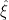Here, I apply the theory outlined in the previous post to fully describe the drawdown point process of a standard Brownian motion. In fact, as I will show, the drawdowns can all be constructed from independent copies of a single ‘Brownian excursion’ stochastic process. Recall that we start with a continuous stochastic process X, assumed here to be Brownian motion, and define its running maximum as and drawdown process . This is as in figure 1 above.
Next, was defined to be the drawdown ‘excursion’ over the interval at which the maximum process is equal to the value . Precisely, if we let be the first time at which X hits level and be its right limit then,
Next, a random set S is defined as the collection of all nonzero drawdown excursions indexed the running maximum,
The set of drawdown excursions corresponding to the sample path from figure 1 are shown in figure 2 below.
Figure 2: Brownian drawdown excursions
As described in the post on semimartingale local times, the joint distribution of the drawdown and running maximum , of a Brownian motion, is identical to the distribution of its absolute value and local time at zero, . Hence, the point process consisting of the drawdown excursions indexed by the running maximum, and the absolute value of the excursions from zero indexed by the local time, both have the same distribution. So, the theory described in this post applies equally to the excursions away from zero of a Brownian motion.
Before going further, let’s recap some of the technical details. The excursions lie in the space E of continuous paths , on which we define a canonical process Z by sampling the path at each time t, . This space is given the topology of uniform convergence over finite time intervals (compact open topology), which makes it into a Polish space, and whose Borel sigma-algebra is equal to the sigma-algebra generated by . As shown in the previous post, the counting measure is a random point process on . In fact, it is a Poisson point process, so its distribution is fully determined by its intensity measure .
Theorem 1 If X is a standard Brownian motion, then the drawdown point process is Poisson with intensity measure where,
is the standard Lebesgue measure on .
is a sigma-finite measure on E given by
(1)
for all bounded continuous continuous maps which vanish on paths of length less than L (some ). The limit is taken over , denotes expectation under the measure with respect to which Z is a Brownian motion started at , and is the first time at which Z hits 0. This measure satisfies the following properties,
-almost everywhere, there exists a time such that on and everywhere else.
for each , the distribution of has density
(2)
over the range .
over , is Markov, with transition function of a Brownian motion stopped at zero.
I give the proof of this in a moment but, first, I briefly look at what it means and some simple consequences. For any measurable set , then is the number of nonzero excursions for which is in A, and has a Poisson distribution of rate . The fact that the intensity is a product measure, , means that for any and then, the number of values for which is nonzero and lies in A is Poisson with rate . In particular, the process counting the number of excursions lying in A is a Poisson process of rate . At least, this is true so long as is finite.
Next, lets look at the stated properties of the measure , and what these mean for the drawdowns. The first property simply states that, with probability one, for each such that the excursion is nonzero then there exists a time such that on and everywhere else. In fact, it is not difficult to see that almost surely. This time T is the length of the excursion, which will be denoted by
and, -almost everywhere is a positive real number.
Next, for each time , is -almost everywhere nonnegative. The second stated property gives its distribution over the range . This is a measure, but need not be a probability measure as the total measure will not generally be equal to one. The measure of can be computed by integrating over the density,
So, we see that has finite measure but, since this tends to infinity as t goes to zero, this means that is not a finite measure. In fact, this gives
for all times .
Noting that the excursion Z has length greater than a positive value T if and only if , the intensity measure for the excursion lengths can be computed as
Equivalently, differentiating gives the density of the distribution of excursion lengths,
(3)
As is infinite, this shows that there are infinitely many drawdowns over every nonzero time interval, although most of these will be of arbitrarily small length. We can also ask, how many drawdowns of at least length T can we expect before the Brownian motion hits a given level . The calculation above shows that that this is Poisson distributed with parameter .
If U is a normal random variable with mean 0 and variance t (defined on some probability space), then is just the probability density of multiplied by , so that,
for all bounded measurable , giving a usual alternative description of the distribution of . Equivalently, writing then,
for a standard normal random variable U defined on some probability space.
Finally, we look at the third property stating that Z is Markov with transition function of a Brownian motion stopped at zero. Recall that, with respect to a filtered probability space a (real-valued) process Z is Markov with transition function if and only if
almost surely for all bounded measurable . In the situation here, we can define the sigma-algebras for all , giving us a ‘filtered measure space’ . The fact that is not a probability measure, and is not even finite, does not matter. All that is needed for defining the Markov property is for conditional expectations with respect to the sigma-algebra to be well defined. For this, we just need the restriction of to to be sigma-finite. This is indeed the case since, for each , the collection of paths of length at least T is in and the union of these as T goes to zero, together with the zero path, gives all of E. Then, the expectation of a bounded measurable random variable conditional on is defined to be the unique (up to -almost everywhere equivalence) -measurable random variable satisfying,
for all integrable -measurable . So, the Markov property for is defined by
-almost everywhere, for all times and bounded measurable . Equivalently,
for all times , bounded measurable and -integrable -measurable .
In particular if is of the form for some sequence of times and measurable then,
This is sufficient to completely determine .
With that brief explanation of Markov processes with respect to sigma-finite measures out of the way, the third property is saying that for each and , then is a Brownian motion stopped at zero and initial distribution density given by . For example, consider the excursions with maximum greater than some positive value K. Since Brownian motion started at a level has probability of hitting level before zero, we see that,
And, hence,
where U is a standard normal random variable defined on some probability space. This can alternatively be computed using (1),
I ignored the requirement that be continuous in when applying (1) but, by smoothing with respect to K, it is straightforward to make this rigorous. So, consider the question of how many drawdowns of height K we can expect before the process hits a level . By what we have just computed, this has the Poisson distribution with parameter .
The transition probabilities for Z can be computed explicitly. For any , we let denote the probability measure on under which Z is a Brownian motion started at x. If satisfies for then, by the reflection principle,
(4)
The second equality holds here because, replacing by after time that it hits zero does not change its distribution, which follows from the strong Markov property and the symmetry of Brownian motion by reflection about zero. As is normal with mean and variance under the measure , this gives the probability density of expressed as a function of variable as,
(5)
This is the transition density for Brownian motion stopped at zero, and is valid over and . As the single point has zero Lebesgue measure, it does not have a well defined probability density there. The probability is, however, given by , so the transition probability is
for all , and measurable bounded functions .
It can be checked that the following necessary consistency conditions for the marginal densities and transition probabilities do indeed hold.
Proof of theorem 1: As standard Brownian motion is strong Markov, the fact that is Poisson is given by theorem 2 of the previous post. Then, by theorem 3 of the same post, the intensity measure satisfies
where is the first time at which Z hits . However, by symmetry, is a Brownian motion started at . Hence, is equal to .
So, choosing any nonnegative with nonzero integral, this implies the existence of a measure on E satisfying,
Since this is independent of the choice of , we have as required.
We now show that Z satisfies the Markov property under . Let be the transition function for Brownian motion stopped at zero, and choose times . If is continuous, then so is . Next, consider any bounded continuous map which is -measurable, and vanishes on paths of length less than . Then,
By the monotone class theorem, this holds with replaced by any bounded -measurable random variable as required.
Next, we look at the distribution of . For any bounded and continuous satisfying then, using (5) for the transition probability of Brownian motion stopped at 0,
using bounded convergence.
All that remains is to show that -almost everywhere, there is a positive time T such that on and elsewhere. By construction and the fact that in the definition we restricted to nonzero drawdowns , there is a positive time T such that Z is nonnegative on and is zero outside of this range, and that for times t arbitrarily close to T. However, we have already shown that Z is distributed as a Brownian motion stopped as soon as it hits zero at any positive time, so that for all . ⬜
As is well known, a standard Brownian motion is invariant under a simple scaling operation. More precisely, for any continuous path and fixed , define the scaled path
For a standard Brownian motion X, then is another standard Brownian motion, as can be verified by noting that it remains centered Gaussian with independent increments and with the same variances. As the Brownian drawdown excursions were constructed from sample paths of a Brownian motion, we expect a similar symmetry to hold for the measure . Since scales the length of each excursion by the factor T, it cannot simply be invariant. Note that the measure for the excursion length given by (3) is not invariant under but, instead, satisfies the symmetry
(6)
and does indeed satisfy the obvious extension of this.
Lemma 2 The measure for Brownian drawdown excursions satisfies the symmetry . That is,
(7)
for all and nonnegative measurable .
Proof: Supposing that X is a standard Brownian motion then, the same is true of and, hence, their drawdown point processes have the same distribution. However, under the map , each drawdown excursion corresponding to running maximum , is mapped to corresponding to running maximum of . Hence,
for nonnegative measurable . Taking expectations gives,
In particular, if is nonnegative and measurable then, replacing by in this identity gives,
as required. ⬜
As a consequence of this, the excursion paths can be expressed as a scaled version of a normalized excursion of unit length. The excursion length and the normalized path are actually independent variables. Furthermore, the measure for the normalized path is a true probability measure, rather than just sigma-finite. To be precise, consider any with length , which we assume to be finite and strictly positive (as is the case for -almost all paths). The normalized path is then,
The excursion is can reconstructed from its length together with the normalized path by scaling, . I use for the paths of unit length and for the restriction of the sigma-algebra to .
Theorem 3 Under the measure on E, the pair are independent. That is, there exists a unique probability measure on such that they have distribution . Explicitly,
(8)
for all nonnegative measurable . Equivalently,
(9)
for all nonnegative measurable .
Proof: Uniqueness is straightforward. If is measurable and nonnegative, then (8) can be applied. Fixing nonnegative measurable with ,
uniquely defines .
Conversely, let us define the measure by the identity above. Note that, substituting in place of T in equation (3) for gives . Hence, for any measurable , the symmetries of and give,
The second equality is replacing by and using (7). The third is replacing T by and using (6), and the fourth is again replacing by and applying (7). Using the definition gives (8).
Finally, I prove the alternative expression (9). Suppose that is measurable. As then, applying (8) gives,
as required. ⬜
Since has the sigma-finite distribution under the excursion measure, the conditional expectation given is well-defined. Theorem 3 can alternatively be stated as
-almost everywhere, for all measurable functions . In a slightly more general form,
for almost all values of T. This is simply (9) expressed using conditional expectations.
Theorem 3 suggests that it may be useful to further decompose the excursions into their length and normalizations, giving a random subset of .
This defines a new point process , over , which I will refer to as the normalized drawdown point process. We can clearly convert back and forth easily between the drawdown point process and the normalized version. Defining,
Then, for any we have and, conversely, for , we have .
Corollary 4 If X is a standard Brownian motion, then the normalized drawdown point process is Poisson with intensity measure .
Proof: As described above, we have and, as is one-to-one and measurable with measurable inverse, the independent increments and Poisson property for carries directly across to and, hence, it is a Poisson point process. The intensity measure is given by,
as required. ⬜
Using the normalized drawdowns has the benefit that it only only involves the rather easily described measures on the nonnegative reals, and a probability measure on the excursion processes. These normalized excursion processes, known as ‘Brownian excursions’, will be looked at in more detail in a later post.



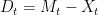
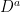
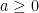


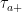
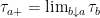



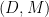
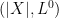
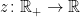
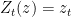

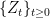
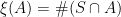
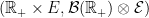

is Poisson with intensity measure
where,
is the standard Lebesgue measure on
.
is a sigma-finite measure on E given by
which vanish on paths of length less than L (some
). The limit is taken over
,
denotes expectation under the measure with respect to which Z is a Brownian motion started at
, and
is the first time at which Z hits 0. This measure satisfies the following properties,
such that
on
and
everywhere else.
, the distribution of
has density
.
![\displaystyle \nu(f) = \lim_{\epsilon\rightarrow0}\epsilon^{-1}{\mathbb E}_\epsilon[f(Z^{\sigma})]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cnu%28f%29+%3D+%5Clim_%7B%5Cepsilon%5Crightarrow0%7D%5Cepsilon%5E%7B-1%7D%7B%5Cmathbb+E%7D_%5Cepsilon%5Bf%28Z%5E%7B%5Csigma%7D%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002)

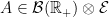

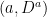
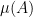

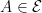



![{Y_t=\xi([0,t]\times A)}](https://s0.wp.com/latex.php?latex=%7BY_t%3D%5Cxi%28%5B0%2Ct%5D%5Ctimes+A%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
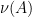

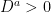
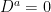
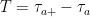
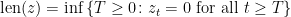
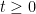



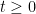


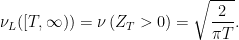
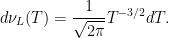

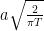
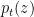

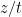
![\displaystyle \nu\left(1_{\{Z_t\not=0\}}f(Z_t)\right)=\frac1t{\mathbb E}\left[\lvert U\rvert f(\lvert U\rvert)\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cnu%5Cleft%281_%7B%5C%7BZ_t%5Cnot%3D0%5C%7D%7Df%28Z_t%29%5Cright%29%3D%5Cfrac1t%7B%5Cmathbb+E%7D%5Cleft%5B%5Clvert+U%5Crvert+f%28%5Clvert+U%5Crvert%29%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
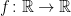
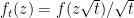
![\displaystyle \nu\left(1_{\{Z_t\not=0\}}f(Z_t)\right)={\mathbb E}\left[\lvert U\rvert f_t(\lvert U\rvert)\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cnu%5Cleft%281_%7B%5C%7BZ_t%5Cnot%3D0%5C%7D%7Df%28Z_t%29%5Cright%29%3D%7B%5Cmathbb+E%7D%5Cleft%5B%5Clvert+U%5Crvert+f_t%28%5Clvert+U%5Crvert%29%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
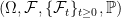
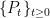
![\displaystyle {\mathbb E}[f(X_{s+t})\vert\mathcal F_s]=P_tf(X_s)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Bf%28X_%7Bs%2Bt%7D%29%5Cvert%5Cmathcal+F_s%5D%3DP_tf%28X_s%29+&bg=ffffff&fg=000000&s=0&c=20201002)
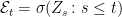




![{{\mathbb E}_\nu[U\vert\mathcal E_s]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D_%5Cnu%5BU%5Cvert%5Cmathcal+E_s%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \nu\left({\mathbb E}_\nu[U\vert\mathcal E_s]V\right)=\nu(UV)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cnu%5Cleft%28%7B%5Cmathbb+E%7D_%5Cnu%5BU%5Cvert%5Cmathcal+E_s%5DV%5Cright%29%3D%5Cnu%28UV%29+&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle {\mathbb E}_\nu[f(Z_{s+t})\vert\mathcal F_s]=P_tf(Z_s)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D_%5Cnu%5Bf%28Z_%7Bs%2Bt%7D%29%5Cvert%5Cmathcal+F_s%5D%3DP_tf%28Z_s%29+&bg=ffffff&fg=000000&s=0&c=20201002)




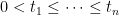




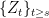





![\displaystyle {\mathbb P}_\nu[\sup_{s\ge t}Z_s\ge K\;\vert\mathcal E_t]=\frac {Z_t}K\wedge1.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+P%7D_%5Cnu%5B%5Csup_%7Bs%5Cge+t%7DZ_s%5Cge+K%5C%3B%5Cvert%5Cmathcal+E_t%5D%3D%5Cfrac+%7BZ_t%7DK%5Cwedge1.+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \begin{aligned} \nu(\{z\in E\colon \sup_t z_t\ge K) &=\frac1K\lim_{t\rightarrow0}\nu(Z_t\wedge K)\\ &=\frac1K\lim_{t\rightarrow0}{\mathbb E}\left[\lvert U\rvert (\lvert U\rvert\wedge (K/\sqrt t)\right]\\ &=\frac1K{\mathbb E}[U^2]=\frac1K. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%5Cnu%28%5C%7Bz%5Cin+E%5Ccolon+%5Csup_t+z_t%5Cge+K%29+%26%3D%5Cfrac1K%5Clim_%7Bt%5Crightarrow0%7D%5Cnu%28Z_t%5Cwedge+K%29%5C%5C+%26%3D%5Cfrac1K%5Clim_%7Bt%5Crightarrow0%7D%7B%5Cmathbb+E%7D%5Cleft%5B%5Clvert+U%5Crvert+%28%5Clvert+U%5Crvert%5Cwedge+%28K%2F%5Csqrt+t%29%5Cright%5D%5C%5C+%26%3D%5Cfrac1K%7B%5Cmathbb+E%7D%5BU%5E2%5D%3D%5Cfrac1K.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \begin{aligned} \nu(\{z\in E\colon \sup_t z_t\ge K) &= \lim_{\epsilon\rightarrow0}\epsilon^{-1}{\mathbb P}_\epsilon[\sup_t Z_t^\sigma\ge K]\\ &= \lim_{\epsilon\rightarrow0}\epsilon^{-1}\frac{\epsilon}{K} =\frac1K. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%5Cnu%28%5C%7Bz%5Cin+E%5Ccolon+%5Csup_t+z_t%5Cge+K%29+%26%3D+%5Clim_%7B%5Cepsilon%5Crightarrow0%7D%5Cepsilon%5E%7B-1%7D%7B%5Cmathbb+P%7D_%5Cepsilon%5B%5Csup_t+Z_t%5E%5Csigma%5Cge+K%5D%5C%5C+%26%3D+%5Clim_%7B%5Cepsilon%5Crightarrow0%7D%5Cepsilon%5E%7B-1%7D%5Cfrac%7B%5Cepsilon%7D%7BK%7D+%3D%5Cfrac1K.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)



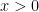
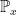

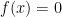

![\displaystyle \begin{aligned} {\mathbb E}_x[f(Z_t^\sigma)] &={\mathbb E}_x[f(Z_t)]-{\mathbb E}_x[1_{\{\sigma\le t\}}f(Z_t)]\\ &={\mathbb E}_x[f(Z_t)]-{\mathbb E}_x[f(-Z_t)]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D_x%5Bf%28Z_t%5E%5Csigma%29%5D+%26%3D%7B%5Cmathbb+E%7D_x%5Bf%28Z_t%29%5D-%7B%5Cmathbb+E%7D_x%5B1_%7B%5C%7B%5Csigma%5Cle+t%5C%7D%7Df%28Z_t%29%5D%5C%5C+%26%3D%7B%5Cmathbb+E%7D_x%5Bf%28Z_t%29%5D-%7B%5Cmathbb+E%7D_x%5Bf%28-Z_t%29%5D.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)






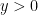
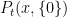



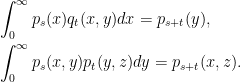

![\displaystyle \int g(a) f(z)d\mu(a,z)=\lim_{\epsilon\rightarrow0}\int_0^\infty g(a)\epsilon^{-1}{\mathbb E}_a[f(a+\epsilon-Z^{\sigma_{a+\epsilon}})]da](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cint+g%28a%29+f%28z%29d%5Cmu%28a%2Cz%29%3D%5Clim_%7B%5Cepsilon%5Crightarrow0%7D%5Cint_0%5E%5Cinfty+g%28a%29%5Cepsilon%5E%7B-1%7D%7B%5Cmathbb+E%7D_a%5Bf%28a%2B%5Cepsilon-Z%5E%7B%5Csigma_%7Ba%2B%5Cepsilon%7D%7D%29%5Dda+&bg=ffffff&fg=000000&s=0&c=20201002)

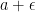

![{{\mathbb E}_a[f(a+\epsilon-Z^{\sigma_{a+\epsilon}})]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D_a%5Bf%28a%2B%5Cepsilon-Z%5E%7B%5Csigma_%7Ba%2B%5Cepsilon%7D%7D%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{{\mathbb E}_\epsilon[f(Z^\sigma)]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D_%5Cepsilon%5Bf%28Z%5E%5Csigma%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \int g(a) f(z)d\mu(a,z)=\lim_{\epsilon\rightarrow0}\lambda(g)\epsilon^{-1}{\mathbb E}_\epsilon[f(Z^{\sigma})].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cint+g%28a%29+f%28z%29d%5Cmu%28a%2Cz%29%3D%5Clim_%7B%5Cepsilon%5Crightarrow0%7D%5Clambda%28g%29%5Cepsilon%5E%7B-1%7D%7B%5Cmathbb+E%7D_%5Cepsilon%5Bf%28Z%5E%7B%5Csigma%7D%29%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle \nu(g)=\lambda(g)^{-1}\int g(a)f(z)d\mu(a,z) = \lim_{\epsilon\rightarrow0}\epsilon^{-1}{\mathbb E}_\epsilon[f(Z^\sigma)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cnu%28g%29%3D%5Clambda%28g%29%5E%7B-1%7D%5Cint+g%28a%29f%28z%29d%5Cmu%28a%2Cz%29+%3D+%5Clim_%7B%5Cepsilon%5Crightarrow0%7D%5Cepsilon%5E%7B-1%7D%7B%5Cmathbb+E%7D_%5Cepsilon%5Bf%28Z%5E%5Csigma%29%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)

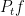

![\displaystyle \begin{aligned} \nu(g(Z)f(Z_{s+t})) &=\lim_{\epsilon\rightarrow0}\epsilon^{-1}{\mathbb E}_\epsilon[g(Z^\sigma)f(Z^\sigma_{s+t})]\\ &=\lim_{\epsilon\rightarrow0}\epsilon^{-1}{\mathbb E}_\epsilon[g(Z^\sigma)P_tf(Z^\sigma_s)]\\ &=\nu(g(Z)P_tf(Z_s)). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%5Cnu%28g%28Z%29f%28Z_%7Bs%2Bt%7D%29%29+%26%3D%5Clim_%7B%5Cepsilon%5Crightarrow0%7D%5Cepsilon%5E%7B-1%7D%7B%5Cmathbb+E%7D_%5Cepsilon%5Bg%28Z%5E%5Csigma%29f%28Z%5E%5Csigma_%7Bs%2Bt%7D%29%5D%5C%5C+%26%3D%5Clim_%7B%5Cepsilon%5Crightarrow0%7D%5Cepsilon%5E%7B-1%7D%7B%5Cmathbb+E%7D_%5Cepsilon%5Bg%28Z%5E%5Csigma%29P_tf%28Z%5E%5Csigma_s%29%5D%5C%5C+%26%3D%5Cnu%28g%28Z%29P_tf%28Z_s%29%29.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
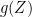

![\displaystyle \begin{aligned} \nu(f(Z_t))) &=\lim_{\epsilon\rightarrow0}\epsilon^{-1}{\mathbb E}_\epsilon[f(Z_t)]\\ &=\lim_{\epsilon\rightarrow0}\int_0^\infty\frac{e^{-\frac1{2t}(x^2+\epsilon^2)}}{\sqrt{2\pi t}}\epsilon^{-1}\left(e^{\frac{\epsilon x}{t}}-e^{-\frac{\epsilon x}{t}}\right)f(x)dx\\ &=\int_0^\infty p_t(x)f(x)dx, \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%5Cnu%28f%28Z_t%29%29%29+%26%3D%5Clim_%7B%5Cepsilon%5Crightarrow0%7D%5Cepsilon%5E%7B-1%7D%7B%5Cmathbb+E%7D_%5Cepsilon%5Bf%28Z_t%29%5D%5C%5C+%26%3D%5Clim_%7B%5Cepsilon%5Crightarrow0%7D%5Cint_0%5E%5Cinfty%5Cfrac%7Be%5E%7B-%5Cfrac1%7B2t%7D%28x%5E2%2B%5Cepsilon%5E2%29%7D%7D%7B%5Csqrt%7B2%5Cpi+t%7D%7D%5Cepsilon%5E%7B-1%7D%5Cleft%28e%5E%7B%5Cfrac%7B%5Cepsilon+x%7D%7Bt%7D%7D-e%5E%7B-%5Cfrac%7B%5Cepsilon+x%7D%7Bt%7D%7D%5Cright%29f%28x%29dx%5C%5C+%26%3D%5Cint_0%5E%5Cinfty+p_t%28x%29f%28x%29dx%2C+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)



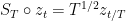
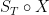


. That is,
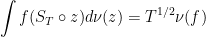



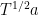
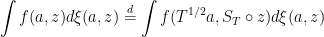









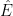

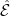
are independent. That is, there exists a unique probability measure
on
such that they have distribution
. Explicitly,
. Equivalently,
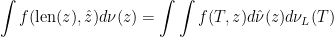





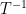

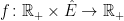



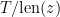




![\displaystyle {\mathbb E}_\nu[f(\hat Z)\vert{\rm len}(Z)] = \hat\nu(f)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D_%5Cnu%5Bf%28%5Chat+Z%29%5Cvert%7B%5Crm+len%7D%28Z%29%5D+%3D+%5Chat%5Cnu%28f%29+&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle {\mathbb E}_\nu[f(Z)\vert{\rm len}(Z)=T]=\int f(S_T\circ z)d\hat\nu(z)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D_%5Cnu%5Bf%28Z%29%5Cvert%7B%5Crm+len%7D%28Z%29%3DT%5D%3D%5Cint+f%28S_T%5Ccirc+z%29d%5Chat%5Cnu%28z%29+&bg=ffffff&fg=000000&s=0&c=20201002)
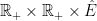


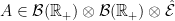



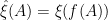
.