A random variable has the standard n-dimensional normal distribution if its components are independent normal with zero mean and unit variance. A well known fact of such distributions is that they are invariant under rotations, which has the following consequence. The distribution of is invariant under rotations of and, hence, is fully determined by the values of and . This is known as the noncentral chi-square distribution with n degrees of freedom and noncentrality parameter , and denoted by . The moment generating function can be computed,
(1)
which holds for all with real part bounded above by 1/2.
A consequence of this is that the norm of an n-dimensional Brownian motionB is Markov. More precisely, letting be its natural filtration, then has the following property. For times , conditional on , is distributed as . This is known as the `n-dimensional’ squared Bessel process, and denoted by .
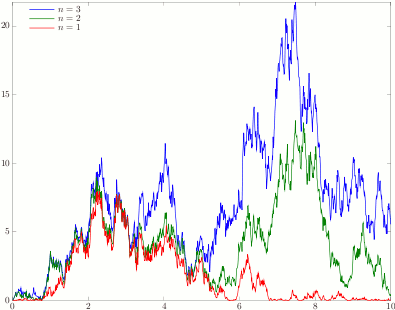
Figure 1: Squared Bessel processes of dimensions n=1,2,3
Alternatively, the process X can be described by a stochastic differential equation (SDE). Applying integration by parts,
(2)
As the standard Brownian motions have quadratic variation, the final term on the right-hand-side is equal to . Also, the covarations are zero for from which it can be seen that
is a continuous local martingale with . By Lévy’s characterization, W is a Brownian motion and, substituting this back into (2), the squared Bessel process X solves the SDE
(3)
The standard existence and uniqueness results for stochastic differential equations do not apply here, since is not Lipschitz continuous. It is known that (3) does in fact have a unique solution, by the Yamada-Watanabe uniqueness theorem for 1-dimensional SDEs. However, I do not need and will not make use of this fact here. Actually, uniqueness in law follows from the explicit computation of the moment generating function in Theorem 5 below.
Although it is nonsensical to talk of an n-dimensional Brownian motion for non-integer n, Bessel processes can be extended to any real . This can be done either by specifying its distributions in terms of chi-square distributions or by the SDE (3). In this post I take the first approach, and then show that they are equivalent. Such processes appear in many situations in the theory of stochastic processes, and not just as the norm of Brownian motion. It also provides one of the relatively few interesting examples of stochastic differential equations whose distributions can be explicitly computed.
The distribution generalizes to all real , and can be defined as the unique distribution on with moment generating function given by equation (1). If and are independent, then has moment generating function and, therefore, has the distribution. That such distributions do indeed exist can be seen by constructing them. The distribution is a special case of the Gamma distribution and has probability density proportional to . If is a sequence of independent random variables with the standard normal distribution and T independently has the Poisson distribution of rate , then , which can be seen by computing its moment generating function. Adding an independent random variable Y to this produces the variable .
The definition of squared Bessel processes of any real dimension is as follows. We work with respect to a filtered probability space.
Definition 1 A process X is a squared Bessel process of dimension if it is continuous, adapted and, for any , conditional on , has the distribution.
Substituting in expression (1) for the moment generating function, this definition is equivalent to X being a continuous adapted process such that, for all times ,
(4)
This holds for all with nonnegative real part. Also, if the filtration is not specified, then a process X is a Bessel process if it satisfies Definition 1 with respect to its natural filtration .
Note that we have not yet shown that Bessel processes for arbitrary non-integer are well-defined. Definition 1 specifies the properties that such processes must satisfy, but this does not guarantee their existence. It is not difficult to show that (4) determines a Markov transition function, so that the Chapman-Kolmogorov identity is satisfied. In fact, as I show below, it is Feller. See Lemma 9 below, where the existence of continuous modifications is also proven.
For now, let us determine some of the properties of Bessel processes. There are some properties which can be stated directly from the definition. The fact that the sum of independent and distributed random variables has the distribution gives the following result for sums of Bessel processes.
Lemma 2 Suppose that X and Y are independent and processes respectively. Then, X+Y is a process.
Next, Definition 1 only referred to the ratio between the process X and the time increments. So, scaling the time axis and the process values by the same factor leaves the property unchanged.
Lemma 3 Let X be a process and be constant. Then, is also a process.
Standard Brownian motion X satisfies a time reversal symmetry whereby is also a standard Brownian motion, as can be determined by computing covariances. It follows that if X is a process for integer n, then so is , as we can see by expressing it as the sum of squares of independent Brownian motions. This time reversal symmetry extends to Bessel processes of non-integer dimension, as we would expect.
Lemma 4 If X is a process then so is .
Proof: As Y is a deterministic time change and scaling of the Markov process X, it is also Markov. Hence, we just need to show that X and Y have the same pairwise distributions. For times , we compute the joint moment generating function of by applying (4) twice,
for any . Since the expression above is unchanged when are replaced by respectively,
showing that and have the same joint distributions as required. ⬜
Taking the limit in expression (4) gives us the probability that is equal to 0.
(5)
So, a process has a positive probability of hitting 0 in any nontrivial time interval. Furthermore, since (5) gives , once it hits zero it remains there. That is, 0 is an absorbing boundary.
The case for is different. Equation (5) says that has zero probability of being equal to 0 at any given time. This does not mean that X cannot hit zero but, rather, that the total Lebesgue measure of its time spent there is zero,
In fact, as we will see, the process does hit zero for all values of n less than 2 so, for , 0 is a reflecting boundary.
We now show the equivalence of the definition of squared Bessel processes in terms of the skew chi-square distribution given in Definition 1 and in terms of the SDE (3). In particular, this demonstrates that (3) satisfies uniqueness in law, which we show by using Ito’s lemma to derive a partial differential equation for the moment generating function.
Theorem 5 For any nonnegative process X and real , the following are equivalent,
X is a process.
is a local martingale and .
X satisfies the SDE
(6)
for a Brownian motion W (in the case n=0, it is necessary to assume the existence of at least one Brownian motion on the underlying filtration).
Proof: (1) implies (2): The moments of a random variable can be computed by expanding and and comparing powers of . From this, we see that Z has mean and variance . So, for the squared Bessel process, has mean and variance conditional on (). Therefore, is a local martingale. Note that it can fail to be a proper martingale, since is not required to be integrable. Also,
(1) implies (3): By the argument above, for a continuous local martingale M with quadratic variation . One of the consequences of Lévy’s characterization is that, assuming that there is at least one Brownian motion defined on the underlying filtration,
for a Brownian motion W. It just needs to be shown that, if n is greater than zero, there does exist such a Brownian motion. Set
which is a local martingale. Its quadratic variation is
As we have already shown that X is nonzero almost everywhere, this gives and, again by Lévy’s characterizationW is a Brownian motion.
(3) implies (2): First, is a local martingale. Then, using gives as required.
(2) implies (1): The idea is to derive a partial differential equation for the moment generating function of , and show that the solution is given by (4). Using the fact that has quadratic variation , Ito’s lemma gives
for constant and times . The final term is a local martingale and is bounded on finite time intervals (as all the other terms are). So, it is a proper martingale. Multiplying by a bounded -measurable random variable Z and taking expectations,
We now introduce the function and, noting that this has partial derivative ,
So, is continuously differentiable over and, by differentiating the above equation, it satisfies the following partial differential equation
This is a transport equation and can be simplified by replacing with a time dependent function satisfying ,
This is just an ordinary differential equation with the unique solution,
(7)
The ODE for is also easily solved, with the unique solution . Using this, the following expressions can be calculated,
Substituting back into (7) and using gives equality (4) as required. ⬜
It is natural to ask about the properties of Bessel process paths such as, does it ever hit zero? Also, what happens to in the limit as t goes to infinity? We show below, in Theorem 7, that for the process hits zero at arbitrarily large times and, for it never hits zero. Furthermore, for it tends to infinity. The idea is to transform the process into a local martingale , so that standard convergence results for continuous local martingales can be applied. The function f is called the scale function of X.
Lemma 6 Let X be a process satisfying the SDE (6) with and make the following substitution.
If , let be the first time at which so that is the process stopped when it first hits zero, and set with
Although the substitutions above for are not defined when X=0, X remains strictly positive in this case.
Proof: For any , let be the first time at which , so and the stopped process is strictly positive. As is a smooth function on , Ito’s lemma can be applied to on the interval ,
Here, the expression has been used. If then substituting expression (8) for b makes the last term on the right hand side equal to zero. So,
Using gives according to whether b is positive () or negative (). So,
on the interval . Letting n increase to infinity, we see that equations (9) and (11) are satisfied on the interval . If then , so is equal to zero over the interval , and (9) is satisfied. On the other hand, if then so Y explodes to infinity at time . However, is a nonnegative local martingale and cannot explode in a finite time. This is a consequence of Fatou’s lemma,
So, Y is almost surely bounded and .
Now, consider the case with and . As is smooth on , Ito’s lemma can be applied on the interval , in a similar way as above,
As above, this holds over the interval and it needs to be shown that almost surely. Letting be the first time at which for some constant K, Y is a local martingale bounded above over the interval . Applying Fatou’s lemma to –Y,
However diverges to at time , so for large enough n (almost surely). Letting K increase to infinity, goes to infinity, showing that is almost surely infinite, as required. ⬜
Using the transformation given by Lemma 6 together with the convergence of continuous local martingales, it is possible to say whether a process hits zero and to determine and , for each value of n.
Theorem 7 Let X be a process. With probability one,
if then X hits 0 at some time, and remains there.
if then X hits zero at arbitrarily large times and .
if then X is strictly positive at all positive times and , .
if then X is strictly positive at all positive times and as .
Recall that the convergence theorem for continuous local martingales states that the events on which a continuous local martingale Y converges to a finite limit, the event on which , and on which , are all identical (up to zero probability sets). This fact is used several times in the following proof.
Proof: The case with is easy. We have already shown that it hits zero with probability by time t conditional on and that, once it hits zero, it stays there. Letting t increase to infinity this converges to 1, so it hits zero almost surely at some positive time.
Let us show that for all . From the definition, has the distribution conditional on , which can be written as the sum of independent random variables and . So, for any constant ,
as , so .
For it was shown in Lemma 6 that X never hits 0 at any time conditional on . As it has zero probability of being equal to zero at a time , this shows that it never hits zero on and, letting t decrease to zero, it never hits zero at any positive time.
Now, consider . As shown in Lemma 6, is a nonnegative local martingale for some continuous and strictly increasing function satisfying , where is the process stopped when it first hits zero. As this trivially satisfies , martingale convergence implies that exists and is finite almost surely. However, as we have just shown, is infinite, so at large enough times. This can only happen if the process hits zero, after which Y is stopped at zero.
Alternatively, if , then is a local martingale for . As shown above, is infinite so, by martingale convergence, . Therefore, .
Finally, it only remains to show that for . Again, using Lemma 6, is a nonnegative local martingale for a strictly positive and continuous function f satisfying as . As above, martingale convergence implies that exists almost surely. However, since we have already shown that , it follows that . So, as , giving as required. ⬜
An immediate consequence of the preceding result is to n-dimensional standard Brownian motion. For positive integers n, the squared Bessel process was introduced above as the squared magnitude of an n-dimensional Brownian motion. In one and two dimensions, we see that Brownian motion is recurrent. That is, with probability one, it enters every nonempty set at arbitrarily large times. As has a countable base for the topology, it is enough to prove this for a countable collection of open sets and, by countable additivity of probability measures, it is equivalent to saying that X almost surely enters the open set U at arbitrarily large times, for each open individually.
In three or more dimensions, Brownian motion is not recurrent. In fact, it diverges to infinity with probability one.
Theorem 8 Let B be an n-dimensional Brownian motion. With probability one,
if then B is recurrent.
if then as .
Proof: For , let be a nonempty open set and choose . Then, is a process. By Theorem 7, , so at arbitrarily large times.
Finally for this post, I show that Bessel process are well defined Markov processes and that continuous modifications do indeed exist.
Lemma 9 Fix any and, for each , let be the transition probability on such that, for each , has moment generating function given by
(12)
Then, is a Feller transition function. Furthermore, any Markov process with this transition function has a continuous modification, which is then a process.
Proof: To show that is a transition function, it is only necessary to prove the Chapman-Kolmogorov equation . This can be verified by directly computing the moment generating functions. Setting ,
so as required.
We now move on to the proof that this is a Feller transition function. It needs to be shown that for any in the set of continuous functions vanishing at infinity, then and as . First, if for a constant then
which satisfies the required properties. This extends to all by uniformly approximating by linear combinations of such functions (see Lemma 10 below).
It only remains to show that a Markov process X with the transition function has a continuous modification. Any such process automatically satisfies (4) and, if it is continuous, is a squared Bessel process by definition. By the existence of cadlag modifications for Feller processes, we may assume that X is cadlag. It just needs to be shown that the jumps are almost surely equal to zero. If are a sequence of times with , then . From this, the following inequality is obtained, bounding the maximum jump of X over the interval .
(13)
We show that the left hand side converges to zero in probability. The moment generating function of can be computed from (4),
where . The expected value of conditional on can be calculated by expanding this out as a power series and looking at the coefficient of . This is a bit messy but, noting that the expression above expands in terms of and , we see that the coefficient of will be equal to multiplied by a polynomial in t–s, s and . Therefore,
over any bounded range for s and t. Taking the expected value conditional on , it follows that the left hand side of (13) goes to zero at rate . So, is almost surely zero, as required. ⬜
The following result for uniformly approximating continuous functions on was used in the proof that is a Feller transition function.
Lemma 10 The set of linear combinations of functions of the form for is dense in (in the uniform norm).
Proof: Any can be written as where is continuous with . By the Stone-Weierstrass approximation theorem there are polynomials converging uniformly to g on the unit interval. Replacing by if necessary, we can suppose that . Then, are linear combinations of functions of the form for and converges uniformly to . ⬜
Hi. I can give a quick answer now, but I’m not going to have much time to go into details for a few days.
1) You can sample a Bessel process exactly at a fixed sequence of times, by sampling from the skew chi-square distributions. As I explained near the top of the post, a distribution can be written as where, Y is , Zi are standard normal and N is Poisson of rate . Equivalently, conditional on N. See the paper Exact Simulation of Bessel Diffusions which includes this and other related methods (actually, I found that paper while searching for another one which I remember from several years ago but forget the title. I’ll come back with the link if I remember…)
2) You can numerically simulate the SDE (3), which only gives an approximate solution, but will likely be much faster if you want to sample it at a dense set of times. It can be done by an Euler scheme. However, if the process is close to zero then the simulation could jump below zero. Then you would have to max with zero, which would bias the distribution causing the drift to increase as the process gets close to zero. This would cause the approximation to converge very slowly in the number of time steps used when n is small. A better way would be to modify the Euler scheme so that you are sampling positive numbers from the start while matching all the moments of dX up to O(dtk), some appropriate k. For example, a trinomial distribution could be used to match all moments up to O(dt3), leading to an O(dt2) error term overall.
thank you for these very interesting answer, and the reference !
I remember a discussion where someone advised me to take the scale function of a diffusion and to try to simulate : this would often eliminate the problem of staying positive (boundary effect), say, and would often be much more precise: I do not remember really well the motivation for that, though. From a practical point of view, why would be worse than taking the scale function in this problem, for example. In one case is obviously a martingale, but I do not understand why this is better. Could you shed some light on this issue ?
Thank you for this fantastic blog!
PS: tiny typo in the definition of above eq 8, no ?
I’m not sure why applying the scale function should eliminate any boundary effect. If you have a squared Bessel process of dimension n < 2, then the scale function is a positive power of X (Lemma 5 above). So it still has a boundary at zero. Also, if n=2, then the scale function is log(x). This does remove the boundary, but the SDE for Y=log(X) is dY = e-Y dW which has exponentially growing coefficients as Y goes negative. That does not look very promising from the point of view of obtaining accurate simulations.
In general, whether or not transforming by the scale function improves the simulations must depend on what particular SDE you start with and what simulation method you are using.
Another point: if f is the scale function then Y=f(X) does not have to be a martingale. In fact, for squared Bessel processes of dimension n > 0, this is never the case. For n < 2 it has a reflecting boundary, so only becomes a martingale if you stop the process at the boundary. For n>=2 the boundary is never attained but, still, Y is not a martingale. It’s just a local martingale.
[Apols. for not responding sooner. Not had chance to log on to my machine the last week].
Also, thanks for mentioning that the transformation I use in Lemma 5 is called the scale function. I updated the text to mention this.
Still don’t see the typo. I have Y = (aXτ)b, which is what was intended. Maybe you are thinking that a should be outside the parentheses? But, that’s not true with my definition of a.
Thank you for all these very interesting comments (and apologize for this very late answer): seems like I have been a little bit optimistic with this “scale function” transformation!
Btw, numerical simulations of SDEs seem to be a very broad area: do you plan on writing on this ?
Great blog btw, really helpful and concise in clarifying many important concepts of stochastic processes. Just wanted to point out a small typo in Theorem 4 (3) -> (2): I think you want .

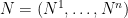

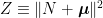
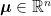
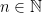
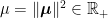

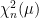
![\displaystyle M_Z(\lambda)\equiv{\mathbb E}\left[e^{\lambda Z}\right]=\left(1-2\lambda\right)^{-\frac{n}{2}}\exp\left(\frac{\lambda\mu}{1-2\lambda}\right),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++M_Z%28%5Clambda%29%5Cequiv%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7B%5Clambda+Z%7D%5Cright%5D%3D%5Cleft%281-2%5Clambda%5Cright%29%5E%7B-%5Cfrac%7Bn%7D%7B2%7D%7D%5Cexp%5Cleft%28%5Cfrac%7B%5Clambda%5Cmu%7D%7B1-2%5Clambda%7D%5Cright%29%2C+&bg=ffffff&fg=000000&s=0&c=20201002)


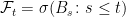



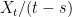

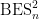
![\displaystyle dX = 2\sum_iB^i\,dB^i+\sum_id[B^i].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++dX+%3D+2%5Csum_iB%5Ei%5C%2CdB%5Ei%2B%5Csum_id%5BB%5Ei%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
![{[B^i]_t=t}](https://s0.wp.com/latex.php?latex=%7B%5BB%5Ei%5D_t%3Dt%7D&bg=ffffff&fg=000000&s=0&c=20201002)
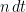
![{[B^i,B^j]}](https://s0.wp.com/latex.php?latex=%7B%5BB%5Ei%2CB%5Ej%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

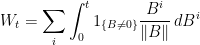
![{[W]_t=t}](https://s0.wp.com/latex.php?latex=%7B%5BW%5D_t%3Dt%7D&bg=ffffff&fg=000000&s=0&c=20201002)

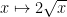




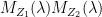
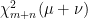
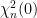
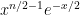
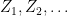

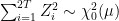
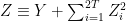
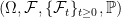
distribution.
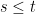
![\displaystyle {\mathbb E}\left[e^{-\lambda X_t}\;\middle\vert\;\mathcal{F}_s\right]=\left(1+2\lambda(t-s)\right)^{-\frac{n}{2}}\exp\left(\frac {-\lambda X_s}{1+2\lambda(t-s)}\right).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7B-%5Clambda+X_t%7D%5C%3B%5Cmiddle%5Cvert%5C%3B%5Cmathcal%7BF%7D_s%5Cright%5D%3D%5Cleft%281%2B2%5Clambda%28t-s%29%5Cright%29%5E%7B-%5Cfrac%7Bn%7D%7B2%7D%7D%5Cexp%5Cleft%28%5Cfrac+%7B-%5Clambda+X_s%7D%7B1%2B2%5Clambda%28t-s%29%7D%5Cright%29.+&bg=ffffff&fg=000000&s=0&c=20201002)

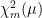

and
process.
be constant. Then,
is also a
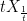


.


![\displaystyle \begin{aligned} {\mathbb E}[e^{-\lambda X_s - \mu X_t}] &=\left(1+2\mu(t-s)\right)^{-\frac n2}{\mathbb E}[e^{-(\lambda+\mu/(1+2\mu(t-s)))X_s}]\\ &=\left(1+2\mu(t-s)\right)^{-\frac n2}\left(1+2(\lambda+\mu/(1+2\mu(t-s)))s\right)^{-\frac n2}\\ &=\left(1+2\lambda s+2\mu t+4\lambda\mu(t-s)s\right)^{-\frac n2} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5Be%5E%7B-%5Clambda+X_s+-+%5Cmu+X_t%7D%5D+%26%3D%5Cleft%281%2B2%5Cmu%28t-s%29%5Cright%29%5E%7B-%5Cfrac+n2%7D%7B%5Cmathbb+E%7D%5Be%5E%7B-%28%5Clambda%2B%5Cmu%2F%281%2B2%5Cmu%28t-s%29%29%29X_s%7D%5D%5C%5C+%26%3D%5Cleft%281%2B2%5Cmu%28t-s%29%5Cright%29%5E%7B-%5Cfrac+n2%7D%5Cleft%281%2B2%28%5Clambda%2B%5Cmu%2F%281%2B2%5Cmu%28t-s%29%29%29s%5Cright%29%5E%7B-%5Cfrac+n2%7D%5C%5C+%26%3D%5Cleft%281%2B2%5Clambda+s%2B2%5Cmu+t%2B4%5Clambda%5Cmu%28t-s%29s%5Cright%29%5E%7B-%5Cfrac+n2%7D+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)

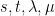

![\displaystyle {\mathbb E}[e^{-\lambda X_s - \mu X_t}]={\mathbb E}[e^{-\mu Y_t-\lambda Y_s}],](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Be%5E%7B-%5Clambda+X_s+-+%5Cmu+X_t%7D%5D%3D%7B%5Cmathbb+E%7D%5Be%5E%7B-%5Cmu+Y_t-%5Clambda+Y_s%7D%5D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
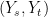


![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rl} \displaystyle{\mathbb P}(X_t=0\mid\mathcal{F}_s)&\displaystyle=\lim_{\lambda\rightarrow\infty}{\mathbb E}\left[e^{-\lambda X_t}\;\middle\vert\;\mathcal{F}_s\right]\smallskip\\ &\displaystyle=\begin{cases} 0,&\textrm{if }n>0,\\ \exp\left(-\frac{X_s}{2(t-s)}\right),&\textrm{if }n=0. \end{cases} \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brl%7D+%5Cdisplaystyle%7B%5Cmathbb+P%7D%28X_t%3D0%5Cmid%5Cmathcal%7BF%7D_s%29%26%5Cdisplaystyle%3D%5Clim_%7B%5Clambda%5Crightarrow%5Cinfty%7D%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7B-%5Clambda+X_t%7D%5C%3B%5Cmiddle%5Cvert%5C%3B%5Cmathcal%7BF%7D_s%5Cright%5D%5Csmallskip%5C%5C+%26%5Cdisplaystyle%3D%5Cbegin%7Bcases%7D+0%2C%26%5Ctextrm%7Bif+%7Dn%3E0%2C%5C%5C+%5Cexp%5Cleft%28-%5Cfrac%7BX_s%7D%7B2%28t-s%29%7D%5Cright%29%2C%26%5Ctextrm%7Bif+%7Dn%3D0.+%5Cend%7Bcases%7D+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)



![\displaystyle {\mathbb E}\left[\int_0^\infty1_{\{X_t=0\}}\,dt\right]=\int_0^\infty{\mathbb P}(X_t=0)\,dt=0.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Cleft%5B%5Cint_0%5E%5Cinfty1_%7B%5C%7BX_t%3D0%5C%7D%7D%5C%2Cdt%5Cright%5D%3D%5Cint_0%5E%5Cinfty%7B%5Cmathbb+P%7D%28X_t%3D0%29%5C%2Cdt%3D0.+&bg=ffffff&fg=000000&s=0&c=20201002)

process.
is a local martingale and
.

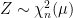
![{{\mathbb E}[e^{\lambda Z}]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5Be%5E%7B%5Clambda+Z%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)







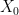
![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rl} \displaystyle{\mathbb E}[M_t^2-M_s^2\mid\mathcal{F}_s]&\displaystyle={\rm Var}(X_t\mid\mathcal{F}_s)\smallskip\\ &\displaystyle=2n(t-s)^2+4X_s(t-s). \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brl%7D+%5Cdisplaystyle%7B%5Cmathbb+E%7D%5BM_t%5E2-M_s%5E2%5Cmid%5Cmathcal%7BF%7D_s%5D%26%5Cdisplaystyle%3D%7B%5Crm+Var%7D%28X_t%5Cmid%5Cmathcal%7BF%7D_s%29%5Csmallskip%5C%5C+%26%5Cdisplaystyle%3D2n%28t-s%29%5E2%2B4X_s%28t-s%29.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rl} \displaystyle{\mathbb E}\left[\int_s^tX_u\,du\;\middle\vert\;\mathcal{F}_s\right]&\displaystyle=\int_s^t{\mathbb E}[X_u\mid\mathcal{F}_s]\,du\smallskip\\ &\displaystyle=\int_s^t(n(u-s)+X_s)\,du\smallskip\\ &\displaystyle=\frac{n}{2}(t-s)^2+X_s(t-s) \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brl%7D+%5Cdisplaystyle%7B%5Cmathbb+E%7D%5Cleft%5B%5Cint_s%5EtX_u%5C%2Cdu%5C%3B%5Cmiddle%5Cvert%5C%3B%5Cmathcal%7BF%7D_s%5Cright%5D%26%5Cdisplaystyle%3D%5Cint_s%5Et%7B%5Cmathbb+E%7D%5BX_u%5Cmid%5Cmathcal%7BF%7D_s%5D%5C%2Cdu%5Csmallskip%5C%5C+%26%5Cdisplaystyle%3D%5Cint_s%5Et%28n%28u-s%29%2BX_s%29%5C%2Cdu%5Csmallskip%5C%5C+%26%5Cdisplaystyle%3D%5Cfrac%7Bn%7D%7B2%7D%28t-s%29%5E2%2BX_s%28t-s%29+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)

![{[M]=4\int X_u\,du}](https://s0.wp.com/latex.php?latex=%7B%5BM%5D%3D4%5Cint+X_u%5C%2Cdu%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[X]=[M]}](https://s0.wp.com/latex.php?latex=%7B%5BX%5D%3D%5BM%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{[M]=4\int X_s\,ds}](https://s0.wp.com/latex.php?latex=%7B%5BM%5D%3D4%5Cint+X_s%5C%2Cds%7D&bg=ffffff&fg=000000&s=0&c=20201002)
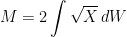

![\displaystyle [W]_t=\frac14\int_0^t1_{\{X\not=0\}}X^{-1}\,d[M] =\int_0^t1_{\{X_s\not=0\}}\,ds.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5BW%5D_t%3D%5Cfrac14%5Cint_0%5Et1_%7B%5C%7BX%5Cnot%3D0%5C%7D%7DX%5E%7B-1%7D%5C%2Cd%5BM%5D+%3D%5Cint_0%5Et1_%7B%5C%7BX_s%5Cnot%3D0%5C%7D%7D%5C%2Cds.+&bg=ffffff&fg=000000&s=0&c=20201002)

![{[X]=4\int X_s\,ds}](https://s0.wp.com/latex.php?latex=%7B%5BX%5D%3D4%5Cint+X_s%5C%2Cds%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[X]=4\int X_u\,du}](https://s0.wp.com/latex.php?latex=%7B%5BX%5D%3D4%5Cint+X_u%5C%2Cdu%7D&bg=ffffff&fg=000000&s=0&c=20201002)

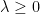
![\displaystyle {\mathbb E}[Ze^{-\lambda X_t}]={\mathbb E}[Ze^{-\lambda X_s}]+\lambda\int_s^t{\mathbb E}[Ze^{-\lambda X_u}\left(2\lambda X_u-n)\right]\,du.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5BZe%5E%7B-%5Clambda+X_t%7D%5D%3D%7B%5Cmathbb+E%7D%5BZe%5E%7B-%5Clambda+X_s%7D%5D%2B%5Clambda%5Cint_s%5Et%7B%5Cmathbb+E%7D%5BZe%5E%7B-%5Clambda+X_u%7D%5Cleft%282%5Clambda+X_u-n%29%5Cright%5D%5C%2Cdu.+&bg=ffffff&fg=000000&s=0&c=20201002)
![{\phi(t,\lambda)={\mathbb E}[Ze^{-\lambda X_t}]}](https://s0.wp.com/latex.php?latex=%7B%5Cphi%28t%2C%5Clambda%29%3D%7B%5Cmathbb+E%7D%5BZe%5E%7B-%5Clambda+X_t%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{\partial\phi/\partial\lambda=-{\mathbb E}[Ze^{-\lambda X_t}X_t]}](https://s0.wp.com/latex.php?latex=%7B%5Cpartial%5Cphi%2F%5Cpartial%5Clambda%3D-%7B%5Cmathbb+E%7D%5BZe%5E%7B-%5Clambda+X_t%7DX_t%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
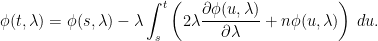


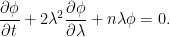









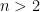

and make the following substitution.
be the first time at which
so that
is the process stopped when it first hits zero, and set
with
then
satisfies
with a, b, c as in (8) satisfies






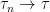
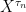
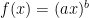
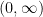
![{[0,\tau_n]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C%5Ctau_n%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rl} \displaystyle dY_t&\displaystyle=a^bbX_t^{b-1}\left(2\sqrt{X_t}\,dW_t+n\,dt\right)+\frac12a^bb(b-1)X_t^{b-2}\,d[X]_t\smallskip\\ &\displaystyle=2a^bbX_t^{b-1/2}\,dW_t+2a^bb\left(n/2+b-1\right)X_t^{b-1}\,dt. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brl%7D+%5Cdisplaystyle+dY_t%26%5Cdisplaystyle%3Da%5EbbX_t%5E%7Bb-1%7D%5Cleft%282%5Csqrt%7BX_t%7D%5C%2CdW_t%2Bn%5C%2Cdt%5Cright%29%2B%5Cfrac12a%5Ebb%28b-1%29X_t%5E%7Bb-2%7D%5C%2Cd%5BX%5D_t%5Csmallskip%5C%5C+%26%5Cdisplaystyle%3D2a%5EbbX_t%5E%7Bb-1%2F2%7D%5C%2CdW_t%2B2a%5Ebb%5Cleft%28n%2F2%2Bb-1%5Cright%29X_t%5E%7Bb-1%7D%5C%2Cdt.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
![{d[X]=4X\,dt}](https://s0.wp.com/latex.php?latex=%7Bd%5BX%5D%3D4X%5C%2Cdt%7D&bg=ffffff&fg=000000&s=0&c=20201002)
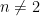


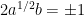


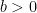
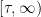
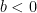
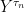
![\displaystyle {\mathbb E}[\liminf_{n\rightarrow\infty}Y_{\tau_n}\mid\mathcal{F}_0]\le\liminf_{n\rightarrow\infty}{\mathbb E}[Y_{\tau_n}\mid\mathcal{F}_0]\le Y_0.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5B%5Climinf_%7Bn%5Crightarrow%5Cinfty%7DY_%7B%5Ctau_n%7D%5Cmid%5Cmathcal%7BF%7D_0%5D%5Cle%5Climinf_%7Bn%5Crightarrow%5Cinfty%7D%7B%5Cmathbb+E%7D%5BY_%7B%5Ctau_n%7D%5Cmid%5Cmathcal%7BF%7D_0%5D%5Cle+Y_0.+&bg=ffffff&fg=000000&s=0&c=20201002)
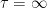


![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rl} \displaystyle dY_t&\displaystyle=\frac{1}{2X_t}\left(2\sqrt{X_t}\,dW_t+2\,dt\right)-\frac{1}{4X_t^2}\,d[X]_t\smallskip\\ &\displaystyle=X_t^{-1/2}\,dW_t\smallskip\\ &\displaystyle=e^{-Y_t}\,dW_t. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brl%7D+%5Cdisplaystyle+dY_t%26%5Cdisplaystyle%3D%5Cfrac%7B1%7D%7B2X_t%7D%5Cleft%282%5Csqrt%7BX_t%7D%5C%2CdW_t%2B2%5C%2Cdt%5Cright%29-%5Cfrac%7B1%7D%7B4X_t%5E2%7D%5C%2Cd%5BX%5D_t%5Csmallskip%5C%5C+%26%5Cdisplaystyle%3DX_t%5E%7B-1%2F2%7D%5C%2CdW_t%5Csmallskip%5C%5C+%26%5Cdisplaystyle%3De%5E%7B-Y_t%7D%5C%2CdW_t.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)

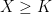
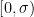
![\displaystyle {\mathbb E}[\limsup_{n\rightarrow\infty}Y_{\sigma\wedge\tau_n}\mid\mathcal{F}_0]\ge\limsup_{n\rightarrow\infty}{\mathbb E}[Y_{\sigma\wedge\tau_n}\mid\mathcal{F}_0]\ge Y_0.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5B%5Climsup_%7Bn%5Crightarrow%5Cinfty%7DY_%7B%5Csigma%5Cwedge%5Ctau_n%7D%5Cmid%5Cmathcal%7BF%7D_0%5D%5Cge%5Climsup_%7Bn%5Crightarrow%5Cinfty%7D%7B%5Cmathbb+E%7D%5BY_%7B%5Csigma%5Cwedge%5Ctau_n%7D%5Cmid%5Cmathcal%7BF%7D_0%5D%5Cge+Y_0.+&bg=ffffff&fg=000000&s=0&c=20201002)


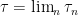


then X hits 0 at some time, and remains there.
.
,
as
.

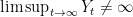






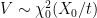


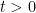










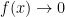

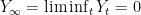





then B is recurrent.
then
as
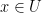
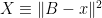
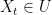
, let
be the transition probability on
,
has moment generating function given by
is a Feller transition function. Furthermore, any Markov process with this transition function has a continuous modification, which is then a

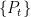
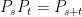
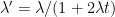


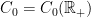

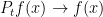


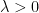





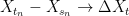
![{[0,t]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2Ct%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
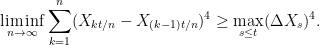

![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rl} &\displaystyle{\mathbb E}\left[\exp\left(-\lambda(X_t-X_s)\right)\;\middle\vert\;\mathcal{F}_0\right]\smallskip\\ &\displaystyle=\left(1+2\lambda(t-s)\right)^{-\frac{n}{2}}{\mathbb E}\left[\exp\left(\frac{-\lambda X_s}{1+2\lambda(t-s)}+\lambda X_s\right)\;\middle\vert\;\mathcal{F}_0\right]\smallskip\\ &\displaystyle=\left(1+2\lambda(t-s)\right)^{-\frac{n}{2}}\left(1-2\lambda^\prime s\right)^{-\frac{n}{2}}\exp\left(\frac{\lambda^\prime X_0}{1-2\lambda^\prime s}\right). \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brl%7D+%26%5Cdisplaystyle%7B%5Cmathbb+E%7D%5Cleft%5B%5Cexp%5Cleft%28-%5Clambda%28X_t-X_s%29%5Cright%29%5C%3B%5Cmiddle%5Cvert%5C%3B%5Cmathcal%7BF%7D_0%5Cright%5D%5Csmallskip%5C%5C+%26%5Cdisplaystyle%3D%5Cleft%281%2B2%5Clambda%28t-s%29%5Cright%29%5E%7B-%5Cfrac%7Bn%7D%7B2%7D%7D%7B%5Cmathbb+E%7D%5Cleft%5B%5Cexp%5Cleft%28%5Cfrac%7B-%5Clambda+X_s%7D%7B1%2B2%5Clambda%28t-s%29%7D%2B%5Clambda+X_s%5Cright%29%5C%3B%5Cmiddle%5Cvert%5C%3B%5Cmathcal%7BF%7D_0%5Cright%5D%5Csmallskip%5C%5C+%26%5Cdisplaystyle%3D%5Cleft%281%2B2%5Clambda%28t-s%29%5Cright%29%5E%7B-%5Cfrac%7Bn%7D%7B2%7D%7D%5Cleft%281-2%5Clambda%5E%5Cprime+s%5Cright%29%5E%7B-%5Cfrac%7Bn%7D%7B2%7D%7D%5Cexp%5Cleft%28%5Cfrac%7B%5Clambda%5E%5Cprime+X_0%7D%7B1-2%5Clambda%5E%5Cprime+s%7D%5Cright%29.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)




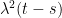
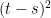
![\displaystyle {\mathbb E}[(X_t-X_s)^4\mid\mathcal{F}_0]=O((t-s)^2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5B%28X_t-X_s%29%5E4%5Cmid%5Cmathcal%7BF%7D_0%5D%3DO%28%28t-s%29%5E2%29+&bg=ffffff&fg=000000&s=0&c=20201002)


for
(in the uniform norm).


![{g\colon[0,1]\rightarrow{\mathbb R}}](https://s0.wp.com/latex.php?latex=%7Bg%5Ccolon%5B0%2C1%5D%5Crightarrow%7B%5Cmathbb+R%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)









Dear George,
how would you (efficiently) simulate a BES^2_n process in such a manner that the process does stay positive (for non integer dimension n, indeed).
thanks again for these great posts! in equation (8)
in equation (8)
Best
PS: tiny typo in the definition of
Hi. I can give a quick answer now, but I’m not going to have much time to go into details for a few days.
1) You can sample a Bessel process exactly at a fixed sequence of times, by sampling from the skew chi-square distributions. As I explained near the top of the post, a distribution can be written as
distribution can be written as  where, Y is
where, Y is  , Zi are standard normal and N is Poisson of rate
, Zi are standard normal and N is Poisson of rate 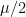 . Equivalently,
. Equivalently,  conditional on N. See the paper Exact Simulation of Bessel Diffusions which includes this and other related methods (actually, I found that paper while searching for another one which I remember from several years ago but forget the title. I’ll come back with the link if I remember…)
conditional on N. See the paper Exact Simulation of Bessel Diffusions which includes this and other related methods (actually, I found that paper while searching for another one which I remember from several years ago but forget the title. I’ll come back with the link if I remember…)
2) You can numerically simulate the SDE (3), which only gives an approximate solution, but will likely be much faster if you want to sample it at a dense set of times. It can be done by an Euler scheme. However, if the process is close to zero then the simulation could jump below zero. Then you would have to max with zero, which would bias the distribution causing the drift to increase as the process gets close to zero. This would cause the approximation to converge very slowly in the number of time steps used when n is small. A better way would be to modify the Euler scheme so that you are sampling positive numbers from the start while matching all the moments of dX up to O(dtk), some appropriate k. For example, a trinomial distribution could be used to match all moments up to O(dt3), leading to an O(dt2) error term overall.
and, what’s the typo?
https://math.stackexchange.com/questions/4876768/probability-of-a-2d-brownian-motion-exiting-a-circle-of-radius-r-before-time-t
Please help me solve this.
thank you for these very interesting answer, and the reference !
I remember a discussion where someone advised me to take the scale function of a diffusion
of a diffusion 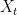 and to try to simulate
and to try to simulate 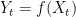 : this would often eliminate the problem of staying positive (boundary effect), say, and would often be much more precise: I do not remember really well the motivation for that, though. From a practical point of view, why
: this would often eliminate the problem of staying positive (boundary effect), say, and would often be much more precise: I do not remember really well the motivation for that, though. From a practical point of view, why 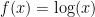 would be worse than taking the scale function in this problem, for example. In one case
would be worse than taking the scale function in this problem, for example. In one case 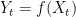 is obviously a martingale, but I do not understand why this is better. Could you shed some light on this issue ?
is obviously a martingale, but I do not understand why this is better. Could you shed some light on this issue ?
Thank you for this fantastic blog! above eq 8, no ?
above eq 8, no ?
PS: tiny typo in the definition of
I’m not sure why applying the scale function should eliminate any boundary effect. If you have a squared Bessel process of dimension n < 2, then the scale function is a positive power of X (Lemma 5 above). So it still has a boundary at zero. Also, if n=2, then the scale function is log(x). This does remove the boundary, but the SDE for Y=log(X) is dY = e-Y dW which has exponentially growing coefficients as Y goes negative. That does not look very promising from the point of view of obtaining accurate simulations.
In general, whether or not transforming by the scale function improves the simulations must depend on what particular SDE you start with and what simulation method you are using.
Another point: if f is the scale function then Y=f(X) does not have to be a martingale. In fact, for squared Bessel processes of dimension n > 0, this is never the case. For n < 2 it has a reflecting boundary, so only becomes a martingale if you stop the process at the boundary. For n>=2 the boundary is never attained but, still, Y is not a martingale. It’s just a local martingale.
[Apols. for not responding sooner. Not had chance to log on to my machine the last week].
Also, thanks for mentioning that the transformation I use in Lemma 5 is called the scale function. I updated the text to mention this.
Still don’t see the typo. I have Y = (aXτ)b, which is what was intended. Maybe you are thinking that a should be outside the parentheses? But, that’s not true with my definition of a.
Thank you for all these very interesting comments (and apologize for this very late answer): seems like I have been a little bit optimistic with this “scale function” transformation!
Btw, numerical simulations of SDEs seem to be a very broad area: do you plan on writing on this ?
I don’t have any immediate plans to post about numerical simulations. Maybe, at some point. I’ll bear your suggestion in mind though.
Hi George,
Great blog btw, really helpful and concise in clarifying many important concepts of stochastic processes. Just wanted to point out a small typo in Theorem 4 (3) -> (2): I think you want .
.
Thanks! I eventually fixed this typo!
https://math.stackexchange.com/questions/4876768/probability-of-a-2d-brownian-motion-exiting-a-circle-of-radius-r-before-time-t