

Let me ask the following very simple question. Suppose that I toss a pair of identical coins at the same time, then what is the probability of them both coming up heads? There is no catch here, both coins are fair. There are three possible outcomes, both tails, one head and one tail, and both heads. Assuming that it is completely random so that all outcomes are equally likely, then we could argue that each possibility has a one in three chance of occurring, so that the answer to the question is that the probability is 1/3.
Of course, this is wrong! A fair coin has a probability of 1/2 of showing heads and, by independence, standard probability theory says that we should multiply these together for each coin to get the correct answer of 
Anyone with even a basic knowledge of probability should arrive at this answer, so why am I even mentioning the erroneous argument above? Well, these days we have a formalised theory of probability such that properties like the independence of coin tosses are handled with ease. In the past, this was not the case, and even well respected and famous mathematicians have made incorrect arguments similar to the one above to arrive at the wrong answer. For example, one of the most important mathematicians of all time, Gottfried Wilhelm Leibniz (1646–1716), stated that,
…with two dice, it is equally likely to throw twelve points, than to throw eleven; because one or the other can be done in only one manner.
The mistake here is the same as with the coins above. Throwing eleven can actually be done in two ways, by the first dice giving five and the second six, or the other way round. Hence, we are twice as likely to roll eleven than to roll twelve. For another example, Jean le Rond d’Alembert (1717–1783) considered the question,
In two tosses of a fair coin, what is the probability that heads will appear at least once?
The correct answer, as we know, should be 3/4. It is clearly one minus the probability of both coins being tails which, by the arbitrariness of labelling the sides of the coins by ‘heads’ and ‘tails’, is the same as one minus them both being heads. In fact, d’Alembert gave the answer 2/3. The mistake given in his argument is similar to, but subtly different from, the one in the erroneous argument above. He figured that, if the first coin comes up heads, then we do not even need to consider the second coin. So, there are just the three outcomes where the first coin comes up heads, the first coin is tails and the second is heads, and they are both tails. d’Alembert considered these three outcomes to be equally likely. In fact, the case where the first coin is heads actually consists of two possibilities depending on the outcome of the second, giving the source of the error. These examples, and various other mistakes made in elementary probability before the theory was fully developed, are described in the article Errors of Probability in Historical Context by Prakash Gorroochurn (The American Statistician, November 2011, Vol. 65, No. 4).
The errors in the incorrect computation for the probability at the top of this post, and in the argument by Leibniz, are easily explained. The two coins or dice, were assumed to be identical. This means that we cannot distinguish between any particular outcome, and the alternative outcome with their states exchanged. The mistake, then, is to consider these two indistinguishable outcomes as the same event. This leads to under-counting the space of possible outcomes and, together with the assumption that all outcomes have the same probability, gives the incorrect results. Taking the example of tossing two coins, we could always label one of them with a marker pen beforehand so that they can be distinguished. This should not affect the results, but does enable us to distinguish between the two ways in which one coin comes up heads and the other tails. So, the probabilities must be consistent with the situation where the coins can in fact be told apart. This is effectively what we were doing in the corrected argument above where we implicitly labelled one of the coins as the first and the other as the second.
For a bit of fun, we can consider what things would be like if probability really did behave as in the incorrect arguments above. We toss multiple identical coins, where every outcome is equally likely and, furthermore, exchanging any pair of coins gives not just an indistinguishable event but is actually the exact same outcome. The results are rather interesting, as I will explain and, furthermore, this is not just an abstract and useless exercise. Objects which behave in this way are said to follow Bose–Einstein statistics, and is the observed behaviour of certain particles at the quantum level. Such particles are known as bosons, and include photons, gluons, W and Z bosons, and the Higgs boson, as well as various composite particles. Surprisingly, these statistical properties were actually discovered as the result of making a mistake along similar lines to the false argument above showing that the probability of two heads is 1/3. Quoting from the 2007 Ph.D. thesis of Alessandro Michelangeli, Bose–Einstein Condensation: Analysis of problems and rigorous results,
While presenting a lecture at the University of Dhaka on the photoelectric effect and the ultraviolet catastrophe, Bose intended to show his students that the current theory was inadequate, because it predicted results not in accordance with experimental results. During this lecture, Bose committed an error in applying the theory, which unexpectedly gave a prediction that agreed with the experiments. The error was a simple mistake — similar to arguing that flipping two fair coins will produce two heads one third of the time — that would appear obviously wrong to anyone with a basic understanding of statistics. However, the results it predicted agreed with experiment and Bose realized it might not be a mistake at all.
Other fundamental particles, such as electrons, protons and neutrons, are known as fermions and obey Fermi–Dirac statistics, which do not allow any identical pair of particles to be in the exact same state. In this post, I only consider bosons, which are more interesting for the coin tossing examples.
If we toss an identical pair of bosonic coins, then the argument at the top of this post is now correct, and a pair of heads occurs with probability 1/3, instead of 1/4 for ‘classical’ coins. This argument still requires some additional assumptions, namely that the two coins share the exact same state besides whether they are heads or tails, otherwise they could be distinguished from each other. For a real physical example, consider the photons making up a standing wave of an electromagnetic field, or light, which is confined to a chamber. Since they all have the same momentum, as determined by the wavelength, they will only be distinguishable by their polarisation (or, equivalently, spin), which can only be in one of two states. Photons can have either clockwise or anticlockwise circular polarisation.
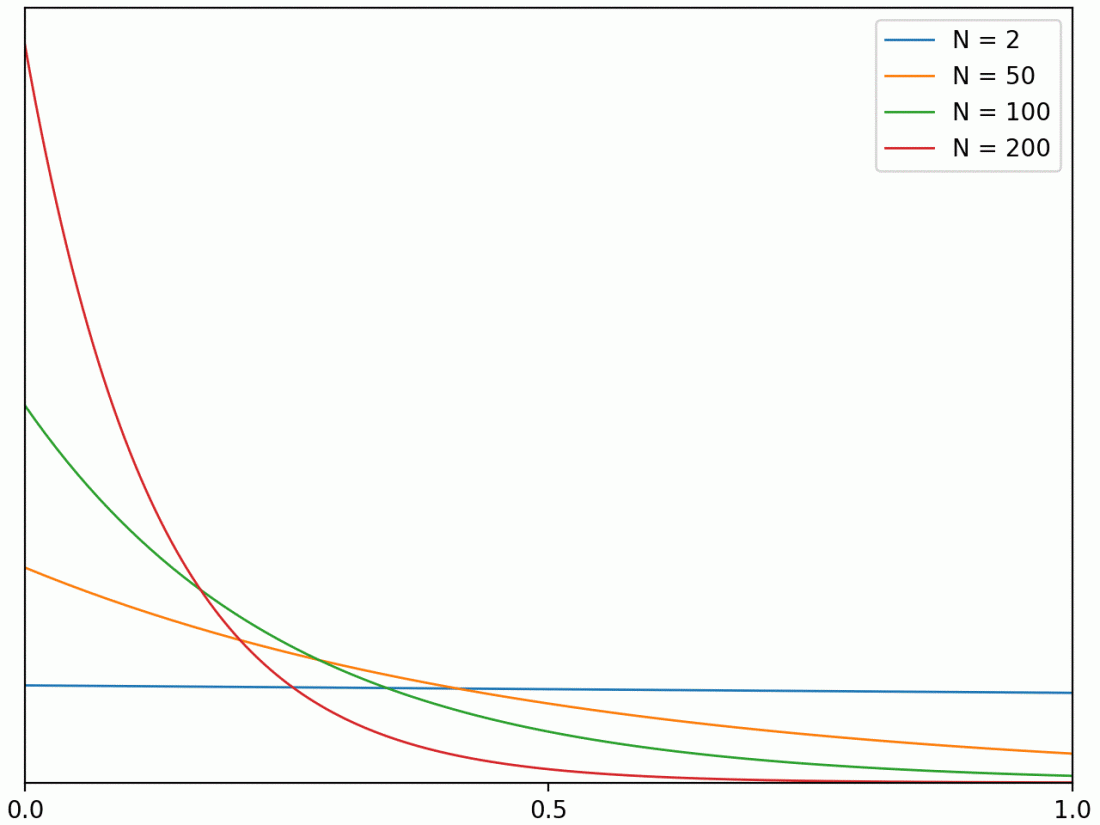
Next, consider tossing a number N of identical bosonic coins. What is the probability distribution for the fraction of heads obtained? Consider the case of m heads, for any 
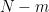
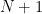





This behaviour of classical coins, where the proportion of heads approaches one half, is exactly as we are used to both mathematically and in practice. A result is that, when we have a system consisting of a very large number of microscopic components, random properties of the individual components are not observed at the large scale. Individual motion of atoms, for example, does not manifest on the macroscopic level, all that is left is the heat coming from their averaged kinetic energy. Similarly, the movement of stock prices is driven by the net behaviour of a large number of individual actors buying and selling, which will usually largely cancel out leaving a small amount of residual random noise.
With Bose–Einstein statistics, things are drastically different. The total number of heads is uniform, regardless of how big a number of coins are used. So, for example, there will be a 20% chance of at least 90% of the coins all being the same way up. Microscopic random effects no longer average out, so these also produce random macroscopic behaviour.
Next, suppose that we have tossed a very large number N of identical coins and select them one by one, and observe if they are heads or tails. By symmetry, the first coin will be heads with probability 1/2. Then, what will be the probability of heads for the second coin, or the third, and so on? For classical coins, the probability is always 1/2, regardless of what has been observed so far. However, this independence does not hold for bosonic coins. As the proportion of heads is uniformly distributed on the unit interval, the probability of the first n being all heads is 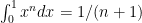

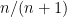

For more discussion of quantum coins, dice (and children!), see the 1999 article Quantum Coins, Dice and Children: Probability and Quantum Statistics by Chi-Keung Chow and Thomas D. Cohen.
Biased Coins
Things get even more interesting if we consider biased coins, where a single coin toss gives a head with probability 




The situation is quite different for biased bosonic coins. Since, we no longer have the simple symmetry argument used above whereby all outcomes have the same probability, it is not immediately obvious what the probabilities are. Consider tossing N coins and look at the outcomes corresponding to m heads. Classically, the number of ways that this can occur is equal to the number of ways of choosing m from a collection of N objects, given by the binomial coefficient 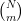


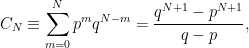 |
which is strictly less than one. To fix this, we normalise the distribution by scaling with this constant, giving the probability of m heads as 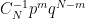






For biased bosonic coins with 
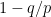
This behaviour is, for example, seen in Bose–Einstein condensates and is responsible for their various strange properties, such as quantum vortices and superfluidity. All, or almost all, of the particles in the condensate tend to fall into the same low energy state.

The following phenomenon might occur in some mathematical model of quantum coin tossing.
When two classical coins are tossed, and the first coin measured to be heads, and the second coin measured to be tails, measuring the first coin again gives heads with probability 1.
When two quantum coins are tossed, and the first coin measured to be heads, and the second coin measured to be tails, measuring the first coin again gives tails with non-zero probability.
Hi J.P.,
Hmm, do you have a reference for that? It sounds like you are supposing that measuring the state of the different coins are non-commuting measurements. That’s not what I was assuming in this post. I was just assuming that they behave according to Bose-Einstein statistics. E.g., measuring the polarization of different photons, which are commuting observables (or, measuring the spins of any identical set of bosons)
Maybe I read past the line “*some* mathematical model of quantum coin tossing” a bit quickly. No doubt there does exist such models, but it probably requires some interaction between the coins so that the measurements do not commute.
It seems that you expect to take a 3-dimensional subspace Sym(ℂ²) of ℂ² ⊗ ℂ², and have two commuting operators on this space with common eigenvectors marked as (Head,Head), (Head,Tail), (Tail,Head) and (Tail, Tail)? I do not see how this can happen: there are at most 3 common eigenvectors.
Or maybe I do not understand what do you mean by “measuring the FIRST coin”, “measuring the SECOND coin”…
Hi Ilya, not sure if this question is aimed at me or JP McCarthy but, in my post, when I refer to “first” and “second” coins, this only applies to the classical situation, not quantum bosonic coins.
Sorry to be responding a million years later. Absolutely I was talking about non-commuting measurements. The comment was made while I was starting to put some ideas together for this: https://arxiv.org/abs/2104.02817
George, indeed
> “when I refer … only applies to the classical situation, ”
— but since you DID NOT objects to the J.P.’s
> “… the first coin measured …”
I think my comment was in fact addressed to both of you!
@ J.P.:
I cannot imagine any situation (with quantum bosonic coins) where what you wrote can make any sense. (It is not surprising that people prefer to use creation and annihilation operators to avoid such linguistic “black holes”.)
Could you explain what you meant in more palatable terms?