
The distribution of a standard Brownian motion X at a positive time t is, by definition, centered normal with variance t. What can we say about its maximum value up until the time? This is X∗t = sups ≤ tXs, and is clearly nonnegative and at least as big as Xt. To be more precise, consider the probability that the maximum is greater than a fixed positive value a. Such problems will be familiar to anyone who has looked at pricing of financial derivatives such as barrier options, where the payoff of a trade depends on whether the maximum or minimum of an asset price has crossed a specified barrier level.
This can be computed with the aid of a symmetry argument commonly referred to as the reflection principle. The idea is that, if we reflect the Brownian motion when it first hits a level, then the resulting process is also a Brownian motion. The first time at which X hits level a is τ = inf{t ≥ 0: Xt ≥ a}, which is a stopping time. Reflecting the process about this level at all times after τ gives a new process

 |
(1) |
Before time τ, both processes are the same and, after this, X and Xr are reflections of each other, as shown in figure 1. The fact which enables us to easily prove many useful results about the maximum values of Brownian motion is that the reflected process is also a standard Brownian motion. This important result is a consequence of the strong Markov property, which states that the process started from time τ given by Ys = Xτ + s – Xτ is a standard Brownian motion independently of ℱτ. If we are to replace X by Xr, this replaces Y by –Y which, by symmetry, remains a standard Brownian motion. As our original process X can be reconstructed by joining together the path of Xt = Xrt over t ≤ τ and Yt - τ + Xτ over t ≥ τ, its distribution remains unchanged by the reflection.
In the case under consideration, where τ is the first time at which X hits a, we have Xτ = a so that equation (1) says that the reflected process is Xrt = 2a – Xt at times t ≥ τ.
Now for the trick — whether or not the pathwise maximum X∗t reaches level a can be read off from the terminal values of the processes Xt and Xrt. The event X∗t ≥ a > Xt is identical to Xrt > a giving,
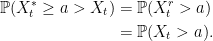 |
The second equality here is using the reflection principle, so that Xrt and Xt have the same distribution. On the other hand, on the event Xt ≥ a we necessarily have X∗t ≥ a,
 |
Using addition of probabilities,
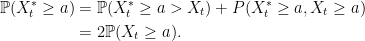 |
This answers our original question of the distribution of X∗t. Its probability density will be twice that of Xt over x > 0 which, being normal with variance t, is
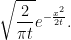 |
Conveniently, by symmetry of the normal distribution, the same holds for the absolute value |Xt| giving the simple result that it has the same distribution as X∗t.
Lemma 1 If X is standard Brownian motion, then X∗t has the same distribution as |Xt| for each time t ≥ 0.
In fact, we do not have to use the reflection principle in the form described above. While it is a powerful technique, it is useful to know of different (but very similar) approaches.
- Use the reflection principle, so that X∗t > a if either Xt > a or Xrt > a.
- Condition on the first time τ at which X hits a. If this is before time t then, by symmetry of the normal distribution, there will be a 50% chance of ending up above a at time t. So, ℙ(Xt > a) = ℙ(X∗t > a)/2.
- Define a function f: ℝ → ℝ such that f(x) = 1 for x < a and which is antisymmetric about a. That is, f(x) = -1 for x > a. Conditioning on the first time τ at which X hits a, this antisymmetry ensures that
so,
(2) As f(Xt) = 1 when Xt < a we obtain
This is easily rearranged to obtain the same result as above for the distribution of X∗t.
![\displaystyle {\mathbb E}[1_{\{X^*_t\ge a\}}f(X_t)]={\mathbb E}[1_{\{\tau < t\}}f(X_t)]=0.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5B1_%7B%5C%7BX%5E%2A_t%5Cge+a%5C%7D%7Df%28X_t%29%5D%3D%7B%5Cmathbb+E%7D%5B1_%7B%5C%7B%5Ctau+%3C+t%5C%7D%7Df%28X_t%29%5D%3D0.+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle {\mathbb E}[1_{\{X^*_t < a\}}f(X_t)]={\mathbb E}[f(X_t)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5B1_%7B%5C%7BX%5E%2A_t+%3C+a%5C%7D%7Df%28X_t%29%5D%3D%7B%5Cmathbb+E%7D%5Bf%28X_t%29%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \begin{aligned} {\mathbb P}(X^*_t < a)&={\mathbb E}[1_{\{X^*_t < a\}}f(X_t)]={\mathbb E}[f(X_t)]\\ &={\mathbb P}(X_t < a) - {\mathbb P}(X_t > a). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+P%7D%28X%5E%2A_t+%3C+a%29%26%3D%7B%5Cmathbb+E%7D%5B1_%7B%5C%7BX%5E%2A_t+%3C+a%5C%7D%7Df%28X_t%29%5D%3D%7B%5Cmathbb+E%7D%5Bf%28X_t%29%5D%5C%5C+%26%3D%7B%5Cmathbb+P%7D%28X_t+%3C+a%29+-+%7B%5Cmathbb+P%7D%28X_t+%3E+a%29.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
While the third approach looks a little more involved at first glance, it can be very useful when we want to do something more complicated such as simultaneously consider the maximum and minimum of the process, where we would otherwise have to consider all the different ways in which the process can hit upper and lower barrier in different orders.
Joint distribution of the maximum and terminal value
The reflection principle can be taken further to compute the joint distribution of the maximum X∗t and terminal values Xt of a Brownian motion. Consider the possibility that X increases to level a before dropping back below level b < a at time t. Using the notation introduced above, this is exactly the same as the reflected process Xr being above 2a – b at time t,
 |
Combined with the fact that X∗t ≥ Xt, this is sufficient to completely determine their joint distribution. However, let us generalize this a bit to look at the expectation of an arbitrary function of the terminal value of X.
If f: ℝ → ℝ is any measurable function such that f(Xt) has finite expectation, we can use the equivalence between X∗t > a and Xt > a or Xrt > a to obtain,
![\displaystyle {\mathbb E}[1_{\{X^*_t > a\}}f(X_t)]={\mathbb E}[1_{\{X_t > a\}}f(X_t)+1_{\{X^r_t > a\}}f(X_t))]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5B1_%7B%5C%7BX%5E%2A_t+%3E+a%5C%7D%7Df%28X_t%29%5D%3D%7B%5Cmathbb+E%7D%5B1_%7B%5C%7BX_t+%3E+a%5C%7D%7Df%28X_t%29%2B1_%7B%5C%7BX%5Er_t+%3E+a%5C%7D%7Df%28X_t%29%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002) |
Using the fact that Xt = 2a – Xrt whenever Xrt > a, and that X and Xr have the same distribution, we have proven the following result.
Theorem 2 If X is a standard Brownian motion and f: ℝ → ℝ is measurable such that f(Xt) has finite expectation, then
(3)
![\displaystyle {\mathbb E}[1_{\{X^*_t > a\}}f(X_t)]={\mathbb E}[1_{\{X_t > a\}}(f(X_t)+f(2a-X_t))].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5B1_%7B%5C%7BX%5E%2A_t+%3E+a%5C%7D%7Df%28X_t%29%5D%3D%7B%5Cmathbb+E%7D%5B1_%7B%5C%7BX_t+%3E+a%5C%7D%7D%28f%28X_t%29%2Bf%282a-X_t%29%29%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
As explained above, there are alternative approaches which do not involve the reflected process Xr. Instead, we can reflect the function f to obtain a new function g: ℝ → ℝ which is antisymmetric about a.
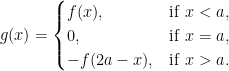 |
Since g(Xt) = f(Xt) whenever X∗t < a, and antisymmetry about a ensures that identity (2) holds with g in place of f,
![\displaystyle \begin{aligned} {\mathbb E}[1_{\{X^*_t < a\}}f(X_t)]&={\mathbb E}[1_{\{X^*_t < a\}}g(X_t)]\\ &={\mathbb E}[g(X_t)]\\ &={\mathbb E}[1_{\{X_t < a\}}f(X_t) - 1_{\{X_t > a\}}f(2a-X_t)] \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5B1_%7B%5C%7BX%5E%2A_t+%3C+a%5C%7D%7Df%28X_t%29%5D%26%3D%7B%5Cmathbb+E%7D%5B1_%7B%5C%7BX%5E%2A_t+%3C+a%5C%7D%7Dg%28X_t%29%5D%5C%5C+%26%3D%7B%5Cmathbb+E%7D%5Bg%28X_t%29%5D%5C%5C+%26%3D%7B%5Cmathbb+E%7D%5B1_%7B%5C%7BX_t+%3C+a%5C%7D%7Df%28X_t%29+-+1_%7B%5C%7BX_t+%3E+a%5C%7D%7Df%282a-X_t%29%5D+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
It is straightforward to rearrange this to obtain (3).
As X∗ ≥ X, it is sufficient to apply (3) for the special case where f(x) = 0 on x > a, in which case it reduces to
![\displaystyle \begin{aligned} {\mathbb E}[1_{\{X^*_t > a\}}f(X_t)] &={\mathbb E}[f(2a-X_t)]\\ &={\mathbb E}[f(2a+X_t)]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5B1_%7B%5C%7BX%5E%2A_t+%3E+a%5C%7D%7Df%28X_t%29%5D+%26%3D%7B%5Cmathbb+E%7D%5Bf%282a-X_t%29%5D%5C%5C+%26%3D%7B%5Cmathbb+E%7D%5Bf%282a%2BX_t%29%5D.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
The final equality here is just using symmetry of the normal distribution. So, restricting to the event X∗t > a has the same effect on the distribution of Xt as shifting it by 2a. At least, it does on the event {Xt ≤ a}. However, taking the expectation with respect to a shifted normal is the same as multiplying the integrand by an exponential term,
![\displaystyle {\mathbb E}[f(2a+X_t)]={\mathbb E}[e^{2at^{-1}(X_t-a)}f(X_t)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Bf%282a%2BX_t%29%5D%3D%7B%5Cmathbb+E%7D%5Be%5E%7B2at%5E%7B-1%7D%28X_t-a%29%7Df%28X_t%29%5D.+&bg=ffffff&fg=000000&s=0&c=20201002) |
This can be determined by writing out the integrals with respect to the normal density and checking that they agree. Up to the constant normalizing factor, this is
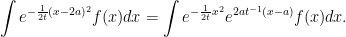 |
Alternatively, a standard change of measure formula for the normal distribution can be used.
We have evaluated the probability that X∗t > a conditional on the value of Xt.
Theorem 3 Let X be a standard Brownian motion and t > 0 be a positive time. Then, for a > 0,
whenever Xt ≤ a.

As a special case, this directly gives the distribution of the maximum of a Brownian bridge simply by conditioning on X1 = 0.
Corollary 4 If Xt is a Brownian bridge over 0 ≤ t ≤ 1 then,
over a ≥ 0.

The result stated for the Brownian bridge maximum is known as the Rayleigh distribution with scale parameter 1/2, and is the square root of an exponential distribution.
We can also ask about the maximum of a Brownian motion with drift μ, so that Xt = Bt + μt where B is standard Brownian motion. Interestingly, the drift has no effect whatsoever on the joint distribution of {Xs}s ≤ t conditioned on Xt and, in particular, it has no effect on the distribution of X∗t conditioned on Xt. Hence, theorem 3 still holds. We saw in the post on Brownian bridges
 |
where the second term on the right hand side is a Brownian bridge independently of the first term so that, conditioned on Xt, does not depend on the drift μ.
So, if X is a Brownian motion with drift μ, and f: ℝ → ℝ is a measurable function with f(x) = 0 over x > a, applying theorem 3 gives
![\displaystyle \begin{aligned} {\mathbb E}[1_{\{X^*_t > a\}}f(X_t)] &={\mathbb E}[e^{2at^{-1}(X_t-a)}f(X_t)]\\ &=e^{2a\mu}{\mathbb E}[f(2a+X_t)]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5B1_%7B%5C%7BX%5E%2A_t+%3E+a%5C%7D%7Df%28X_t%29%5D+%26%3D%7B%5Cmathbb+E%7D%5Be%5E%7B2at%5E%7B-1%7D%28X_t-a%29%7Df%28X_t%29%5D%5C%5C+%26%3De%5E%7B2a%5Cmu%7D%7B%5Cmathbb+E%7D%5Bf%282a%2BX_t%29%5D.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
The second equality here can be verified, as above, by integrating with respect to the normal density with mean μt for Xt, or by using standard change of measure formulas for the normal distribution. Adding on the nonzero values of f(Xt) over Xt > a, we obtain the generalization of theorem 2 to Brownian motion with drift.
Theorem 5 Let X be Brownian motion with drift μ and f: ℝ → ℝ be measurable such that f(Xt) is integrable. Then,
for all a > 0.
![\displaystyle \begin{aligned} {\mathbb E}[1_{\{X^*_t > a\}}f(X_t)] &={\mathbb E}[1_{\{X_t > a\}}f(X_t)+1_{\{X_t < -a\}}e^{2a\mu}f(2a+X_t)]\\ &={\mathbb E}[1_{\{X_t > a\}}f(X_t)+1_{\{X_t > a + 2\mu t\}}e^{2a\mu}f(2a+2\mu t-X_t)]\\ \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5B1_%7B%5C%7BX%5E%2A_t+%3E+a%5C%7D%7Df%28X_t%29%5D+%26%3D%7B%5Cmathbb+E%7D%5B1_%7B%5C%7BX_t+%3E+a%5C%7D%7Df%28X_t%29%2B1_%7B%5C%7BX_t+%3C+-a%5C%7D%7De%5E%7B2a%5Cmu%7Df%282a%2BX_t%29%5D%5C%5C+%26%3D%7B%5Cmathbb+E%7D%5B1_%7B%5C%7BX_t+%3E+a%5C%7D%7Df%28X_t%29%2B1_%7B%5C%7BX_t+%3E+a+%2B+2%5Cmu+t%5C%7D%7De%5E%7B2a%5Cmu%7Df%282a%2B2%5Cmu+t-X_t%29%5D%5C%5C+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
The final equality here is just using the fact that Xt has mean μt and, by symmetry, has the same distribution as 2μt – Xt.
Applications to non-Brownian motions
It is interesting to apply the ideas discussed above to processes which are not Brownian motion. While this does not exactly work, it does sometimes lead to inequalities which can be useful.
Consider a (cadlag) symmetric Lévy process X started from zero. For example, it could be a Cauchy process. This has independent and symmetric increments just as with Brownian motion, which is enough to conclude by the strong Markov property that the reflected process has the same distribution as X. However, it is not continuous. As a result, if τ is the first time at which it hits level a, we have Xτ ≥ a but equality need not hold. It is possible for the process to jump straight past the level, so that Xτ is strictly greater than a. So, it is possible for both X and the reflected process Xr to end up above a giving an inequality,
 |
Applying the argument above results in
 |
showing that, although X∗t need not have the same distribution as |Xt|, it is stochastically dominated by it.
For another example, suppose that X is an Ornstein-Uhlenbeck process, which is a solution to the stochastic differential equation (SDE)
 |
for positive constants σ, λ and driving Brownian motion W. Such processes are strong Markov such that for times s < t then, conditioned on ℱs, Xt is normal with mean e–λ(t - s)Xs and variance σ2(1 - e-2λ(t - s))/(2λ). I will suppose that X starts from zero so that its distribution is a zero mean Gaussian at positive times.
If τ is the first time at which X reaches positive level a then, by continuity, we do have Xτ = a. However, its reflection at this time will not have the same distribution as X. For one thing, according to the SDE, X has negative drift –λa just after this time whereas Xr will have positive drift λa. So, the reflection principle does not work in the same way.
While it is possible to use a comparison between SDEs with different drifts to show that Xr stochastically dominates X, and continue in this way, a simpler argument can be used. As with the second bullet point further up in this post, we instead condition on ℱτ restricted to the event τ ≤ t. The strong Markov property says that Xt is normal with mean e–λ(t - τ)a ≤ a, so we obtain
 |
Multiplying through by twice the probability that τ ≤ t and, noting that this event is the same as X∗t ≥ a gives
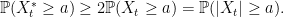 |
So X∗t stochastically dominates |Xt|, in contrast to the Lévy process example above.
For a third example consider solutions to an SDE of the form
 |
for driving Brownian motion W. Such processes are familiar in finance where X is the evolution of an asset price with local volatility surface σ(t, x). Now suppose that σ(t, x) is increasing in x at each time. It can be shown that this skews the distribution so that, for any starting value of X0 we have
 |
This can be explained intuitively. As the volatility is higher when X > X0, this will make it more quickly move back below X0 where the volatility is lower, so that it will stay below X0 for longer. Hence, at a fixed positive time, it is more likely to be below X0 than above it.
If we condition on the first time τ at which it reaches level a > X0, then the forward starting process Xτ + s starts from level a and satisfies an SDE of the form above. So, conditioned on τ < t, this gives
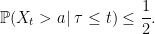 |
Multiplying through by twice the probability that τ ≤ t we again obtain the inequality
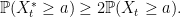 |
As X does not have a symmetric distribution, this cannot be expressed in terms of X∗t stochastically dominating |Xt|, but the inequality is just as useful in this form. In the local volatility model used in finance, this is saying that with upwards sloping volatilities, the price of a one-touch option (paying 1 unit if X exceeds a at any time before expiry t) is more than twice as expensive as a digital call option (paying 1 unit if X exceeds a at time t). If the local volatility surface is decreasing in x instead, then the inequality goes the other way.
