
I looked at normal random variables in an earlier post but, what does it mean for a sequence of real-valued random variables 

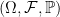
Lemma 1 Linear combinations of independent normal random variables are again normal.
Proof: More precisely, if 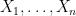
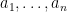
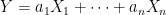
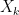


![\displaystyle \begin{aligned} {\mathbb E}\left[e^{i\lambda Y}\right] &={\mathbb E}\left[\prod_ke^{i\lambda a_k X_k}\right] =\prod_k{\mathbb E}\left[e^{i\lambda a_k X_k}\right]\\ &=\prod_ke^{-\frac12\lambda^2a_k^2\sigma_k^2+i\lambda a_k\mu_k} =e^{-\frac12\lambda^2\sigma^2+i\lambda\mu} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7Bi%5Clambda+Y%7D%5Cright%5D+%26%3D%7B%5Cmathbb+E%7D%5Cleft%5B%5Cprod_ke%5E%7Bi%5Clambda+a_k+X_k%7D%5Cright%5D+%3D%5Cprod_k%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7Bi%5Clambda+a_k+X_k%7D%5Cright%5D%5C%5C+%26%3D%5Cprod_ke%5E%7B-%5Cfrac12%5Clambda%5E2a_k%5E2%5Csigma_k%5E2%2Bi%5Clambda+a_k%5Cmu_k%7D+%3De%5E%7B-%5Cfrac12%5Clambda%5E2%5Csigma%5E2%2Bi%5Clambda%5Cmu%7D+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
where we have set 



The definition of joint normal random variables will include the case of independent normals, so that any linear combination is also normal. We use use this result as the defining property for the general multivariate normal case.
Definition 2 A collection
of real-valued random variables is multivariate normal (or joint normal) if and only if all of its finite linear combinations are normal.
Lemma 1 immediately shows that any independent set of normals is joint normal.
Lemma 3 Any collection
It also follows quickly from the definition that any collection of linear combinations of joint normals is itself joint normal.
Lemma 4 Let
of finite linear combinations of the
Proof: Any finite linear combination of the 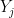
A natural question to ask is whether, for a collection of two or more normal random variables, should we expect them to be joint normal? It does not take much consideration to see that this need not be the case, and that joint normality is a very special situation. Consider a pair of random variables X,Y with probability density function 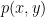


![\displaystyle \begin{aligned} {\rm Cov}(X,Y) &={\mathbb E}[(X-{\mathbb E} X)(Y-{\mathbb E} Y)]\\ &={\mathbb E}[XY]-{\mathbb E}[X]{\mathbb E}[Y] \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Crm+Cov%7D%28X%2CY%29+%26%3D%7B%5Cmathbb+E%7D%5B%28X-%7B%5Cmathbb+E%7D+X%29%28Y-%7B%5Cmathbb+E%7D+Y%29%5D%5C%5C+%26%3D%7B%5Cmathbb+E%7D%5BXY%5D-%7B%5Cmathbb+E%7D%5BX%5D%7B%5Cmathbb+E%7D%5BY%5D+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
is zero. For joint normal random variables, this condition is sufficient to ensure that they are independent, so the example also demonstrates how the joint normal property is required here.
Example 1 A pair of standard normal random variables X,Y which have zero covariance, but
is not normal.
Although there is considerable flexibity in constructing random variables with properties as in the example, consider the following. Let X be standard normal and set 

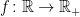
![\displaystyle \begin{aligned} {\mathbb E}[f(Y)] &={\mathbb E}[1_{\{\lvert X\rvert \ge K\}}f(X)]+{\mathbb E}[1_{\{\lvert X\rvert < K\}}f(-X)]\\ &={\mathbb E}[1_{\{\lvert X\rvert \ge K\}}f(X)]+{\mathbb E}[1_{\{\lvert X\rvert < K\}}f(X)]\\ &={\mathbb E}[f(X)]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5Bf%28Y%29%5D+%26%3D%7B%5Cmathbb+E%7D%5B1_%7B%5C%7B%5Clvert+X%5Crvert+%5Cge+K%5C%7D%7Df%28X%29%5D%2B%7B%5Cmathbb+E%7D%5B1_%7B%5C%7B%5Clvert+X%5Crvert+%3C+K%5C%7D%7Df%28-X%29%5D%5C%5C+%26%3D%7B%5Cmathbb+E%7D%5B1_%7B%5C%7B%5Clvert+X%5Crvert+%5Cge+K%5C%7D%7Df%28X%29%5D%2B%7B%5Cmathbb+E%7D%5B1_%7B%5C%7B%5Clvert+X%5Crvert+%3C+K%5C%7D%7Df%28X%29%5D%5C%5C+%26%3D%7B%5Cmathbb+E%7D%5Bf%28X%29%5D.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
On the other hand, 

![\displaystyle {\mathbb E}[XY]={\mathbb E}[{\rm sgn}(\lvert X\rvert - K)X^2].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5BXY%5D%3D%7B%5Cmathbb+E%7D%5B%7B%5Crm+sgn%7D%28%5Clvert+X%5Crvert+-+K%29X%5E2%5D.+&bg=ffffff&fg=000000&s=0&c=20201002) |
Since this is continuous in K, tends to -1 as K goes to infinity, and equals 1 at 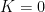
Rather than arbitrary collections of real-valued variables, we can also consider random variables taking values in 
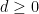

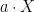
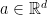
Definition 5 An
is multivariate normal (or, joint normal) if its components
Multivariate normal distributions can be conveniently characterized by their mean ![{\mu={\mathbb E}[X]}](https://s0.wp.com/latex.php?latex=%7B%5Cmu%3D%7B%5Cmathbb+E%7D%5BX%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
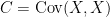
![{\mu_k={\mathbb E}[X_k]}](https://s0.wp.com/latex.php?latex=%7B%5Cmu_k%3D%7B%5Cmathbb+E%7D%5BX_k%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
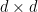
![\displaystyle \begin{aligned} {\rm Cov}(X,X)_{jk} &={\rm Cov}(X_j,X_k)\\ &={\mathbb E}[X_jX_k]-\mu_j\mu_k. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Crm+Cov%7D%28X%2CX%29_%7Bjk%7D+%26%3D%7B%5Crm+Cov%7D%28X_j%2CX_k%29%5C%5C+%26%3D%7B%5Cmathbb+E%7D%5BX_jX_k%5D-%5Cmu_j%5Cmu_k.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
Similarly, expressing this with matrix algebra,
![\displaystyle \begin{aligned} {\rm Cov}(X,X) &={\mathbb E}[(X-\mu)(X^T-\mu^T)]\\ &={\mathbb E}[XX^T]-\mu\mu^T. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Crm+Cov%7D%28X%2CX%29+%26%3D%7B%5Cmathbb+E%7D%5B%28X-%5Cmu%29%28X%5ET-%5Cmu%5ET%29%5D%5C%5C+%26%3D%7B%5Cmathbb+E%7D%5BXX%5ET%5D-%5Cmu%5Cmu%5ET.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
For vectors 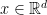


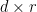
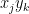

Theorem 6 If X is d-dimensional multivariate normal, then there exists a unique
and positive semidefinite
such that,
These uniquely determine the distribution of X, which will be denoted by
. Furthermore, for any
.
![\displaystyle \begin{aligned} &\mu={\mathbb E}[X],\\ &C={\rm Cov}(X,X). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%26%5Cmu%3D%7B%5Cmathbb+E%7D%5BX%5D%2C%5C%5C+%26C%3D%7B%5Crm+Cov%7D%28X%2CX%29.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: As the components of X are normal and, hence, square-integrable, the mean and covariance matrix are well-defined. By definition of joint normality,
![\displaystyle \begin{aligned} {\mathbb E}[a\cdot X] &=a\cdot{\mathbb E}[X]=a\cdot\mu,\\ {\rm Var}(a\cdot X) &={\rm Cov}(a\cdot X,a\cdot X)\\ &={\mathbb E}[a^TXX^Ta]-{\mathbb E}[a^T X]{\mathbb E}[X^Ta]\\ &=a^TCa. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5Ba%5Ccdot+X%5D+%26%3Da%5Ccdot%7B%5Cmathbb+E%7D%5BX%5D%3Da%5Ccdot%5Cmu%2C%5C%5C+%7B%5Crm+Var%7D%28a%5Ccdot+X%29+%26%3D%7B%5Crm+Cov%7D%28a%5Ccdot+X%2Ca%5Ccdot+X%29%5C%5C+%26%3D%7B%5Cmathbb+E%7D%5Ba%5ETXX%5ETa%5D-%7B%5Cmathbb+E%7D%5Ba%5ET+X%5D%7B%5Cmathbb+E%7D%5BX%5ETa%5D%5C%5C+%26%3Da%5ETCa.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
So, 

The proof that the mean and covariance matrix uniquely determines the distribution of a multivariate normal made use of the following simple result concerning the distribution of random d-dimensional vectors. This is not specific to normal distributions and, as it is an interesting result in its own right, I state it as a lemma here.
Lemma 7 Let X be an
Proof: We use the fact that the distribution of X is uniquely determined by its characteristic function
![\displaystyle a\mapsto{\mathbb E}[e^{ia\cdot X}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++a%5Cmapsto%7B%5Cmathbb+E%7D%5Be%5E%7Bia%5Ccdot+X%7D%5D+&bg=ffffff&fg=000000&s=0&c=20201002) |
as 
Linear transformations of multivariate normals are themselves multivariate normals. This follows easily from the definition and is just an alternative statement to lemma 4 above.
Lemma 8 Let X be a d-dimensional multivariate normal and, for some
, let
and
. Then,
is r-dimensional multivariate normal.
Specifically, if
then
.
Proof: For any 
 |
which, by definition of the multivariate normal, is normal. Hence, Y is multivariate normal.
The mean of Y is, using linearity of expectations,
![\displaystyle {\mathbb E}[Y]=A{\mathbb E}[X]+b=A\mu+b](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5BY%5D%3DA%7B%5Cmathbb+E%7D%5BX%5D%2Bb%3DA%5Cmu%2Bb+&bg=ffffff&fg=000000&s=0&c=20201002) |
and, the covariance matrix is given by,
 |
as required. ⬜
The moment generating function of multivariate normals can be computed, generalizing the result for the normal distribution in the earlier post.
Lemma 9 If X has the d-dimensional
is integrable for all
and,
(1)
![\displaystyle {\mathbb E}\left[e^{a\cdot X}\right]=e^{\frac12 a^TCa+a\cdot \mu}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7Ba%5Ccdot+X%7D%5Cright%5D%3De%5E%7B%5Cfrac12+a%5ETCa%2Ba%5Ccdot+%5Cmu%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: For 
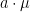
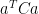
Next, for 
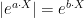

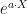
![{{\mathbb E}[Xe^{a\cdot X}]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BXe%5E%7Ba%5Ccdot+X%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Taking
![\displaystyle {\mathbb E}\left[e^{ia\cdot X}\right]=e^{-\frac12a^TCa+ia^T\mu}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7Bia%5Ccdot+X%7D%5Cright%5D%3De%5E%7B-%5Cfrac12a%5ETCa%2Bia%5ET%5Cmu%7D.+&bg=ffffff&fg=000000&s=0&c=20201002) |
(2) |
We obtain the following simple characterisation of joint normals as those distributions whose log-characteristic function is quadratic, extending corollary 6 of the previous post to the multivariate case. Here, a function 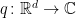
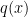

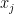
Lemma 10 An
, for a quadratic
.
Proof: By (2), the characteristic function is of the required form when X is joint normal. Suppose, conversely, that the characteristic function is of the required form. Then, for any fixed
![\displaystyle {\mathbb E}\left[e^{i\lambda a\cdot X}\right]=e^{q(\lambda a)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Cleft%5Be%5E%7Bi%5Clambda+a%5Ccdot+X%7D%5Cright%5D%3De%5E%7Bq%28%5Clambda+a%29%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
for 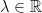
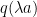

As noted in lemma 3 above, collections of independent normal random variables are joint normal. In particular, we can consider a random vector
Lemma 11 For an
- The components
, where
is the
for all
- X has characteristic function
.
- X has the probability density,
over
If either (and then, all) of these conditions hold then we say that X has the standard d-dimensional normal distribution.

Proof: The equivalence of each of the listed statements is straightforward, and can be proved in many ways. For example:
1 ⇒ 2: Lemma 3 says that X is joint normal. As its components have zero mean and unit variance and, by independence, its covariances are ![{{\mathbb E}[X_jX_k]=0}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BX_jX_k%5D%3D0%7D&bg=ffffff&fg=000000&s=0&c=20201002)
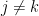
2 ⇒ 3: By theorem 6, 
3 ⇒ 4: The required identity follows immediately from the characteristic function of the normal random variable
4 ⇒ 1: This follows immediately from the converse statement which has already been proved, as probability distributions are uniquely determined by their characteristic functions.
1 ⇒ 5: As 
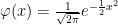
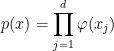 |
as required.
5 ⇒ 1: This follows immediately from the converse statement which has already been proved, as probability distributions are uniquely determined by their density functions. ⬜
Lemmas 8 and 11 open up a straightforward method of generating 





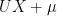
Theorem 12 For any
The multivariate normal distribution is sometimes defined by its probability density function, although this does require the covariance matrix to be nonsingular.
Lemma 13 For
over
is the determinant of C.

Proof: Nonsingularity is required since, otherwise, we would have 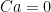
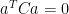
So, supposing that C is nonsingular, we write 


![\displaystyle \begin{aligned} {\mathbb E}[f(X)] &={\mathbb E}[f(UY+\mu)]\\ &=(2\pi)^{-\frac n2}\int f(Uy+\mu)e^{-\frac12\lVert y\rVert^2}dy. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5Bf%28X%29%5D+%26%3D%7B%5Cmathbb+E%7D%5Bf%28UY%2B%5Cmu%29%5D%5C%5C+%26%3D%282%5Cpi%29%5E%7B-%5Cfrac+n2%7D%5Cint+f%28Uy%2B%5Cmu%29e%5E%7B-%5Cfrac12%5ClVert+y%5CrVert%5E2%7Ddy.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
Making the substitution 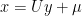


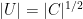
![\displaystyle {\mathbb E}[f(X)]=(2\pi)^{-\frac n2}\lvert C\rvert^{-\frac12}\int f(y)e^{-\frac12(x-\mu)^TC^{-1}(x-\mu)}dy](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Bf%28X%29%5D%3D%282%5Cpi%29%5E%7B-%5Cfrac+n2%7D%5Clvert+C%5Crvert%5E%7B-%5Cfrac12%7D%5Cint+f%28y%29e%5E%7B-%5Cfrac12%28x-%5Cmu%29%5ETC%5E%7B-1%7D%28x-%5Cmu%29%7Ddy+&bg=ffffff&fg=000000&s=0&c=20201002) |
as required. ⬜
Let us now move back to the subject of arbitrary collections of joint normal random variables. Theorem 6 can be generalized, stating that the distribution of a joint normal collection of variables is uniquely determined by its means and covariances. Before stating this, let me clarify what is meant by the distribution of such a collection. We could simply consider the finite distributions, which is simply the distribution of each finite subset of the collection. We can be a bit more sophisticated, but it works out the same.
Let us consider a collection 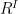

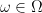

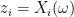

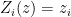
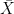
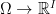



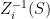
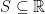
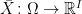

![\displaystyle \mu(f)={\mathbb E}[f(\bar Z)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmu%28f%29%3D%7B%5Cmathbb+E%7D%5Bf%28%5Cbar+Z%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002) |
for all measurable 





Theorem 14 The distribution of a joint normal collection of random variables
and covariances
over
.
Proof: Given any finite sequence ![{{\mathbb E}[X_{i_k}]=\mu_{i_k}}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BX_%7Bi_k%7D%5D%3D%5Cmu_%7Bi_k%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
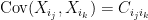
For example, Brownian motion is a joint normal process, so its distribution is determined by the covariances.
Example 2 Standard Brownian motion
is a continuous stochastic process which is jointly normal with zero mean and covariances,
![\displaystyle {\mathbb E}[X_sX_t]=s\wedge t.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5BX_sX_t%5D%3Ds%5Cwedge+t.+&bg=ffffff&fg=000000&s=0&c=20201002)
By definition, for times 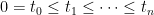
 |
are independent normals and, as the process values 
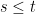
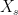

![\displaystyle {\mathbb E}[X_sX_t]={\mathbb E}[X_s^2]+{\mathbb E}[X_s(X_t-X_s)]=s+0=s\wedge t.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5BX_sX_t%5D%3D%7B%5Cmathbb+E%7D%5BX_s%5E2%5D%2B%7B%5Cmathbb+E%7D%5BX_s%28X_t-X_s%29%5D%3Ds%2B0%3Ds%5Cwedge+t.+&bg=ffffff&fg=000000&s=0&c=20201002) |
These means and covariances are sufficient to uniquely determine all finite distributions of Brownian motion, by theorem 14. The additional constraint that its sample paths 
We note that the covariances 

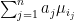

 |
This inequality is expressed by saying that C is positive semidefinite, and is sufficient to guarantee the existence of the joint normal distribution.
Theorem 15 Let
and
be real numbers such that C is symmetric and positive semidefinite. Then, there exists a joint normal collection of random variables
and covariances
.
Proof: We will take the underlying measurable space to be 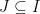

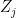
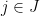

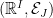

![{{\mathbb E}[Z_j]=\mu_j}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BZ_j%5D%3D%5Cmu_j%7D&bg=ffffff&fg=000000&s=0&c=20201002)



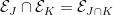

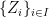
Theorem 15 can alternatively be expressed using inner product spaces, which as the advantage that positive definiteness is guaranteed. Recall that a semi-inner product on a real vector space V is a map 
 |
for all 
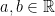
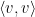
Theorem 16 Let V be a semi-inner product space. Then there exists a joint normal collection of random variables
(defined on some probability space) with zero mean and covariances
Furthermore, this uniquely determines the joint distribution of
![\displaystyle {\mathbb E}[X(u)X(v)]=\langle u,v\rangle.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5BX%28u%29X%28v%29%5D%3D%5Clangle+u%2Cv%5Crangle.+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: For any finite sequence 
 |
Hence, the existence of the random variables
In the statement of theorem 16, it would be natural to require 
Lemma 17 Let V be a semi-inner space. Then, a collection
- (linearity)
almost surely, for all
and
is normal with mean 0 and variance
for all
.
Proof: First, suppose that the conclusion of theorem 16 holds. Then, for any 
![\displaystyle \begin{aligned} {\mathbb E}[X(w)(X(au+bv)-aX(u)-bX(v))] &=\langle w,au+bv\rangle-a\langle w,u\rangle-b\langle w,v\rangle\\ &=0. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5BX%28w%29%28X%28au%2Bbv%29-aX%28u%29-bX%28v%29%29%5D+%26%3D%5Clangle+w%2Cau%2Bbv%5Crangle-a%5Clangle+w%2Cu%5Crangle-b%5Clangle+w%2Cv%5Crangle%5C%5C+%26%3D0.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
In particular, as this holds for 




Conversely, suppose that the properties of the lemma hold. Then, for finite sequences
 |
(almost surely) is normal and, hence,
 |
as required. ⬜
As an example of the use of theorem 16, we show how it can be used to construct standard Brownian motion. This approach was applied in the post on the Kolmogorov continuity theorem to construct Brownian motion on a multidimensional time index set, such as the Brownian sheet.
Example 3 Let V be the space
with inner product
, where
. Let
be a joint normal collection of random variables with zero mean and covariances
.
Then, (a continuous version of)
is standard Brownian motion. Furthermore,
(3) almost surely, for
.

With 
![\displaystyle \begin{aligned} {\mathbb E}[B_sB_t] &=\langle1_{[0,s]},1_{0,t]}\rangle\\ &=\int_0^\infty 1_{\{u\le s\}}1_{\{u\le t\}}du\\ &=s\wedge t. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5BB_sB_t%5D+%26%3D%5Clangle1_%7B%5B0%2Cs%5D%7D%2C1_%7B0%2Ct%5D%7D%5Crangle%5C%5C+%26%3D%5Cint_0%5E%5Cinfty+1_%7B%5C%7Bu%5Cle+s%5C%7D%7D1_%7B%5C%7Bu%5Cle+t%5C%7D%7Ddu%5C%5C+%26%3Ds%5Cwedge+t.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
Hence, B has the same distribution as standard Brownian motion. Furthermore, (3) holds for functions of the form ![{f=1_{[0,t]}}](https://s0.wp.com/latex.php?latex=%7Bf%3D1_%7B%5B0%2Ct%5D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
