
The normal (or Gaussian) distribution is ubiquitous throughout probability theory for various reasons, including the central limit theorem, the fact that it is realistic for many practical applications, and because it satisfies nice properties making it amenable to mathematical manipulation. It is, therefore, one of the first continuous distributions that students encounter at school. As such, it is not something that I have spent much time discussing on this blog, which is usually concerned with more advanced topics. However, there are many nice properties and methods that can be performed with normal distributions, greatly simplifying the manipulation of expressions in which it is involved. While it is usually possible to ignore these, and instead just substitute in the density function and manipulate the resulting integrals, that approach can get very messy. So, I will describe some of the basic results and ideas that I use frequently.
Throughout, I assume the existence of an underlying probability space 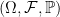
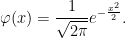 |
For it to function as a probability density, it is necessary that it integrates to one. While it is not obvious that the normalization factor 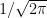
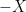

![{{\mathbb E}[X]=0}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BX%5D%3D0%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The derivative of the density function satisfies the useful identity
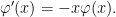 |
(1) |
This allows us to quickly verify that standard normal variables have unit variance, by an application of integration by parts.
![\displaystyle \begin{aligned} {\mathbb E}[X^2] &=\int x^2\varphi(x)dx\\ &= -\int x\varphi^\prime(x)dx\\ &=\int\varphi(x)dx-[x\varphi(x)]_{-\infty}^\infty=1 \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5BX%5E2%5D+%26%3D%5Cint+x%5E2%5Cvarphi%28x%29dx%5C%5C+%26%3D+-%5Cint+x%5Cvarphi%5E%5Cprime%28x%29dx%5C%5C+%26%3D%5Cint%5Cvarphi%28x%29dx-%5Bx%5Cvarphi%28x%29%5D_%7B-%5Cinfty%7D%5E%5Cinfty%3D1+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
Another identity satisfied by the normal density function is,
 |
(2) |
This enables us to prove the following very useful result. In fact, it is difficult to overstate how helpful this result can be. I make use of it frequently when manipulating expressions involving normal variables, as it significantly simplifies the calculations. It is also easy to remember, and simple to derive if needed.
Theorem 1 Let X be standard normal and
be measurable. Then, for all
,
(3)
![\displaystyle \begin{aligned} {\mathbb E}[e^{\lambda X}f(X)] &={\mathbb E}[e^{\lambda X}]{\mathbb E}[f(X+\lambda)]\\ &=e^{\frac{\lambda^2}{2}}{\mathbb E}[f(X+\lambda)]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5Be%5E%7B%5Clambda+X%7Df%28X%29%5D+%26%3D%7B%5Cmathbb+E%7D%5Be%5E%7B%5Clambda+X%7D%5D%7B%5Cmathbb+E%7D%5Bf%28X%2B%5Clambda%29%5D%5C%5C+%26%3De%5E%7B%5Cfrac%7B%5Clambda%5E2%7D%7B2%7D%7D%7B%5Cmathbb+E%7D%5Bf%28X%2B%5Clambda%29%5D.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: Using identity (2), we can evaluate ![{{\mathbb E}[e^{\lambda X}f(X)]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5Be%5E%7B%5Clambda+X%7Df%28X%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \begin{aligned} \int e^{\lambda x}f(x)\varphi(x)dx &=\int f(x)e^{\frac12\lambda^2}\varphi(x-\lambda)dx\\ &=\int f(y+\lambda)e^{\frac12\lambda^2}\varphi(y)dy\\ &=e^{\frac12\lambda^2}{\mathbb E}[f(X+\lambda)]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%5Cint+e%5E%7B%5Clambda+x%7Df%28x%29%5Cvarphi%28x%29dx+%26%3D%5Cint+f%28x%29e%5E%7B%5Cfrac12%5Clambda%5E2%7D%5Cvarphi%28x-%5Clambda%29dx%5C%5C+%26%3D%5Cint+f%28y%2B%5Clambda%29e%5E%7B%5Cfrac12%5Clambda%5E2%7D%5Cvarphi%28y%29dy%5C%5C+%26%3De%5E%7B%5Cfrac12%5Clambda%5E2%7D%7B%5Cmathbb+E%7D%5Bf%28X%2B%5Clambda%29%5D.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
Here, the substitution 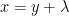

![{{\mathbb E}[e^{\lambda X}]=e^{\frac12\lambda^2}}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5Be%5E%7B%5Clambda+X%7D%5D%3De%5E%7B%5Cfrac12%5Clambda%5E2%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The above result clearly applies more generally to complex valued functions 


Although (3) is simple enough as it is, I find it easier to understand as two separate statements. The first of these is that, when computing the expected value of the product of 

![\displaystyle {\mathbb E}[e^{\lambda X}f(X)]={\mathbb E}[e^{\lambda X}]{\mathbb E}[f(X+\lambda)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Be%5E%7B%5Clambda+X%7Df%28X%29%5D%3D%7B%5Cmathbb+E%7D%5Be%5E%7B%5Clambda+X%7D%5D%7B%5Cmathbb+E%7D%5Bf%28X%2B%5Clambda%29%5D.+&bg=ffffff&fg=000000&s=0&c=20201002) |
The second statement is the identity
Theorem 2 Let X be a standard normal. Then,
is integrable for all
and,
(4)
![\displaystyle {\mathbb E}\left[e^{\lambda X}\right]=e^{\frac12\lambda^2}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7B%5Clambda+X%7D%5Cright%5D%3De%5E%7B%5Cfrac12%5Clambda%5E2%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: For real 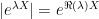
![\displaystyle \frac{d}{d\lambda}{\mathbb E}[e^{\lambda X}]={\mathbb E}[Xe^{\lambda X}].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cfrac%7Bd%7D%7Bd%5Clambda%7D%7B%5Cmathbb+E%7D%5Be%5E%7B%5Clambda+X%7D%5D%3D%7B%5Cmathbb+E%7D%5BXe%5E%7B%5Clambda+X%7D%5D.+&bg=ffffff&fg=000000&s=0&c=20201002) |
As both sides of (4) are differentiable, and agree on
As characteristic functions are defined for all probability distributions, and they uniquely determine the distribution, a particularly common case of (4) is obtained by taking imaginary 
![\displaystyle {\mathbb E}[e^{iuX}]=e^{-\frac12 u^2}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Be%5E%7BiuX%7D%5D%3De%5E%7B-%5Cfrac12+u%5E2%7D.+&bg=ffffff&fg=000000&s=0&c=20201002) |
Although this is true for all complex values of 
Another application of the moment generating function (4) is, as the name suggests, to generate the moments. We expand out the exponentials as power series,
![\displaystyle \begin{aligned} &{\mathbb E}[e^{\lambda X}]=\sum_{n=0}^\infty\frac{\lambda^n}{n!}{\mathbb E}[X^n],\\ &e^{\frac12\lambda^2}=\sum_{n=0}^\infty\frac{\lambda^{2n}}{2^nn!}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%26%7B%5Cmathbb+E%7D%5Be%5E%7B%5Clambda+X%7D%5D%3D%5Csum_%7Bn%3D0%7D%5E%5Cinfty%5Cfrac%7B%5Clambda%5En%7D%7Bn%21%7D%7B%5Cmathbb+E%7D%5BX%5En%5D%2C%5C%5C+%26e%5E%7B%5Cfrac12%5Clambda%5E2%7D%3D%5Csum_%7Bn%3D0%7D%5E%5Cinfty%5Cfrac%7B%5Clambda%5E%7B2n%7D%7D%7B2%5Enn%21%7D.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
Comparing coefficients of powers of
Corollary 3 A standard normal variable X has odd moments equal to zero and even moments
![\displaystyle {\mathbb E}[X^{2n}]=\frac{(2n)!}{2^nn!}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5BX%5E%7B2n%7D%5D%3D%5Cfrac%7B%282n%29%21%7D%7B2%5Enn%21%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
Now, let’s move on and consider normal distributions with arbitrary mean and variance. Let 

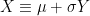


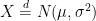

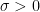
Lemma 4 For

Proof: Write 

![\displaystyle \begin{aligned} {\mathbb E}[f(\mu+\sigma Y)] &=\int f(\mu+\sigma y)\varphi(y)dy\\ &=\int f(x)\varphi(\sigma^{-1}(x-\mu))\sigma^{-1}dx \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5Bf%28%5Cmu%2B%5Csigma+Y%29%5D+%26%3D%5Cint+f%28%5Cmu%2B%5Csigma+y%29%5Cvarphi%28y%29dy%5C%5C+%26%3D%5Cint+f%28x%29%5Cvarphi%28%5Csigma%5E%7B-1%7D%28x-%5Cmu%29%29%5Csigma%5E%7B-1%7Ddx+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
as required. Here, I substituted in 
The manipulations above for standard normal random variables carries across to general normal distributions, without much trouble.
Theorem 5 If X is normal then
(5) for all
![\displaystyle {\mathbb E}[e^{\lambda X}] =e^{\lambda{\mathbb E}[X]+\frac12\lambda^2{\rm Var}(X)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Be%5E%7B%5Clambda+X%7D%5D+%3De%5E%7B%5Clambda%7B%5Cmathbb+E%7D%5BX%5D%2B%5Cfrac12%5Clambda%5E2%7B%5Crm+Var%7D%28X%29%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: When X is standard normal, this is just the same as (4). However, it remains true if we multiply X by a real value 

This result should be very easy to remember. As a very naive, or first order approximation, we might expect that ![{{\mathbb E}[\exp(X)]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5B%5Cexp%28X%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{\exp({\mathbb E}[X])}](https://s0.wp.com/latex.php?latex=%7B%5Cexp%28%7B%5Cmathbb+E%7D%5BX%5D%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle {\mathbb E}[\exp(X)]=\exp\left({\mathbb E}[X]+\frac12{\rm Var}(X)\right).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5B%5Cexp%28X%29%5D%3D%5Cexp%5Cleft%28%7B%5Cmathbb+E%7D%5BX%5D%2B%5Cfrac12%7B%5Crm+Var%7D%28X%29%5Cright%29.+&bg=ffffff&fg=000000&s=0&c=20201002) |
This is (5) for 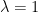
Theorem 5 implies the following simple characterisation of normal distributions.
Corollary 6 A real-valued random variable is normal if and only if its characteristic function is of the form
for a quadratic
.
Proof: First, if X is normal, then its characteristic function is of the stated form by theorem 5. Conversely, suppose that the characteristic function is of the stated form for a quadratic 
![\displaystyle {\mathbb E}[e^{iuX}]=\exp\left(-\frac12au^2+ibu+c\right).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Be%5E%7BiuX%7D%5D%3D%5Cexp%5Cleft%28-%5Cfrac12au%5E2%2Bibu%2Bc%5Cright%29.+&bg=ffffff&fg=000000&s=0&c=20201002) |
Taking 

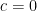
Theorem 1 also carries across in the same way to arbitrary normal random variables.
Theorem 7 Let X be normal and
(6) for all
![\displaystyle {\mathbb E}[e^{\lambda X}f(X)] ={\mathbb E}[e^{\lambda X}]{\mathbb E}\left[f(X+\lambda{\rm Var}(X))\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Be%5E%7B%5Clambda+X%7Df%28X%29%5D+%3D%7B%5Cmathbb+E%7D%5Be%5E%7B%5Clambda+X%7D%5D%7B%5Cmathbb+E%7D%5Cleft%5Bf%28X%2B%5Clambda%7B%5Crm+Var%7D%28X%29%29%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: For standard normal X, this is just (3). Then, it remains true if we multiply X by a real value 
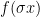
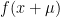
I actually find this result slightly easier to remember in a modified form. For two random variables X and Y with finite variances, their covariance is defined as
![\displaystyle \begin{aligned} {\rm Cov}(X,Y) &={\mathbb E}[(X-{\mathbb E} X)(Y-{\mathbb E} Y)]\\ &={\mathbb E}[XY]-{\mathbb E}[X]{\mathbb E}[Y]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Crm+Cov%7D%28X%2CY%29+%26%3D%7B%5Cmathbb+E%7D%5B%28X-%7B%5Cmathbb+E%7D+X%29%28Y-%7B%5Cmathbb+E%7D+Y%29%5D%5C%5C+%26%3D%7B%5Cmathbb+E%7D%5BXY%5D-%7B%5Cmathbb+E%7D%5BX%5D%7B%5Cmathbb+E%7D%5BY%5D.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
Note that this is bilinear and symmetric in X and Y and that 
Theorem 8 Let X be a normal random variable and
for some
. Then,
(7) for all measurable functions
![\displaystyle {\mathbb E}\left[e^Yf(X)\right]={\mathbb E}\left[e^Y\right]{\mathbb E}\left[f\left(X+{\rm Cov}(X,Y)\right)\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Cleft%5Be%5EYf%28X%29%5Cright%5D%3D%7B%5Cmathbb+E%7D%5Cleft%5Be%5EY%5Cright%5D%7B%5Cmathbb+E%7D%5Cleft%5Bf%5Cleft%28X%2B%7B%5Crm+Cov%7D%28X%2CY%29%5Cright%29%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: This is immediate from (6) with 

So, the expectation of the product of 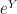

I find theorem 8 more intuitive when understood in terms of changes of measure. For a nonnegative random variable Z with mean 1, we can use this as a weighting to define a new probability measure 
![\displaystyle {\mathbb Q}(A)={\mathbb E}[1_AZ]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+Q%7D%28A%29%3D%7B%5Cmathbb+E%7D%5B1_AZ%5D+&bg=ffffff&fg=000000&s=0&c=20201002) |
for all measurable sets A. Note that the probability of the whole space under the new measure is ![{{\mathbb Q}(\Omega)={\mathbb E}[Z]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+Q%7D%28%5COmega%29%3D%7B%5Cmathbb+E%7D%5BZ%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

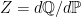

![\displaystyle {\mathbb E}_Q[X]={\mathbb E}[XZ]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D_Q%5BX%5D%3D%7B%5Cmathbb+E%7D%5BXZ%5D+&bg=ffffff&fg=000000&s=0&c=20201002) |
for all nonnegative random variables X. If instead we are given a nonnegative random variable Z whose mean is not necessarily equal to 1, but is nonzero and finite, then we can normalize by dividing through by its mean. This defines the new probability measure ![{d{\mathbb Q}=(Z/{\mathbb E}[Z])d{\mathbb P}}](https://s0.wp.com/latex.php?latex=%7Bd%7B%5Cmathbb+Q%7D%3D%28Z%2F%7B%5Cmathbb+E%7D%5BZ%5D%29d%7B%5Cmathbb+P%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
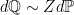
![\displaystyle {\mathbb E}_{\mathbb Q}[X]={\mathbb E}[XZ]/{\mathbb E}[Z]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D_%7B%5Cmathbb+Q%7D%5BX%5D%3D%7B%5Cmathbb+E%7D%5BXZ%5D%2F%7B%5Cmathbb+E%7D%5BZ%5D+&bg=ffffff&fg=000000&s=0&c=20201002) |
for nonnegative random variables X.
Normal random variables are not themselves nonnegative, so cannot be used directly for measure changes. However, their exponentials, known as lognormal random variables, are nonnegative. I now rewrite theorem 8 in terms of measure changes, which is my preferred form.
Theorem 9 Let X be a normal random variable and
then, X is normal with the same variance as under
but with mean
.
Proof: Set 
![\displaystyle {\mathbb E}_{\mathbb Q}[f(X)]={\mathbb E}[e^Yf(X)]/{\mathbb E}[e^Y]={\mathbb E}[f(\tilde X)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D_%7B%5Cmathbb+Q%7D%5Bf%28X%29%5D%3D%7B%5Cmathbb+E%7D%5Be%5EYf%28X%29%5D%2F%7B%5Cmathbb+E%7D%5Be%5EY%5D%3D%7B%5Cmathbb+E%7D%5Bf%28%5Ctilde+X%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002) |
as required. ⬜
So, when we apply lognormal measure changes, the original normal random variable remains normal with the same variance, but with a shifted mean.
I now apply the ideas described above to the Black-Scholes formula for financial option pricing. I use 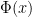
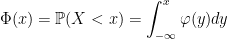 |
for a standard normal X.
Example 1 (Black-Scholes formula) Suppose that S is lognormal with mean
and nonzero log-variance
. Then, for all
,
(8) where,
![\displaystyle {\mathbb E}[(S-K)_+]=F\Phi(d_1)-K\Phi(d_2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5B%28S-K%29_%2B%5D%3DF%5CPhi%28d_1%29-K%5CPhi%28d_2%29+&bg=ffffff&fg=000000&s=0&c=20201002)

While (8) is not difficult to prove by writing out the expectation as an integral, and directly applying changes of variables to this, it can get rather messy. Instead, start by expanding 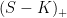

![\displaystyle \begin{aligned} {\mathbb E}[(S-K)_+] &={\mathbb E}[S1_{\{S > K\}}]-K{\mathbb P}(S > K)\\ &=F{\mathbb Q}(S > K)-K{\mathbb P}(S > K), \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5B%28S-K%29_%2B%5D+%26%3D%7B%5Cmathbb+E%7D%5BS1_%7B%5C%7BS+%3E+K%5C%7D%7D%5D-K%7B%5Cmathbb+P%7D%28S+%3E+K%29%5C%5C+%26%3DF%7B%5Cmathbb+Q%7D%28S+%3E+K%29-K%7B%5Cmathbb+P%7D%28S+%3E+K%29%2C+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
(9) |
where we substituted in the probability measure 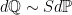
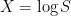
![\displaystyle F={\mathbb E}[S]=e^{{\mathbb E}[X]+\frac12\sigma^2}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++F%3D%7B%5Cmathbb+E%7D%5BS%5D%3De%5E%7B%7B%5Cmathbb+E%7D%5BX%5D%2B%5Cfrac12%5Csigma%5E2%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
giving the mean of X as ![{{\mathbb E}[X]=\log F-\frac12\sigma^2}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BX%5D%3D%5Clog+F-%5Cfrac12%5Csigma%5E2%7D&bg=ffffff&fg=000000&s=0&c=20201002)

 |
The final term on the right hand side of (9) then agrees with the final term on the right of (8).
The calculation for ![{{\mathbb E}_{\mathbb Q}[S]=e^{\sigma^2}F}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D_%7B%5Cmathbb+Q%7D%5BS%5D%3De%5E%7B%5Csigma%5E2%7DF%7D&bg=ffffff&fg=000000&s=0&c=20201002)


 |
Substituting this into (9) gives (8) as claimed.
The approach to the Black-Scholes formula here is entirely mathematical, involving the manipulations described above for normal variables. The method, including the use of a measure change, can also described financially in terms of option cashflows Suppose that we want to value a payout at some future time given in terms of a dollar amount. Say, V dollars. Under the forward dollar pricing measure, this is given by an expectation ![{{\mathbb E}[V]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BV%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{{\mathbb E}[SV]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BSV%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
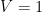
Again consider a future payment of V euros. As mentioned above, the dollar value is ![{{\mathbb E}_{\mathbb Q}[V]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D_%7B%5Cmathbb+Q%7D%5BV%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
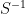
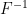
![\displaystyle {\mathbb E}_{{\mathbb Q}}[S^{-1}]={\mathbb E}[SS^{-1}]/{\mathbb E}[S]=F^{-1}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D_%7B%7B%5Cmathbb+Q%7D%7D%5BS%5E%7B-1%7D%5D%3D%7B%5Cmathbb+E%7D%5BSS%5E%7B-1%7D%5D%2F%7B%5Cmathbb+E%7D%5BS%5D%3DF%5E%7B-1%7D.+&bg=ffffff&fg=000000&s=0&c=20201002) |
Now consider a call option on the FX cross with strike K. This will pay us one euro in exchange for K dollars if, on the future date, we decide to exercise. Converted to dollars, this is an amount of 
Note that the following two are the same,
- Receive one euro and pay K dollars, if
.
- Receive one euro if
, and pay K dollars if
.
The first of these describes a call option of strike K. The second describes a binary put option on 


It is well understood that FX options have the same volatility from the viewpoint of both foreign and domestic observers, even though they may be using different measures to express it. This is the first part of the statement of theorem 9 above. This means that 

 |
As 
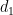
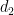

Note that, in the process of deriving the Black-Scholes formula, we also obtained the following simple result.
Lemma 10 Let S be a lognormal random variable with mean
has the same distribution under the measure
as S has under
Writing this out explicitly gives
![\displaystyle {\mathbb E}\left[Sf\left({\mathbb E}[S]^2/S\right)\right]={\mathbb E}[S]{\mathbb E}\left[f(S)\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Cleft%5BSf%5Cleft%28%7B%5Cmathbb+E%7D%5BS%5D%5E2%2FS%5Cright%29%5Cright%5D%3D%7B%5Cmathbb+E%7D%5BS%5D%7B%5Cmathbb+E%7D%5Cleft%5Bf%28S%29%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002) |
for all lognormal random variables S and measurable
The mean of the absolute value and positive part of a standard normal random variable are straightforward to compute.
Lemma 11 Let X be standard normal. Then,
and
.
Proof: We apply identity (1) to evaluate ![{{\mathbb E}[X_+]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BX_%2B%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
 |
Then, by symmetry, ![{{\mathbb E}[\lvert X\rvert]=2{\mathbb E}[X_+]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5B%5Clvert+X%5Crvert%5D%3D2%7B%5Cmathbb+E%7D%5BX_%2B%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Considering the Black-Scholes example again, sometimes traders use an approximate formula which is simple enough to be able to roughly value options in their head, without having to resort to a calculator. This applies to at-the-money options for which the strike K is close to the forward F, and where the log-variance is low enough that the lognormal distribution can be approximated by a normal. This is usually the case for options which are relatively close to their expiration date, implying a small variance.
Example 2 (Simplified Black-Scholes) Let S be normal with mean F and standard deviation
. Then,
![\displaystyle {\mathbb E}[(S-F)_+]=\frac{F\sigma}{\sqrt{2\pi}}\approx0.4 F\sigma.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5B%28S-F%29_%2B%5D%3D%5Cfrac%7BF%5Csigma%7D%7B%5Csqrt%7B2%5Cpi%7D%7D%5Capprox0.4+F%5Csigma.+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: We write 
![\displaystyle {\mathbb E}[(S-F)_+]=F\sigma{\mathbb E}[X_+]=(2\pi)^{-1/2}F\sigma.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5B%28S-F%29_%2B%5D%3DF%5Csigma%7B%5Cmathbb+E%7D%5BX_%2B%5D%3D%282%5Cpi%29%5E%7B-1%2F2%7DF%5Csigma.+&bg=ffffff&fg=000000&s=0&c=20201002) |
By direct calculation, 
Moving on, there are also various expressions which help when looking at quadratic functions of normals. Recall that the gamma distribution with shape parameter 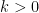
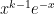
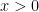
Lemma 12 Let X be standard normal. Then,
has the gamma distribution with shape parameter
. This has probability density
over
.
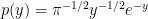
Proof: For any measurable function 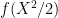
 |
as required. Here, the substitution 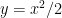
A consequence is that we can easily compute all moments of a standard normal, including the noninteger moments, in terms of the gamma function. Recall that this is defined by
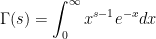 |
over 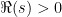
Corollary 13 If X is standard normal then, for all
with
,
![\displaystyle {\mathbb E}[\lvert X\rvert^s]=2^{s/2}\pi^{-1/2}\Gamma\left(\frac{s+1}{2}\right).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5B%5Clvert+X%5Crvert%5Es%5D%3D2%5E%7Bs%2F2%7D%5Cpi%5E%7B-1%2F2%7D%5CGamma%5Cleft%28%5Cfrac%7Bs%2B1%7D%7B2%7D%5Cright%29.+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: As 

![\displaystyle {\mathbb E}[(2Y)^{s/2}] =2^{s/2}\pi^{-1/2}\int_0^\infty y^{s/2} y^{-1/2}e^{-y}dy](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5B%282Y%29%5E%7Bs%2F2%7D%5D+%3D2%5E%7Bs%2F2%7D%5Cpi%5E%7B-1%2F2%7D%5Cint_0%5E%5Cinfty+y%5E%7Bs%2F2%7D+y%5E%7B-1%2F2%7De%5E%7B-y%7Ddy+&bg=ffffff&fg=000000&s=0&c=20201002) |
as required. ⬜
This result is not immediately obvious, even at 

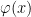

For nonnegative even integer values 
![\displaystyle {\mathbb E}[X^{2n}]=2^n\pi^{-1/2}\Gamma(n+1/2)=\frac{(2n)!}{2^nn!}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5BX%5E%7B2n%7D%5D%3D2%5En%5Cpi%5E%7B-1%2F2%7D%5CGamma%28n%2B1%2F2%29%3D%5Cfrac%7B%282n%29%21%7D%7B2%5Enn%21%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
In particular, this can only be true if the gamma function at half-integer values satisfies
 |
For 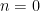


For another consequence of lemma 12, expectations involving a normal variable can always be expressed using a gamma distribution.
Corollary 14 Let X be standard normal. Then, for all measurable
where
![\displaystyle {\mathbb E}[f(X)]=\frac12{\mathbb E}\left[f(\sqrt{2Y})+f(-\sqrt{2Y})\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Bf%28X%29%5D%3D%5Cfrac12%7B%5Cmathbb+E%7D%5Cleft%5Bf%28%5Csqrt%7B2Y%7D%29%2Bf%28-%5Csqrt%7B2Y%7D%29%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: By symmetry,
![\displaystyle \begin{aligned} &{\mathbb E}[1_{\{X > 0\}}f(X)]=\frac12{\mathbb E}[f(\lvert X\rvert)]=\frac12{\mathbb E}\left[f(\sqrt{2Y})\right],\\ &{\mathbb E}[1_{\{X < 0\}}f(X)]=\frac12{\mathbb E}[f(-\lvert X\rvert)]=\frac12{\mathbb E}\left[f(-\sqrt{2Y})\right], \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%26%7B%5Cmathbb+E%7D%5B1_%7B%5C%7BX+%3E+0%5C%7D%7Df%28X%29%5D%3D%5Cfrac12%7B%5Cmathbb+E%7D%5Bf%28%5Clvert+X%5Crvert%29%5D%3D%5Cfrac12%7B%5Cmathbb+E%7D%5Cleft%5Bf%28%5Csqrt%7B2Y%7D%29%5Cright%5D%2C%5C%5C+%26%7B%5Cmathbb+E%7D%5B1_%7B%5C%7BX+%3C+0%5C%7D%7Df%28X%29%5D%3D%5Cfrac12%7B%5Cmathbb+E%7D%5Bf%28-%5Clvert+X%5Crvert%29%5D%3D%5Cfrac12%7B%5Cmathbb+E%7D%5Cleft%5Bf%28-%5Csqrt%7B2Y%7D%29%5Cright%5D%2C+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
and, adding these together gives the result. ⬜
The normal density function also satisfies the following simple identity
 |
(10) |
for all real 
Theorem 15 If X is standard normal then,
(11) for all measurable
![\displaystyle {\mathbb E}[e^{-\frac12\lambda X^2}f(X)]=\frac1{\sqrt{1+\lambda}}{\mathbb E}\left[f\left(\frac X{\sqrt{1+\lambda}}\right)\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Be%5E%7B-%5Cfrac12%5Clambda+X%5E2%7Df%28X%29%5D%3D%5Cfrac1%7B%5Csqrt%7B1%2B%5Clambda%7D%7D%7B%5Cmathbb+E%7D%5Cleft%5Bf%5Cleft%28%5Cfrac+X%7B%5Csqrt%7B1%2B%5Clambda%7D%7D%5Cright%29%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: The expectation of 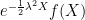
 |
as required. Here, the substitution 
The following result follows from theorem 15 in the same way that theorem 2 followed from theorem 1.
Theorem 16 If X is standard normal and
is integrable if and only if
, in which case
(12)
![\displaystyle {\mathbb E}[e^{-\frac12\lambda X^2}]=\frac1{\sqrt{1+\lambda}}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Be%5E%7B-%5Cfrac12%5Clambda+X%5E2%7D%5D%3D%5Cfrac1%7B%5Csqrt%7B1%2B%5Clambda%7D%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: If 
 |
has infinite integral over the real numbers and, hence,
Using real values of 
The remaining results given above for standard normals also carry across to the case with arbitrary mean and variance in a straightforward way. For example, theorem 16 extends as follows. This result is a bit less easy to remember than the others, so if needed, I would just derive it in the same way as done here.
Lemma 17 If X is normal with mean
, in which case
(13)
![\displaystyle {\mathbb E}\left[e^{-\frac12\lambda X^2}\right]=\frac{1}{\sqrt{1+\lambda \sigma^2}}e^{-\frac12\lambda\mu^2/(1+\lambda\sigma^2)}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7B-%5Cfrac12%5Clambda+X%5E2%7D%5Cright%5D%3D%5Cfrac%7B1%7D%7B%5Csqrt%7B1%2B%5Clambda+%5Csigma%5E2%7D%7De%5E%7B-%5Cfrac12%5Clambda%5Cmu%5E2%2F%281%2B%5Clambda%5Csigma%5E2%29%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: As 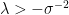
![\displaystyle \begin{aligned} {\mathbb E}\left[e^{-\frac12\lambda\sigma^2Y^2}e^{-\lambda\sigma\mu Y-\frac12\lambda\mu^2}\right] &=\frac1{\sqrt{1+\lambda\sigma^2}}{\mathbb E}\left[e^{-\lambda\sigma\mu Y/\sqrt{1+\lambda\sigma^2}-\frac12\lambda\mu^2}\right]\\ &=\frac1{\sqrt{1+\lambda\sigma^2}}e^{\frac12\lambda^2\sigma^2\mu^2/(1+\lambda\sigma^2)-\frac12\lambda\mu^2} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7B-%5Cfrac12%5Clambda%5Csigma%5E2Y%5E2%7De%5E%7B-%5Clambda%5Csigma%5Cmu+Y-%5Cfrac12%5Clambda%5Cmu%5E2%7D%5Cright%5D+%26%3D%5Cfrac1%7B%5Csqrt%7B1%2B%5Clambda%5Csigma%5E2%7D%7D%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7B-%5Clambda%5Csigma%5Cmu+Y%2F%5Csqrt%7B1%2B%5Clambda%5Csigma%5E2%7D-%5Cfrac12%5Clambda%5Cmu%5E2%7D%5Cright%5D%5C%5C+%26%3D%5Cfrac1%7B%5Csqrt%7B1%2B%5Clambda%5Csigma%5E2%7D%7De%5E%7B%5Cfrac12%5Clambda%5E2%5Csigma%5E2%5Cmu%5E2%2F%281%2B%5Clambda%5Csigma%5E2%29-%5Cfrac12%5Clambda%5Cmu%5E2%7D+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
The first equality is applying (11) and the second is using (4). Rearranging gives (13). As previously, analytic continuation extends this to all 


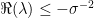
Theorem 9 showing that normal variables remain normal under a lognormal change of measure also extends to changes of measure involving the square of a normal.
Theorem 18 If X is normal then it remains normal under the measure given by
for any
Proof: As 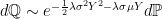


As stated, this is a very easy result to remember. The exact distribution of X under the measure change requires also computing its mean and variance. For example, the variance of X under the measure 

 |
(14) |
Alternatively, the moment generating function under 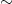
![\displaystyle \begin{aligned} {\mathbb E}_{\mathbb Q}[e^{-u\lambda X}] &\sim{\mathbb E}[e^{-u\lambda X-\frac12\lambda X^2}]\\ &=e^{\frac12\lambda u^2}{\mathbb E}[e^{-\frac12\lambda(X+u)^2}]\\ &\sim e^{\frac12\lambda u^2}e^{-\frac12\lambda(u+\mu)^2/(1+\lambda\sigma^2)} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D_%7B%5Cmathbb+Q%7D%5Be%5E%7B-u%5Clambda+X%7D%5D+%26%5Csim%7B%5Cmathbb+E%7D%5Be%5E%7B-u%5Clambda+X-%5Cfrac12%5Clambda+X%5E2%7D%5D%5C%5C+%26%3De%5E%7B%5Cfrac12%5Clambda+u%5E2%7D%7B%5Cmathbb+E%7D%5Be%5E%7B-%5Cfrac12%5Clambda%28X%2Bu%29%5E2%7D%5D%5C%5C+%26%5Csim+e%5E%7B%5Cfrac12%5Clambda+u%5E2%7De%5E%7B-%5Cfrac12%5Clambda%28u%2B%5Cmu%29%5E2%2F%281%2B%5Clambda%5Csigma%5E2%29%7D+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
Noting that this is the exponential of a quadratic in u, we can read off the mean and variance from the coefficients of 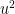

![\displaystyle {\mathbb E}_{\mathbb Q}[X]=\frac{\mu}{1+\lambda\sigma^2}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D_%7B%5Cmathbb+Q%7D%5BX%5D%3D%5Cfrac%7B%5Cmu%7D%7B1%2B%5Clambda%5Csigma%5E2%7D.+&bg=ffffff&fg=000000&s=0&c=20201002) |
(15) |
We see that, under the change of measure in theorem 18, both the mean and variance of X are divided by 
