The normal (or Gaussian) distribution is ubiquitous throughout probability theory for various reasons, including the central limit theorem, the fact that it is realistic for many practical applications, and because it satisfies nice properties making it amenable to mathematical manipulation. It is, therefore, one of the first continuous distributions that students encounter at school. As such, it is not something that I have spent much time discussing on this blog, which is usually concerned with more advanced topics. However, there are many nice properties and methods that can be performed with normal distributions, greatly simplifying the manipulation of expressions in which it is involved. While it is usually possible to ignore these, and instead just substitute in the density function and manipulate the resulting integrals, that approach can get very messy. So, I will describe some of the basic results and ideas that I use frequently.
Throughout, I assume the existence of an underlying probability space 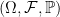 . Recall that a real-valued random variable X has the standard normal distribution if it has a probability density function given by,
. Recall that a real-valued random variable X has the standard normal distribution if it has a probability density function given by,
For it to function as a probability density, it is necessary that it integrates to one. While it is not obvious that the normalization factor 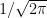 is the correct value for this to be true, it is the one fact that I state here without proof. Wikipedia does list a couple of proofs, which can be referred to. By symmetry,
is the correct value for this to be true, it is the one fact that I state here without proof. Wikipedia does list a couple of proofs, which can be referred to. By symmetry, 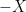 and
and  have the same distribution, so that they have the same mean and, therefore,
have the same distribution, so that they have the same mean and, therefore, ![{{\mathbb E}[X]=0}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BX%5D%3D0%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
The derivative of the density function satisfies the useful identity
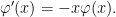 |
(1) |
This allows us to quickly verify that standard normal variables have unit variance, by an application of integration by parts.
Another identity satisfied by the normal density function is,
 |
(2) |
This enables us to prove the following very useful result. In fact, it is difficult to overstate how helpful this result can be. I make use of it frequently when manipulating expressions involving normal variables, as it significantly simplifies the calculations. It is also easy to remember, and simple to derive if needed.
Theorem 1 Let X be standard normal and 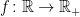 be measurable. Then, for all
be measurable. Then, for all 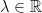 ,
,
![\displaystyle \begin{aligned} {\mathbb E}[e^{\lambda X}f(X)] &={\mathbb E}[e^{\lambda X}]{\mathbb E}[f(X+\lambda)]\\ &=e^{\frac{\lambda^2}{2}}{\mathbb E}[f(X+\lambda)]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5Be%5E%7B%5Clambda+X%7Df%28X%29%5D+%26%3D%7B%5Cmathbb+E%7D%5Be%5E%7B%5Clambda+X%7D%5D%7B%5Cmathbb+E%7D%5Bf%28X%2B%5Clambda%29%5D%5C%5C+%26%3De%5E%7B%5Cfrac%7B%5Clambda%5E2%7D%7B2%7D%7D%7B%5Cmathbb+E%7D%5Bf%28X%2B%5Clambda%29%5D.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
(3) |
Continue reading “Manipulating the Normal Distribution” →



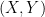
![\displaystyle \begin{aligned} {\mathbb E}\left[e^{iaX+ibY}\right] &=e^{ia\mu_X+ib\mu_Y-\frac12(a^2\sigma_X^2+2abc+b^2\sigma_Y^2)}\\ &=e^{-abc}{\mathbb E}\left[e^{iaX}\right]{\mathbb E}\left[e^{ibY}\right] \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7BiaX%2BibY%7D%5Cright%5D+%26%3De%5E%7Bia%5Cmu_X%2Bib%5Cmu_Y-%5Cfrac12%28a%5E2%5Csigma_X%5E2%2B2abc%2Bb%5E2%5Csigma_Y%5E2%29%7D%5C%5C+%26%3De%5E%7B-abc%7D%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7BiaX%7D%5Cright%5D%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7BibY%7D%5Cright%5D+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
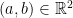
is not normal.
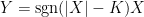
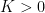
![{{\mathbb E}[XY]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BXY%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
 to be jointly normal? We could simply require each of them to be normal, but this says very little about their joint distribution and is not much help in handling expressions involving more than one of the
to be jointly normal? We could simply require each of them to be normal, but this says very little about their joint distribution and is not much help in handling expressions involving more than one of the  at once. In case that the random variables are independent, the following result is a very useful property of the normal distribution. All random variables in this post will be real-valued, except where stated otherwise, and we assume that they are defined with respect to some underlying probability space
at once. In case that the random variables are independent, the following result is a very useful property of the normal distribution. All random variables in this post will be real-valued, except where stated otherwise, and we assume that they are defined with respect to some underlying probability space 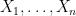 is a sequence of independent normal random variables and
is a sequence of independent normal random variables and 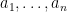 are real numbers, then
are real numbers, then 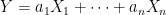 is normal. Let us suppose that
is normal. Let us suppose that 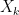 has mean
has mean  and variance
and variance  . Then, the characteristic function of Y can be computed using the independence property and the
. Then, the characteristic function of Y can be computed using the independence property and the ![\displaystyle \begin{aligned} {\mathbb E}\left[e^{i\lambda Y}\right] &={\mathbb E}\left[\prod_ke^{i\lambda a_k X_k}\right] =\prod_k{\mathbb E}\left[e^{i\lambda a_k X_k}\right]\\ &=\prod_ke^{-\frac12\lambda^2a_k^2\sigma_k^2+i\lambda a_k\mu_k} =e^{-\frac12\lambda^2\sigma^2+i\lambda\mu} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7Bi%5Clambda+Y%7D%5Cright%5D+%26%3D%7B%5Cmathbb+E%7D%5Cleft%5B%5Cprod_ke%5E%7Bi%5Clambda+a_k+X_k%7D%5Cright%5D+%3D%5Cprod_k%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7Bi%5Clambda+a_k+X_k%7D%5Cright%5D%5C%5C+%26%3D%5Cprod_ke%5E%7B-%5Cfrac12%5Clambda%5E2a_k%5E2%5Csigma_k%5E2%2Bi%5Clambda+a_k%5Cmu_k%7D+%3De%5E%7B-%5Cfrac12%5Clambda%5E2%5Csigma%5E2%2Bi%5Clambda%5Cmu%7D+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
 and
and  . This is the characteristic function of a normal random variable with mean
. This is the characteristic function of a normal random variable with mean  and variance
and variance  . ⬜
. ⬜ of real-valued random variables is multivariate normal (or joint normal) if and only if all of its finite linear combinations are normal.
of real-valued random variables is multivariate normal (or joint normal) if and only if all of its finite linear combinations are normal. 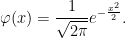
![\displaystyle \begin{aligned} {\mathbb E}[X^2] &=\int x^2\varphi(x)dx\\ &= -\int x\varphi^\prime(x)dx\\ &=\int\varphi(x)dx-[x\varphi(x)]_{-\infty}^\infty=1 \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5BX%5E2%5D+%26%3D%5Cint+x%5E2%5Cvarphi%28x%29dx%5C%5C+%26%3D+-%5Cint+x%5Cvarphi%5E%5Cprime%28x%29dx%5C%5C+%26%3D%5Cint%5Cvarphi%28x%29dx-%5Bx%5Cvarphi%28x%29%5D_%7B-%5Cinfty%7D%5E%5Cinfty%3D1+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
