Figure 1: Bomb map of the London Blitz, 7 October 1940 to 6 June 1941. Obtained from http://www.bombsight.org (version 1) on 26 October 2020.
The Poisson distribution models numbers of events that occur in a specific period of time given that, at each instant, whether an event occurs or not is independent of what happens at all other times. Examples which are sometimes cited as candidates for the Poisson distribution include the number of phone calls handled by a telephone exchange on a given day, the number of decays of a radio-active material, and the number of bombs landing in a given area during the London Blitz of 1940-41. The Poisson process counts events which occur according to such distributions.
More generally, the events under consideration need not just happen at specific times, but also at specific locations in a space E. Here, E can represent an actual geometric space in which the events occur, such as the spacial distribution of bombs dropped during the Blitz shown in figure 1, but can also represent other quantities associated with the events. In this example, E could represent the 2-dimensional map of London, or could include both space and time so that where, now, F represents the 2-dimensional map and E is used to record both time and location of the bombs. A Poisson point process is a random set of points in E, such that the number that lie within any measurable subset is Poisson distributed. The aim of this post is to introduce Poisson point processes together with the mathematical machinery to handle such random sets.
The choice of distribution is not arbitrary. Rather, it is a result of the independence of the number of events in each region of the space which leads to the Poisson measure, much like the central limit theorem leads to the ubiquity of the normal distribution for continuous random variables and of Brownian motion for continuous stochastic processes. A random finite subset S of a reasonably ‘nice’ (standard Borel) space E is a Poisson point process so long as it satisfies the properties,
If are pairwise-disjoint measurable subsets of E, then the sizes of are independent.
Individual points of the space each have zero probability of being in S. That is, for each .
The proof of this important result will be given in a later post.
We have come across Poisson point processes previously in my stochastic calculus notes. Specifically, suppose that X is a cadlag -valued stochastic process with independent increments, and which is continuous in probability. Then, the set of points over times t for which the jump is nonzero gives a Poisson point process on . See lemma 4 of the post on processes with independent increments, which corresponds precisely to definition 5 given below.
Recall that a nonnegative integer valued random variable N has the Poisson distribution with parameter if
(1)
for all nonnegative integer n. Alternatively, this can be defined by the generating function,
(2)
which holds for all complex x. Simply expanding out the exponentials as power series, and equating the coefficients of powers of x, gives (1). Alternatively, using for any complex t, this can be written as
which is the moment generating function. This distribution is denoted as . It will also be convenient to include the case where infinitely many events occur, so that N has the distribution if . In fact, the generating function (2) still holds in this case, so long as we restrict to the range and interpret and as evaluating to zero. If M and N are independent with the and distributions respectively then,
so that .
The next ingredient for describing Poisson point processes, is that of a random point process. It is straightforward to simply assert that we have a random variable whose values are subsets of a given space E. That is, it takes values in the power set . However, to do probability, it is necessary to have a sigma-algebra on which the probabilities are defined and, furthermore, that this sigma-algebra is generated by reasonably simple subsets of . We will be concerned with finite or, at least, countable random sets and, for this, it is convenient to represent the set by its counting measure. This is a very convenient and flexible method of representing random sets, although there some technical considerations to cover first.
Given a measurable space , then any subset defines a measure by
(3)
for all , where is the indicator function of S. This is the counting measure for the subset S. The integral of a measurable function is simply given by its sum over S,
(4)
Furthermore, if S is countable and separates points, then the counting measure will be sigma-finite. We generalize a bit to allow multisets, so that S can count points of E multiple times. This is necessary in order to be able to model events that can occur simultaneously. A multiset can be identified with an ‘indicator function’ , and is countable if has countable support. Then, for a subset , the intersection denotes the multiset with indicator function , and (3) denotes the sum of over . Similarly, the summation over S in (4) is understood to be with multiplicity, so that it is equal to the sum of over . Sigma-finite measures taking only integer (or infinite) values will be referred to as point measures.
Going in the opposite direction, point measures on a reasonably nice measurable space can be shown to be the counting measure associated with a unique multiset. We consider standard Borel Spaces, which are sufficient for most applications of probability and measure theory. These can be defined as measurable spaces which are Borel isomorphic to a Polish spaceX together with its Borel sigma-algebra . Equivalently, there exists a complete separable metric for E with respect to which is its Borel sigma-algebra. By a theorem of Kuratowski, it is known that all uncountable standard Borel spaces are isomorphic to each other. Hence, up to isomorphism, the following enumerates all standard Borel spaces.
the real numbers together with its standard Borel sigma-algebra.
the natural numbers together with its power set.
a finite sequence together with its power set, for some .
Alternatively, up to isomorphism, we can consider E to be a compact subset of the reals, together with its Borel sets. Specifically, we take in the uncountable case, in the countably infinite case, and in the finite case.
We obtain equivalence between countable multisets and sigma-finite measures taking values in the extended nonnegative integers .
Lemma 1 Let be a sigma-finite -valued measure on Borel space . Then, it is the counting measure of a unique multiset .
Proof: The uniqueness of S is immediate since, if then the indicator function is determined by . Only existence of S remains to be shown.
As is a sigma-finite measure, E can be decomposed into a (finite or countably infinite) sequence of atoms () and a non-atomic set ,
First, must have zero measure. If not, as the measure is integer valued, we could find with nonzero measure minimising . This would then be an atom, contradicting the choice of . So, for any ,
To complete the proof, we just need to show that all atoms can be represented by singletons, so that for a pairwise distinct sequence . This would give
where S is the multiset consisting of the points with multiplicity .
To show that every atom A is indeed given by a singleton, represent the space E as a compact subset of the reals. Then, for each positive integer n, E is contained in a finite union of intervals of the form and, hence, there exists such that has nonzero measure, so is equal to A up to a null set. Taking intersections of this sequence, we obtain a set B contained in each of the sets , so is either a singleton or is empty. By countable additivity, it is equal to A up to a null set, and hence is a singleton as required. ⬜
By lemma 1, we can use random measures to represent random sets. Use to represent the space of measures on a measurable space . This comes with a natural sigma-algebra, which is the smallest sigma-algebra making each of the maps
measurable, for each fixed . With this definition, if we have a probability space then a map is measurable if and only if is a measurable random variable for all .
Definition 2 A random measure on a measurable space , defined with respect to a probability space , is a measurable map
such that, there exists a sequence with and is almost surely finite for each n.
A point process is a random measure taking values in the point measures, so that for all .
Referring back to lemma 1, a point process on a standard Borel space is uniquely expressed as the counting measure of a random multiset in E.
For any random measure as in definition 2, we can speak of its distribution, which is just the probability measure that it defines on the measurable subsets of ,
Given two random measures defined with respect to, possibly different, probability spaces, we write to mean that they are equal in distribution. It is a straightforward application of the pi-system lemma to show that this is equivalent to equality of their finite distributions or, in other words,
(5)
for all finite sequences . In fact, it is sufficient to consider the case where the are pairwise disjoint.
Lemma 3 Let be random measures on a measurable space . Then if and only if (5) holds for all pairwise disjoint finite sequences .
Proof: The ‘only if’ direction is immediate from the definition of equality in distribution. Considering the ‘if’ direction, suppose that (5) holds for all pairwise disjoint sequences . Choosing a finite sequence , we show that (5) holds, even when they are not pairwise disjoint.
Set , and,
for all . These sets are pairwise disjoint so, by the condition of the lemma, and have the same distribution. Furthermore, by finite additivity of measures,
So, equality in distribution (5) holds as claimed.
Next, for finite sequences and Borel measurable sets , define the set
These form a pi-system generating the sigma-algebra on . By equality in distribution (5),
So, by the pi-system lemma, and have the same distribution. ⬜
It follows from this lemma that, to define the distribution of a random measure, it is sufficient to specify the distributions of for pairwise disjoint finite sequences . The independent increments property reduces this further to specifying the distribution of for each .
Definition 4 Let be a random measure on measurable space . We say that it has independent increments if, for each pairwise disjoint finite sequence , then are independent random variables.
Poisson point processes are described by an intensity measure on the underlying space, which specifies the distribution of the random points contained in any measurable subset. If the underlying space is a subset of Euclidean space , then intensity measures can be constructed from locally integrable density functions ,
For example, in the bomb map in figure 1, we would expect to be peaked at the main enemy targets, around central London, and decay away as we move further out from the city.
Definition 5 Let be a sigma-finite measure space. Then, a Poisson point process on with intensity is a point process on satisfying,
has independent increments.
, for each .
The consistency of the finite dimensional distributions follows from the fact that the sum of independent Poisson distributed random variables is itself Poisson, with parameter equal to the sum of the parameters of the random variables. That is, the sum of independent and distributed random variables has the distribution. If are pairwise disjoint measurable subsets of E so that, according to definition 5, the random variables are independently Poisson distributed with parameters then,
has the Poisson distribution with parameter
as required.
As a random variable with the distribution has mean equal to , the intensity measure of a Poisson point process is given simply as . More generally, the expectation of any random measure is itself a (non-random) measure.
Definition 6 If is a random measure on , then its expected value is the measure on defined by
for all .
Countable additivity of expectations and of the random measure immediately gives countable additivity for , so it is a true measure as claimed. By definition of random measures, there exists a sequence whose union covers the space E and such that are almost-surely finite. As their expectations need not be finite, it does not follow that is sigma-finite. However, if are Poisson distributed, then they must also have finite mean, so that is a sigma-finite measure. This shows that a point process is a Poisson point process if and only if,
has independent increments.
has a Poisson distribution for each .
This definition does not require us to start from an intensity measure but, still, the intensity does exist and is given by .
Existence of Poisson Point Processes
Poisson point processes corresponding to a given sigma-finite intensity measure do indeed exist, and are uniquely determined.
Theorem 7 Let be a sigma-finite measure space. Then, there exists a Poisson point process on with intensity , which is unique in distribution.
The proof of this result is the aim of the remainder of the post. Uniqueness follows immediately from the definition and lemma 3, so we only need to prove existence. This will be done with the help of a couple of lemmas. Recall that the sum of independent Poisson random variables is itself Poisson. The same is true of Poisson point processes, even for infinite sums.
Lemma 8 Let be an independent sequence of Poisson point processes on a measurable space , and intensity measures . We suppose that is sigma-finite. Then, is a Poisson point process with intensity .
Proof: For a pairwise disjoint sequence , it just needs to be shown that is a sequence of independent distributed random variables. For this, we compute its joint generating function, which is the expected value of for real .
This makes use of the independence of to extract the product over n from the expectation then, for each n, uses the independence of to extract the product over i. Finally, we substituted in the moment generating function for the random variable . The result is the product of moment generating functions of random variables, as required. ⬜
There is a straightforward method of constructing Poisson point processes with finite intensity measure. We start with an IID sequence of random variables taking values in the space E. Then, consider the random multiset , where N is Poisson independently of the .
Lemma 9 Let be a probability space and be a nonnegative real. Let N be a distributed random variable defined on some probability space and, independent of , let be an IID sequence of E-valued random variables with distribution .
Then,
for all , defines a Poisson point process on with intensity measure , with respect to the probability space .
Proof: As in the proof of lemma 8, for a pairwise disjoint sequence , it just needs to be shown that is a sequence of independent distributed random variables. Again, we do this by computing the joint generating function. For real numbers , start by taking expectations conditional on N.
By independence of the sequence and N, the expectation conditional on N is just the same as the unconditioned expectation. Furthermore, as are pairwise disjoint, the product is equal to giving,
Taking the expectation of this and substituting in the generating function for the distribution for N,
This is the product of generating functions of distributions, as required. ⬜
Combining the two lemmas above provides us with Poisson point measures for arbitrary sigma-finite intensity measures.
Proof of Theorem 7: Start with the case where is a finite measure space. As the case where is zero is trivial, we suppose that . Then, is a probability measure on . By taking the product of the distribution on and an infinite product of , we obtain a probability space on which there are defined a random variable N and, independently, an IID sequence of E-valued random variables with distribution . Lemma 9 then provides us with a Poisson point process with intensity .
Now, suppose that is a sigma-finite measure. Then, we can write for finite measures on . By what we have shown above, there exists Poisson point processes with intensity , possibly defined with respect to different probability spaces. Taking the product over n of these probability spaces, we can suppose that are all defined with respect the same probability space and are independent. Lemma 8 says that is a Poisson point process with intensity . ⬜


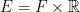
are pairwise-disjoint measurable subsets of E, then the sizes of
are independent.
for each
.

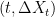



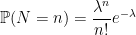
![\displaystyle {\mathbb E}[x^N]=e^{-\lambda(1-x)},](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Bx%5EN%5D%3De%5E%7B-%5Clambda%281-x%29%7D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle {\mathbb E}[e^{-t N}]=e^{-\lambda(1-e^{-t})},](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Be%5E%7B-t+N%7D%5D%3De%5E%7B-%5Clambda%281-e%5E%7B-t%7D%29%7D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)

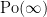


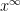


![\displaystyle \begin{aligned} {\mathbb E}[x^{M+N}] &={\mathbb E}[x^M]{\mathbb E}[x^N]\\ &=e^{-\lambda(1-x)}e^{-\mu(1-x)}\\ &=e^{-(\lambda+\mu)(1-x)}, \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5Bx%5E%7BM%2BN%7D%5D+%26%3D%7B%5Cmathbb+E%7D%5Bx%5EM%5D%7B%5Cmathbb+E%7D%5Bx%5EN%5D%5C%5C+%26%3De%5E%7B-%5Clambda%281-x%29%7De%5E%7B-%5Cmu%281-x%29%7D%5C%5C+%26%3De%5E%7B-%28%5Clambda%2B%5Cmu%29%281-x%29%7D%2C+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)



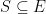

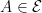
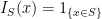
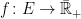



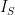

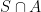


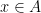

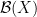
together with its power set.
together with its power set, for some
.
![{E=[0,1]}](https://s0.wp.com/latex.php?latex=%7BE%3D%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)



be a sigma-finite
-valued measure on Borel space
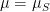
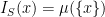
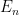

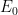


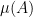




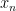
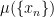

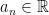




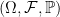


on a measurable space
with
and
is almost surely finite for each n.
for all


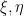


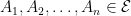
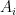
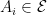




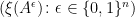

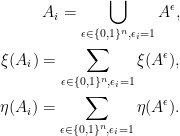

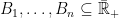

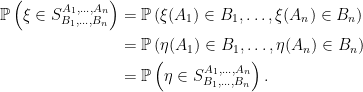


are independent random variables.

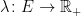


be a sigma-finite measure space. Then, a Poisson point process
, for each

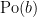


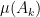



![{\mu(A)={\mathbb E}[\xi(A)]}](https://s0.wp.com/latex.php?latex=%7B%5Cmu%28A%29%3D%7B%5Cmathbb+E%7D%5B%5Cxi%28A%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
is the measure on
![\displaystyle \mu(A)={\mathbb E}[\xi(A)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmu%28A%29%3D%7B%5Cmathbb+E%7D%5B%5Cxi%28A%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002)

be an independent sequence of Poisson point processes on a measurable space
. We suppose that
is sigma-finite. Then,
is a Poisson point process with intensity


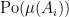

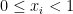
![\displaystyle \begin{aligned} {\mathbb E}\left[\prod\nolimits_ix_i^{\xi(A_i)}\right] &={\mathbb E}\left[\prod\nolimits_i\prod\nolimits_nx_i^{\xi_n(A_i)}\right]\\ &=\prod\nolimits_n{\mathbb E}\left[\prod\nolimits_ix_i^{\xi_n(A_i)}\right]\\ &=\prod\nolimits_n\prod\nolimits_i{\mathbb E}\left[x_i^{\xi_n(A_i)}\right]\\ &=\prod\nolimits_n\prod\nolimits_ie^{-\mu_n(A_i)(1-x_i)}\\ &=\prod\nolimits_ie^{-\mu(A_i)(1-x_i)}\\ \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5Cleft%5B%5Cprod%5Cnolimits_ix_i%5E%7B%5Cxi%28A_i%29%7D%5Cright%5D+%26%3D%7B%5Cmathbb+E%7D%5Cleft%5B%5Cprod%5Cnolimits_i%5Cprod%5Cnolimits_nx_i%5E%7B%5Cxi_n%28A_i%29%7D%5Cright%5D%5C%5C+%26%3D%5Cprod%5Cnolimits_n%7B%5Cmathbb+E%7D%5Cleft%5B%5Cprod%5Cnolimits_ix_i%5E%7B%5Cxi_n%28A_i%29%7D%5Cright%5D%5C%5C+%26%3D%5Cprod%5Cnolimits_n%5Cprod%5Cnolimits_i%7B%5Cmathbb+E%7D%5Cleft%5Bx_i%5E%7B%5Cxi_n%28A_i%29%7D%5Cright%5D%5C%5C+%26%3D%5Cprod%5Cnolimits_n%5Cprod%5Cnolimits_ie%5E%7B-%5Cmu_n%28A_i%29%281-x_i%29%7D%5C%5C+%26%3D%5Cprod%5Cnolimits_ie%5E%7B-%5Cmu%28A_i%29%281-x_i%29%7D%5C%5C+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
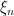


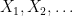


, let
, with respect to the probability space
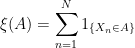

![\displaystyle \begin{aligned} {\mathbb E}\left[\prod\nolimits_ix_i^{\xi(A_i)}\;\Big\vert N\right] &={\mathbb E}\left[\prod\nolimits_i\prod\nolimits_{n=1}^Nx_i^{1_{\{X_n\in A_i\}}}\;\Big\vert N\right]\\ &=\prod\nolimits_{n=1}^N{\mathbb E}\left[\prod\nolimits_i x_i^{1_{\{X_n\in A_i\}}}\;\Big\vert N\right]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5Cleft%5B%5Cprod%5Cnolimits_ix_i%5E%7B%5Cxi%28A_i%29%7D%5C%3B%5CBig%5Cvert+N%5Cright%5D+%26%3D%7B%5Cmathbb+E%7D%5Cleft%5B%5Cprod%5Cnolimits_i%5Cprod%5Cnolimits_%7Bn%3D1%7D%5ENx_i%5E%7B1_%7B%5C%7BX_n%5Cin+A_i%5C%7D%7D%7D%5C%3B%5CBig%5Cvert+N%5Cright%5D%5C%5C+%26%3D%5Cprod%5Cnolimits_%7Bn%3D1%7D%5EN%7B%5Cmathbb+E%7D%5Cleft%5B%5Cprod%5Cnolimits_i+x_i%5E%7B1_%7B%5C%7BX_n%5Cin+A_i%5C%7D%7D%7D%5C%3B%5CBig%5Cvert+N%5Cright%5D.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
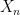


![\displaystyle {\mathbb E}\left[\prod\nolimits_ix_i^{\xi(A_i)}\;\Big\vert N\right]=\left(1-\sum\nolimits_i\mu(A_i)(1-x_i)\right)^N.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Cleft%5B%5Cprod%5Cnolimits_ix_i%5E%7B%5Cxi%28A_i%29%7D%5C%3B%5CBig%5Cvert+N%5Cright%5D%3D%5Cleft%281-%5Csum%5Cnolimits_i%5Cmu%28A_i%29%281-x_i%29%5Cright%29%5EN.+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \begin{aligned} {\mathbb E}\left[\prod\nolimits_ix_i^{\xi(A_i)}\right] &=e^{-\lambda\sum\nolimits_i\mu(A_i)(1-x_i)}\\ &=\prod\nolimits_ie^{-\lambda\mu(A_i)(1-x_i)}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5Cleft%5B%5Cprod%5Cnolimits_ix_i%5E%7B%5Cxi%28A_i%29%7D%5Cright%5D+%26%3De%5E%7B-%5Clambda%5Csum%5Cnolimits_i%5Cmu%28A_i%29%281-x_i%29%7D%5C%5C+%26%3D%5Cprod%5Cnolimits_ie%5E%7B-%5Clambda%5Cmu%28A_i%29%281-x_i%29%7D.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)


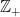




2 thoughts on “Poisson Point Processes”