
In these notes, the approach taken to stochastic calculus revolves around stochastic integration and the theory of semimartingales. An alternative starting point would be to consider Markov processes. Although I do not take the second approach, all of the special processes considered in the current section are Markov, so it seems like a good idea to introduce the basic definitions and properties now. In fact, all of the special processes considered (Brownian motion, Poisson processes, Lévy processes, Bessel processes) satisfy the much stronger property of being Feller processes, which I will define in the next post.
Intuitively speaking, a process X is Markov if, given its whole past up until some time s, the future behaviour depends only its state at time s. To make this precise, let us suppose that X takes values in a measurable space 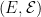
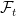

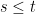



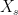
![\displaystyle {\mathbb E}\left[f(X_t)\mid\mathcal{F}_s\right]={\mathbb E}\left[f(X_t)\mid X_s\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Cleft%5Bf%28X_t%29%5Cmid%5Cmathcal%7BF%7D_s%5Cright%5D%3D%7B%5Cmathbb+E%7D%5Cleft%5Bf%28X_t%29%5Cmid+X_s%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002) |
(1) |
(almost surely). More generally, this idea makes sense with respect to any filtered probability space 

Continuous-time Markov processes are usually defined in terms of transition functions. These specify how the distribution of 
Definition 1 A (transition) kernel N on a measurable space
such that
- for each
, the map
is a measure.
- for each
, the map
is measurable.
If, furthermore,
for all
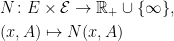
A transition probability, then, associates to each

Given any such kernel N and 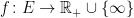


Then, 

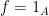

Two kernels M and N can be combined by first applying N followed by M to get the kernel MN,
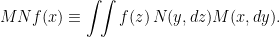
Suppose that M, N are transition probabilities describing how a process X goes from its state at time s to its conditional distribution at time t and from its state at time t to a distribution at time u respectively, for 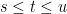
![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rl} \displaystyle{\mathbb E}[f(X_u)\mid\mathcal{F}_s]&\displaystyle={\mathbb E}\left[{\mathbb E}[f(X_u)\mid\mathcal{F}_t]\;\middle\vert\;\mathcal{F}_s\right]\smallskip\\ &\displaystyle={\mathbb E}\left[Nf(X_t)\mid\mathcal{F}_s\right]=MNf(X_s). \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brl%7D+%5Cdisplaystyle%7B%5Cmathbb+E%7D%5Bf%28X_u%29%5Cmid%5Cmathcal%7BF%7D_s%5D%26%5Cdisplaystyle%3D%7B%5Cmathbb+E%7D%5Cleft%5B%7B%5Cmathbb+E%7D%5Bf%28X_u%29%5Cmid%5Cmathcal%7BF%7D_t%5D%5C%3B%5Cmiddle%5Cvert%5C%3B%5Cmathcal%7BF%7D_s%5Cright%5D%5Csmallskip%5C%5C+%26%5Cdisplaystyle%3D%7B%5Cmathbb+E%7D%5Cleft%5BNf%28X_t%29%5Cmid%5Cmathcal%7BF%7D_s%5Cright%5D%3DMNf%28X_s%29.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
A Markov process is defined by a collection of transition probabilities 



Definition 2 A homogeneous transition function on
of transition probabilities on
for all
.
A process X is Markov with transition function
, and with respect to a filtered probability space
if it is adapted and
(almost surely), for all times
.
![\displaystyle {\mathbb E}\left[f(X_t)\mid\mathcal{F}_s\right]=P_{t-s}f(X_s)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Cleft%5Bf%28X_t%29%5Cmid%5Cmathcal%7BF%7D_s%5Cright%5D%3DP_%7Bt-s%7Df%28X_s%29+&bg=ffffff&fg=000000&s=0&c=20201002)
The identity 
As an example, standard Brownian motion, B, has the defining property that 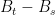
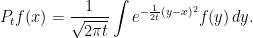
In practice, other than for a small number of special processes, it is not possible to write down transition functions explicitly. Instead, the processes are defined as solutions to stochastic differential equations, or the transition function is defined via an infinitesimal generator.
The distribution of a Markov process is determined uniquely by its transition function and initial distribution.
Lemma 3 Suppose that X is a Markov process on
has distribution
. Then, for any times
and bounded measurable function
,
(2)
![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rl} &\displaystyle{\mathbb E}[f(X_{t_0},\ldots,X_{t_n})]=\smallskip\\ &\displaystyle\quad\int\!\!\int\!\cdots\!\int f(x_0,\ldots,x_n)\,P_{t_n-t_{n-1}}(x_{n-1},dx_n)\cdots P_{t_1-t_0}(x_0,dx_1)\mu(dx_0). \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brl%7D+%26%5Cdisplaystyle%7B%5Cmathbb+E%7D%5Bf%28X_%7Bt_0%7D%2C%5Cldots%2CX_%7Bt_n%7D%29%5D%3D%5Csmallskip%5C%5C+%26%5Cdisplaystyle%5Cquad%5Cint%5C%21%5C%21%5Cint%5C%21%5Ccdots%5C%21%5Cint+f%28x_0%2C%5Cldots%2Cx_n%29%5C%2CP_%7Bt_n-t_%7Bn-1%7D%7D%28x_%7Bn-1%7D%2Cdx_n%29%5Ccdots+P_%7Bt_1-t_0%7D%28x_0%2Cdx_1%29%5Cmu%28dx_0%29.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: Let us start by showing that for 
![\displaystyle {\mathbb E}[f(X_{t_0},\ldots,X_{t_n})\mid\mathcal{F}_{t_{n-1}}] = g(X_{t_0},\ldots,X_{t_{n-1}})](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Bf%28X_%7Bt_0%7D%2C%5Cldots%2CX_%7Bt_n%7D%29%5Cmid%5Cmathcal%7BF%7D_%7Bt_%7Bn-1%7D%7D%5D+%3D+g%28X_%7Bt_0%7D%2C%5Cldots%2CX_%7Bt_%7Bn-1%7D%7D%29+&bg=ffffff&fg=000000&s=0&c=20201002) |
(3) |
where 

In the case where 


and (3) follows from the Markov property ![{{\mathbb E}[v(X_{t_n})\mid\mathcal{F}_{t_{n-1}}]=P_{t_n-t_{n-1}}v(X_{t_{n-1}})}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5Bv%28X_%7Bt_n%7D%29%5Cmid%5Cmathcal%7BF%7D_%7Bt_%7Bn-1%7D%7D%5D%3DP_%7Bt_n-t_%7Bn-1%7D%7Dv%28X_%7Bt_%7Bn-1%7D%7D%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The proof of (2) follows from an induction on n. For the case 
![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rl} &\displaystyle{\mathbb E}[f(X_{t_0},\ldots,X_{t_n})]={\mathbb E}[g(X_{t_0},\ldots,X_{t_{n-1}})]\smallskip\\ =&\displaystyle \int\!\!\int\!\cdots\!\int g(x_0,\ldots,x_{n-1})\,P_{t_{n-1}-t_{n-2}}(x_{n-2},dx_{n-1})\cdots P_{t_1-t_0}(x_0,dx_1)\mu(dx_0). \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brl%7D+%26%5Cdisplaystyle%7B%5Cmathbb+E%7D%5Bf%28X_%7Bt_0%7D%2C%5Cldots%2CX_%7Bt_n%7D%29%5D%3D%7B%5Cmathbb+E%7D%5Bg%28X_%7Bt_0%7D%2C%5Cldots%2CX_%7Bt_%7Bn-1%7D%7D%29%5D%5Csmallskip%5C%5C+%3D%26%5Cdisplaystyle+%5Cint%5C%21%5C%21%5Cint%5C%21%5Ccdots%5C%21%5Cint+g%28x_0%2C%5Cldots%2Cx_%7Bn-1%7D%29%5C%2CP_%7Bt_%7Bn-1%7D-t_%7Bn-2%7D%7D%28x_%7Bn-2%7D%2Cdx_%7Bn-1%7D%29%5Ccdots+P_%7Bt_1-t_0%7D%28x_0%2Cdx_1%29%5Cmu%28dx_0%29.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Substituting in the expression for g gives the result. ⬜
The finite distributions of a process X taking values in E are defined to be the distributions, in 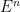
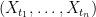

Corollary 4 Suppose that X and Y are Markov processes, each with the same transition function
have the same distribution
Then, X and Y have the same finite distributions.
It is important to know that Markov processes do indeed exist for any given transition function and initial distribution. This is a consequence of the Kolmogorov extension theorem.
Theorem 5 Let
be the space of functions
. Denote its coordinate process by X,
Also, let
be the sigma-algebra generated by
and, for each
, let
be the sigma-algebra generated by
is a filtration on the measurable space
with respect to which X is adapted.
Then, for every transition function
on

The superscripts `0′ just denote the fact that we are using the uncompleted sigma-algebras. Once the probability measure has been defined, it is standard practice to complete the filtration, which does not affect the Markov property.
Proof: For any finite subset 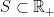
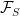
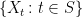
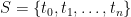
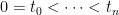
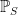
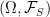
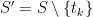


shows that, if 
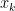
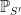


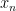

By successively removing elements from S, this shows that 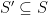
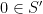

We have now shown the existence and uniqueness of the probability measure 
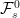

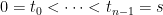

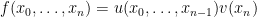
![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rl} \displaystyle{\mathbb E}[Zv(X_t)] &\displaystyle=\int u(x_0,\ldots,x_{n-1})v(x_n)P_{t_n-t_{n-1}}(x_{n-1},dx_n)\cdots\mu(dx_0)\smallskip\\ &\displaystyle=E[ZP_{t_n-t_{n-1}}v(X_{t_n})]={\mathbb E}[ZP_{t-s}v(X_t)]. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brl%7D+%5Cdisplaystyle%7B%5Cmathbb+E%7D%5BZv%28X_t%29%5D+%26%5Cdisplaystyle%3D%5Cint+u%28x_0%2C%5Cldots%2Cx_%7Bn-1%7D%29v%28x_n%29P_%7Bt_n-t_%7Bn-1%7D%7D%28x_%7Bn-1%7D%2Cdx_n%29%5Ccdots%5Cmu%28dx_0%29%5Csmallskip%5C%5C+%26%5Cdisplaystyle%3DE%5BZP_%7Bt_n-t_%7Bn-1%7D%7Dv%28X_%7Bt_n%7D%29%5D%3D%7B%5Cmathbb+E%7D%5BZP_%7Bt-s%7Dv%28X_t%29%5D.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
By the monotone class theorem, this extends to all bounded and ![{{\mathbb E}[v(X_t)\mid\mathcal{F}^0_s]=P_{t-s}v(X_s)}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5Bv%28X_t%29%5Cmid%5Cmathcal%7BF%7D%5E0_s%5D%3DP_%7Bt-s%7Dv%28X_s%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The unique measure with respect to which X is Markov with the given transition function and initial distribution is denoted by 
![{{\mathbb E}_\mu[\cdot]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D_%5Cmu%5B%5Ccdot%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
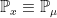
![{{\mathbb E}_x[\cdot]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D_x%5B%5Ccdot%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{x\mapsto{\mathbb E}_x[Z]}](https://s0.wp.com/latex.php?latex=%7Bx%5Cmapsto%7B%5Cmathbb+E%7D_x%5BZ%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle {\mathbb E}_\mu[Z]=\int{\mathbb E}_x[Z]\,\mu(dx)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D_%5Cmu%5BZ%5D%3D%5Cint%7B%5Cmathbb+E%7D_x%5BZ%5D%5C%2C%5Cmu%28dx%29+&bg=ffffff&fg=000000&s=0&c=20201002)
for an arbitrary probability measure
It is sometimes useful to generalize Definition 2 to sub-Markovian transition functions. These are sets of kernels 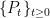
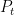




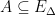

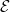
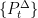
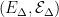
 |
(4) |
It can be checked that the identity 

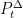
![{[s,t]}](https://s0.wp.com/latex.php?latex=%7B%5Bs%2Ct%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
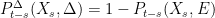

Why the function f need to be non-negative in the transition kernel case, and it is bounded in the transition prob case?
For general transition kernels, integrals with respect to arbitrary measurable functions are not well defined. You need to restrict either to integrable or to nonnegative functions. For transition probabilities, bounded functions are integrable, so can be used without imposing an additional integrability condition.
It seems to me that there is a little mistake in the proof of lemma 3 in the case where f is just a product of u and v. Why depends P_t_n,t_n-1 only of one variable?
I did mix up u with v in a couple of places, so I fixed this. I’m not sure if this helps with your question, but it is looking ok to me now.
Yeah, i forgot that you only consider only the space and time homogenous case. Can you maybe add a few words which property the functions f must have in the defining property of a markov process and why (or if) it is eqivalent to the equation![P[X_t\in A|\mathcal{F}_t]=P[X_t\in A|X_s]](https://s0.wp.com/latex.php?latex=P%5BX_t%5Cin+A%7C%5Cmathcal%7BF%7D_t%5D%3DP%5BX_t%5Cin+A%7CX_s%5D&bg=ffffff&fg=000000&s=0&c=20201002) (the transition kernel exist if the state space is Borel)
(the transition kernel exist if the state space is Borel)
Skip the first sentence of my previous comment.
I’ll have a look through this post again when I have some time and maybe clear up the points you mention.
Does every Markov process (defined by Eq(1)) have a transition function? I understood the converse is true (by Theorem 5). But can we construct a transition function from a given Markov process (defined by Eq(1))?
I have the same question. In particular, I am aware of the fact that if the process takes values in a Borel-standard space (e.g. a Polish space) then there exists a family of kernels ${P_{s,t}}$ that satisfies $mathbb{E}(f(X_t)|X_s)=P_{s,t}f(X_s)$ for all bounded measurable $f$ (this is a well-known theorem). However, I don’t see why this family of kernels should also satisfy the Chapman-Kolmogorov equations $P_{t,u}circ P_{s,t}=P_{s,u}$. I don’t even know whether it is true or not. Any comment on that?
Of course it is easy to see that for all $s<t<u$ and all measurable $Asubset E$ $(P_{t,u}circ P_{s,t})(x_s,A)=P_{s,u}(x_s,A)$ is true for ${X_s}_*mathbb{P}$-a.e. $x_s$ in $E$, but the Chapman-Kolmogorov equations require the equality to hold for ALL $x_sin E$.