
The drawdown of a stochastic process is the amount that it has dropped since it last hit its maximum value so far. For process X with running maximum X∗t = sups ≤ tXs, the drawdown is thus X∗t – Xt, which is a nonnegative process. This is as in figure 1 below.

The previous post used the reflection principle to show that the maximum of a Brownian motion has the same distribution as its terminal absolute value. That is, X∗t and |Xt| are identically distributed.
For a process X started from zero, its maximum and drawdown can be written as X∗t – X0 and X∗t – Xt. Reversing the process in time across the interval [0, t] will exchange these values. So, reversing in time and translating so that it still starts from zero will exchange the maximum value and the drawdown. Specifically, write
 |
for time index 0 ≤ s ≤ t. The maximum of Y is equal to the drawdown of X,
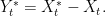 |
If X is standard Brownian motion then so is Y, since the independent normal increments property for Y follows from that of X. As already stated, the maximum Y∗t = X∗t – Xt has the same distribution as the absolute value |Yt|= |Xt|. So, the drawdown has the same distribution as the absolute value at each time.
Lemma 1 If X is standard Brownian motion, then X∗t – Xt has the same distribution as |Xt| at each time t ≥ 0.
This equivalence of distributions can be taken much further. Whereas the post on the reflection principle only compared distributions at fixed times, it turns out that the joint distributions of the entire drawdown process are equivalent to those of the reflecting Brownian motion |X|. Certainly, this is far from true for the running maximum X∗ which is increasing and never hits zero after time 0, in contrast to |X| which is never increasing over any nontrivial time intervals, and hits 0 every time that X changes sign. On the other hand, the drawdown X∗ – X moves along with the Brownian motion –X except for the times at which X hits a maximum, in which case the drawdown hits 0. This is qualitatively similar to the paths of a reflecting Brownian motion, and we can show that they are identically distributed.
The idea is to show that both the absolute value and drawdown of a Brownian motion are Markov with the same transition probabilities, from which it follows that they have the same joint distribution. This requires looking at the distribution of the drawdown of X started at each positive time s > 0. However, the maximum value of the forward started paths Yt = Xs + t are not the same as the forward started paths of X∗, since the latter also maximizes over the values of Xu for u < s. Instead, we have X∗s + t = X∗s ∨ Y∗t. For this reason, we need a generalization of lemma 1 where the running maximum of the process is itself maxed with an independent value.
Consider fixing a value M ≥ 0, which could represent the maximum value of X at time zero (e.g., if there was some history of the process before time 0 with this value). So, the running maximum of X will be replaced by M ∨ X∗ and the drawdown is replaced by M ∨ X∗ – X. Lemma 1 continues across to this case.
Lemma 2 If X is standard Brownian motion and M ≥ 0 is a fixed value, then M ∨ X∗t – Xt has the same distribution as |M – Xt| at each time t ≥ 0.
This can be proved as an extension of lemma 1, noting first that processes Ys = M ∨ X∗s – Xs and Zs = |M – Xs| are equivalent up until the first time at which X hits level M. Denoting this time by τ = inf{s ≥ 0: Xs ≥ M}, then Yt = Zt on the event that τ ≥ t. On the other hand, conditioning on any value of τ < t, the strong Markov property says that X̃s = Xτ + s – Xτ is a Brownian motion and, hence, lemma 1 says that Yt = X̃∗t - τ – X̃t - τ and Zt = |X̃t - τ| have the same distribution, proving lemma 2.
In the post on the reflection principle we spent some time constructing the joint distribution of X∗t and Xt. Now, when looking at the distributions of X∗t – Xt and M ∨ X∗t – Xt, we did not use that result and, instead, employed a time reversal trick. We could, of course, have used the joint distribution as expressed by theorems 2 or 3 of that post instead. It was just illuminating to see how a simple time reversal converts the maximum process X∗ into the drawdown X∗ – X, so that lemma 1 is clearly equivalent to the result that X∗t and |Xt| have the same distribution.
As it is good to have multiple methods of approaching a problem, let us also look at how the drawdown distribution also follows from the known joint distribution of X∗t and Xt. Setting Yt = M ∨ X∗t – Xt, theorem 3 of the previous post gives
 |
This holds on the event M – Xt ≤ a otherwise, when M – Xt > a, we automatically have Yt > a. So, setting Zt = M – Xt and taking expectations,
![\displaystyle {\mathbb P}(Y_t > a)={\mathbb P}(Z_t > a) + {\mathbb E}[1_{\{Z_t\le a\}}e^{-2(a+M-Z_t)t^{-1}a}].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+P%7D%28Y_t+%3E+a%29%3D%7B%5Cmathbb+P%7D%28Z_t+%3E+a%29+%2B+%7B%5Cmathbb+E%7D%5B1_%7B%5C%7BZ_t%5Cle+a%5C%7D%7De%5E%7B-2%28a%2BM-Z_t%29t%5E%7B-1%7Da%7D%5D.+&bg=ffffff&fg=000000&s=0&c=20201002) |
By either writing out the integral with respect the the normal density in the second term on the right hand side, or by applying a change of measure which shifts the mean of Zt by 2a, this gives
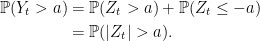 |
Hence, Yt and |Zt| have the same distribution, giving a second proof of lemma 2.
Finally, we can make use of the drawdown distribution as expressed in lemma 2 to find its joint distribution.
Theorem 3 If X is standard Brownian motion, then X∗t – Xt and |Xt| have identical joint distributions over 0 ≤ t < ∞.
To prove this, it is sufficient to show that both processes are Markov with respect to the natural filtration ℱ· of X, with the same transition probabilities and initial state. So, for times s < t, we need to show that the distribution of Yt = X∗t – Xt conditioned on ℱs depends only on Ys in the same way that the conditional distribution of Zt = |Xt| depends on Zs.
Considering the standard Brownian motion X̃u = Xs + u – Xs, which is independent of ℱs, we have
 |
so, by lemma 2 with X∗s – Xs in place of M, X̃ in place of X, and t – s in place of t, this has the same distribution as |(X∗s - Xs) – X̃t - s|= |X∗s – Xt| when conditioned on ℱs. This is the absolute value of a normal with mean Ys and variance t – s.
From the definition of Brownian motion, Zt conditioned on ℱs is the absolute value of a normal with mean Zs and variance t – s. This shows that Y and Z are both Markov with the same transition probabilities and with starting state Y0 = Z0 = 0, proving theorem 3. In fact, we did not make any use of the initial states of Y, Z other than that they are equal, so the exact same argument holds if we set Yt = M ∨ X∗t – Xt and Zt = |Xt – M| giving the following generalization.
Theorem 4 If X is standard Brownian motion and M ≥ 0 is a constant, then M ∨ X∗t – Xt and |M – Xt| have identical joint distributions over 0 ≤ t < ∞.
