. It needs to be shown that this extends to all -integrable processes , which can be done using the functional monotone class theorem.
Fixing an elementary process , let  consist of the set of all -integrable processes for which is adapted and (3) is satisfied. This includes all elementary predictable processes and, by bounded convergence in probability, is closed under limits of uniformly bounded sequences. Hence, the functional monotone class theorem implies that contains all bounded predictable processes. Then, applying dominated convergence, contains all -integrable processes.
consist of the set of all -integrable processes for which is adapted and (3) is satisfied. This includes all elementary predictable processes and, by bounded convergence in probability, is closed under limits of uniformly bounded sequences. Hence, the functional monotone class theorem implies that contains all bounded predictable processes. Then, applying dominated convergence, contains all -integrable processes.
This shows that is adapted and that equation (3) is satisfied for elementary processes . This needs to be extended to all bounded predictable processes. However, in that case (3) can be used to define the integral with respect to . Then, dominated convergence applied to integrals with respect to shows that this definition of the integral 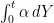 does indeed satisfy the bounded convergence theorem, as required. So, by uniqueness of the definition of the stochastic integral, (3) is satisfied.
does indeed satisfy the bounded convergence theorem, as required. So, by uniqueness of the definition of the stochastic integral, (3) is satisfied.
Finally, as we have shown previously, existence of stochastic integrals with respect to is enough to imply the existence of a cadlag version. ⬜
Finally, then, the full definition of the stochastic integral is as follows.
Definition 6 Let be a semimartingale. Then, for , the stochastic integral  is a cadlag process satisfying Definition 3 for each fixed time .
is a cadlag process satisfying Definition 3 for each fixed time .
Notation
I now mention some notation which will be used for the stochastic integral in these notes. When the integral is written without explicitly putting in the limits, then it will refer to the cadlag process rather than the value at any fixed time. E.g., 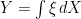 is equivalent to for each .
is equivalent to for each .
Often, the briefer differential notation will be used which, in many situations, can be considerably easier to read. In this notation a differential 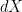 just represents a process , up to addition of a constant. Left-multiplication,
just represents a process , up to addition of a constant. Left-multiplication, 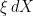 , represents stochastic integration,
, represents stochastic integration,



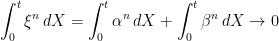








In the proof of Lemma 4 the first definition of \xi^n does not give predictable integrands. What am I missing?
In the proof of Lemma 4, it is not clear to me that the chosen sequence of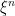 comes with a dominating
comes with a dominating  . Am I missing something?
. Am I missing something?
Nevermind…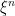 is dominated by
is dominated by 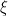 .
.
Could you please elaborate on how you get the bound $|\beta^n|\le |\beta|$ in the proof of Lemma 2?
It helps to separate the cases β^n > 0 and β^n 0 ⟹ β^n = ξ^n – |α| ≤ |α+β| – |α| ≤ |β| ⟹ |β^n| ≤ |β|.
Ooops.
It helps to separate the cases β^n > 0 and β^n 0, then
β^n = ξ^n – |α| ≤ |α+β| – |α| ≤ |β|,
so |β^n| ≤ |β|. The other case is similar.
That should read:
If β^n > 0, then
β^n = ξ^n – |α| ≤ |α+β| – |α| ≤ |β|
so |β^n| ≤ |β|. The other case is similar.
Yes, that works. Should also be able to visualise it. Imagine a plot of function ξ^n. α^n is it capped and floored at ±α, and β^n is the amount by which it exceeds the floor/cap. This can’t be more than β, otherwise ξ^n would exceed the |α|+|β| bound
Hello, I like this approach to construct the stochastic integral. Is there a book that I could cite?