
When I first created this blog, the subject of my initial post was the Gaussian correlation conjecture. Using 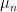

holds for all symmetric convex subsets A and B of 
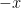


with 
At the time of my original post, the Gaussian correlation conjecture was an unsolved mathematical problem, originally arising in the 1950s and formulated in its modern form in the 1970s. However, in the period since that post, the conjecture has been solved! A proof was published by Thomas Royen in 2014 [7]. This seems to have taken some time to come to the notice of much of the mathematical community. In December 2015, Rafał Latała, and Dariusz Matlak published a simplified version of Royen’s proof [4]. Although the original proof by Royen was already simple enough, it did consider a generalisation of the conjecture to a kind of multivariate gamma distribution. The exposition by Latała and Matlak ignores this generality and adds in some intermediate lemmas in order to improve readability and accessibility. Since then, the result has become widely known and, recently, has even been reported in the popular press [10,11]. There is an interesting article on Royen’s discovery of his proof at Quanta Magazine [12] including the background information that Royen was a 67 year old German retiree who supposedly came up with the idea while brushing his teeth one morning. Dick Lipton and Ken Regan have recently written about the history and eventual solution of the conjecture on their blog [5]. As it has now been shown to be true, I will stop referring to the result as a `conjecture’ and, instead, use the common alternative name — the Gaussian correlation inequality.
In this post, I will describe some equivalent formulations of the Gaussian correlation inequality, or GCI for short, before describing a general method of attacking this problem which has worked for earlier proofs of special cases. I will then describe Royen’s proof and we will see that it uses the same ideas, but with some key differences.
Probably the most surprising aspect of Royen’s proof is its simplicity. Although it does involve some clever algebraic manipulations, no particularly complex mathematics is required to understand it. It seems incredible that a result which has been outstanding for so long has such a simple solution which has eluded all previous attempts. A common approach to the problem is to look at a local version of it and, by taking derivatives, replace it with a more easily manageable statement which I describe below in inequality (11). This `local’ inequality has successfully been used before to prove special cases of GCI, such the 2-dimensional version. Royen’s approach to the problem is similar and, although he does not rely on inequality (11), we will see that (11) does follow indirectly from his proof. So, it seems that the methods which have been used long before Royen published his paper were already along the correct lines but, previously, no-one had quite managed to get it to work. It is intriguing that nobody has produced a direct proof of inequality (11) — to my knowledge, at least.
There are various different, but similar, formulations of GCI, and one of the key steps in Royen’s solution is to start with the correct formulation. I will first describe some of the alternative formulations of the inequality. As above, using
 |
(1) |
for any symmetric convex sets 





An alternative formulation can be given in terms of probabilities of multidimensional Gaussian random variables lying in specified sets. If 

 |
(2) |
for any symmetric convex sets 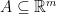
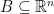
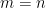

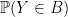
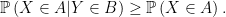
So, regardless of the correlations between X and Y, the knowledge that Y is in B increases the probability of finding X in A.
GCI can also be expressed using expectations rather than probabilities. A function 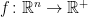
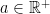
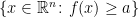
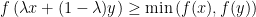
for all 

![\displaystyle {\mathbb E}\left[f(X)g(Y)\right]\ge{\mathbb E}\left[f(X)\right]{\mathbb E}\left[g(Y)\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Cleft%5Bf%28X%29g%28Y%29%5Cright%5D%5Cge%7B%5Cmathbb+E%7D%5Cleft%5Bf%28X%29%5Cright%5D%7B%5Cmathbb+E%7D%5Cleft%5Bg%28Y%29%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002) |
(3) |
for all symmetric quasiconcave functions 

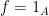



The final formulation of GCI which I will describe here is expressed in terms of the probabilities that a sequence of Gaussian random variables lie in specified symmetric intervals of 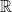
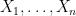
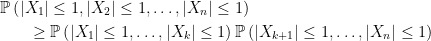 |
(4) |
for 


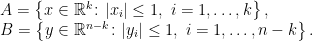 |
(5) |
The formulation given by (4) is central to Royen’s proof, but has also been a common form in which the inequality has been stated ever since it was first formulated. The case with 

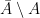


As promised, we show that each of the alternative formulations of GCI given above are equivalent.
Lemma 1 Each of the forms of GCI given by (1), (2), (3) and (4) are equivalent.
To be precise, here we mean that each of the inequalities are equivalent when stated in their full generality. That is, if any one holds in all dimensions m and n and for all pairs of symmetric convex sets (or quasiconcave functions), then all of the other statements hold.
Equivalence of (1) and (2): It was already noted above that inequality (1) is a special case of (2), so just the reverse implication remains to be shown. That is, assuming that inequality (1) holds, we need to prove (2). To do this, use the standard result that any centered multidimensional Gaussian vector can be expressed as a linear function of a standard Gaussian vector. In our case, this means that there is a random vector Z taking values in 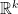

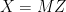


Applying inequality (1),

as required.
Equivalence of (2) and (3): As (2) is the special case of (3) where 

 |
(6) |
Multiplying these, taking expectations, and using Fubini’s theorem to commute the integrals with the expectation,
![\displaystyle {\mathbb E}\left[f(X)g(Y)\right]=\int_0^\infty\int_0^\infty{\mathbb P}\left(f(X)\ge x, g(Y)\ge y\right)\,dxdy](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Cleft%5Bf%28X%29g%28Y%29%5Cright%5D%3D%5Cint_0%5E%5Cinfty%5Cint_0%5E%5Cinfty%7B%5Cmathbb+P%7D%5Cleft%28f%28X%29%5Cge+x%2C+g%28Y%29%5Cge+y%5Cright%29%5C%2Cdxdy+&bg=ffffff&fg=000000&s=0&c=20201002)
Applying inequality (2),
![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rl} \displaystyle{\mathbb E}\left[f(X)g(Y)\right] &\displaystyle\ge\int_0^\infty\int_0^\infty{\mathbb P}\left(f(X)\ge x\right){\mathbb P}\left(g(Y)\ge y\right)\,dxdy\smallskip\\ &\displaystyle={\mathbb E}\left[f(X)\right]{\mathbb E}\left[g(Y)\right] \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brl%7D+%5Cdisplaystyle%7B%5Cmathbb+E%7D%5Cleft%5Bf%28X%29g%28Y%29%5Cright%5D+%26%5Cdisplaystyle%5Cge%5Cint_0%5E%5Cinfty%5Cint_0%5E%5Cinfty%7B%5Cmathbb+P%7D%5Cleft%28f%28X%29%5Cge+x%5Cright%29%7B%5Cmathbb+P%7D%5Cleft%28g%28Y%29%5Cge+y%5Cright%29%5C%2Cdxdy%5Csmallskip%5C%5C+%26%5Cdisplaystyle%3D%7B%5Cmathbb+E%7D%5Cleft%5Bf%28X%29%5Cright%5D%7B%5Cmathbb+E%7D%5Cleft%5Bg%28Y%29%5Cright%5D+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
as required.
Equivalence of (2) and (4): It was noted above that (4) is a special case of (2) where the sets A and B are of the form given in equation (5). It only remains to show that inequality (2) follows from the assumption that (4) holds.
Consider the case where
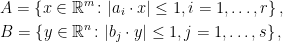 |
(7) |
for some 


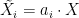


Applying inequality (4) to this,

This proves (2) for symmetric convex polytopes. It is a consequence of the hyperplane separation theorem that every nonempty symmetric closed convex set is the intersection of a countable sequence of strips of the form 
The Local Approach
One method of attacking the Gaussian correlation inequality is to note that both sides of the inequality can be expressed as the values of some function evaluated at different points of a connected topological space. If it can shown that we can move from one of the points to the other, along a continuous path in the space on which the function is monotonic, then GCI would follow. I will describe this approach now.
Let us start with a pair of independent n-dimensional random vectors X and Y, each with the standard Gaussian distribution
 |
(8) |
for symmetric convex 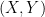
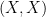


over 
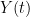

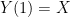
![\displaystyle {\rm Covar}(X,Y(t))={\mathbb E}\left[XY(t)^T\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Crm+Covar%7D%28X%2CY%28t%29%29%3D%7B%5Cmathbb+E%7D%5Cleft%5BXY%28t%29%5ET%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
is just 
Conjecture C1 For any symmetric convex sets
(9) is increasing in t, over the range
If true, conjecture C1 implies (8) and, hence, the Gaussian correlation inequality. Due to Sidak [9], this conjecture is known to be true if A is a symmetric slab of the form

for some 
One way of directly trying to prove conjecture C1 is to differentiate (9) with respect to t and show that the result is positive. This is more easily done if the indicator functions 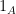


![\displaystyle \frac{d}{dt}{\mathbb E}\left[f(X)g(Y(t))\right]=\sum_{i=1}^n{\mathbb E}\left[f_{,i}(X)g_{,i}(Y(t))\right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cfrac%7Bd%7D%7Bdt%7D%7B%5Cmathbb+E%7D%5Cleft%5Bf%28X%29g%28Y%28t%29%29%5Cright%5D%3D%5Csum_%7Bi%3D1%7D%5En%7B%5Cmathbb+E%7D%5Cleft%5Bf_%7B%2Ci%7D%28X%29g_%7B%2Ci%7D%28Y%28t%29%29%5Cright%5D.+&bg=ffffff&fg=000000&s=0&c=20201002) |
(10) |
Here 
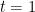
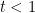
Conjecture C2 Let
be symmetric quasiconcave and Lipschitz continuous functions. Then,
(11) where

Inequality (11) was used by Pitt to prove GCI in two dimensions, and appears as Theorem 1 of his 1977 paper [6]. In fact, it is shown that if 

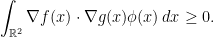 |
(12) |
The special case with 

Conjecture C1 can be stated in a more general form, which I will do now. Letting X and Y be centered Gaussian random vectors of dimension m and n, use 

Here, Q is any mxn matrix. When 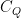
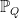
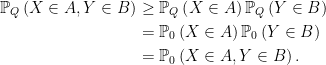 |
(13) |
The first equality here follows because the vectors X and Y have covariance matrices 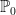
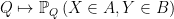
has a global minimum at 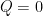
Inequality (13) would be proved if we can find a continuous curve, 




for a positive definite mxm matrix M. However, Hargé used a curve specific to the ellipsoid under consideration,

This has the limits 
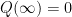
In the general case, the only canonical choice of curve joining 0 to Q is the line segment 

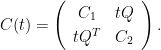 |
(14) |
We state the following conjecture.
Conjecture C3 For any symmetric convex sets
(15) is increasing in t over the range

This has a more general appearance than conjecture C1, but is easily shown to be equivalent. Sidak [9] proved this conjecture for 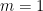
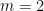
Lemma 2 Conjectures C1, C2 and C3 are equivalent, and imply the Gaussian correlation inequality.
Proof: To be precise, in the statement of this lemma, we mean that if any of the conjectures holds in full generality (i.e., in any number of dimensions) then they all hold. It was already explained above how C1 implies GCI, so I will concentrate on showing equivalence of the three conjectures.
If C1 holds then, representing quasiconcave functions
![\displaystyle {\mathbb E}\left[f(X)g(Y(t))\right]=\int_0^\infty\int_0^\infty{\mathbb P}\left(f(X)\ge x,g(Y(t))\ge y\right)\,dxdy.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Cleft%5Bf%28X%29g%28Y%28t%29%29%5Cright%5D%3D%5Cint_0%5E%5Cinfty%5Cint_0%5E%5Cinfty%7B%5Cmathbb+P%7D%5Cleft%28f%28X%29%5Cge+x%2Cg%28Y%28t%29%29%5Cge+y%5Cright%29%5C%2Cdxdy.+&bg=ffffff&fg=000000&s=0&c=20201002)
So, the expectation is increasing in t. If f and g are Lipschitz continuous then, the derivative (10) with respect to t is nonnegative and, setting
Now, suppose that C2 holds. Let 
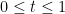


Then, by C2,
![\displaystyle \sum_{i=1}^n{\mathbb E}\left[f_{,i}(X)g_{,i}(tX+\sqrt{1-t^2}Y)\right] =\sum_{i=1}^{2n}{\mathbb E}\left[\tilde f_{,i}(Z)\tilde g_{,i}(Z)\right]\ge0.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csum_%7Bi%3D1%7D%5En%7B%5Cmathbb+E%7D%5Cleft%5Bf_%7B%2Ci%7D%28X%29g_%7B%2Ci%7D%28tX%2B%5Csqrt%7B1-t%5E2%7DY%29%5Cright%5D+%3D%5Csum_%7Bi%3D1%7D%5E%7B2n%7D%7B%5Cmathbb+E%7D%5Cleft%5B%5Ctilde+f_%7B%2Ci%7D%28Z%29%5Ctilde+g_%7B%2Ci%7D%28Z%29%5Cright%5D%5Cge0.+&bg=ffffff&fg=000000&s=0&c=20201002)
From (10), this is the derivative of ![{{\mathbb E}[f(X)g(Y(t))]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5Bf%28X%29g%28Y%28t%29%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Consider symmetric convex sets 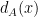

for each integer n. Then, ![{{\mathbb E}[f_n(X)g_n(Y(t))]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5Bf_n%28X%29g_n%28Y%28t%29%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


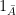

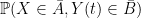

Conjecture C1 is just the special case of C3 with 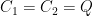
Suppose that X, Y are centered jointly Gaussian random vectors with dimensions m and n respectively, and such that 
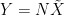
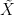


the covariance matrix is

Therefore, 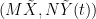
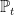

Conjecture C1 states that the right hand side of this equality is increasing in t and, hence, conjecture C3 follows. ⬜
Royen’s Proof of the Gaussian Correlation Inequality
I now describe Royen’s proof of the Gaussian correlation inequality. The formulation best suited to this approach is inequality (4) above,
 |
(16) |
for an n-dimensional centered Gaussian random vector X and any
The idea behind the proof is then along similar lines to that described in the `local approach’ above. We continuously vary the covariance matrix of X in order to transform the right hand side of (16) into the probability on the left. By differentiating, we aim to show that this gives an increasing function, and (16) will follow.
Laplace transforms will be used to compute the derivatives of the probability as the covariance matrix is varied. Key to this approach is to look at the transforms of the squares, 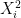
![\displaystyle {\mathbb E}\left[\exp\left(-X^TAX/2\right)\right]=\lvert1+CA\rvert^{-1/2}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Cleft%5B%5Cexp%5Cleft%28-X%5ETAX%2F2%5Cright%29%5Cright%5D%3D%5Clvert1%2BCA%5Crvert%5E%7B-1%2F2%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
(17) |
holds for any nxn positive semidefinite matrix A, where C is the covariance matrix and 
Defining the random vector Z taking values in 

![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rl} \displaystyle {\mathbb E}\left[\exp\left(-\lambda\cdot Z\right)\right]&={\mathbb E}\left[\exp\left(-X^T\Lambda X/2\right)\right]\smallskip\\ &=\lvert1+C\Lambda\rvert^{-1/2}. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brl%7D+%5Cdisplaystyle+%7B%5Cmathbb+E%7D%5Cleft%5B%5Cexp%5Cleft%28-%5Clambda%5Ccdot+Z%5Cright%29%5Cright%5D%26%3D%7B%5Cmathbb+E%7D%5Cleft%5B%5Cexp%5Cleft%28-X%5ET%5CLambda+X%2F2%5Cright%29%5Cright%5D%5Csmallskip%5C%5C+%26%3D%5Clvert1%2BC%5CLambda%5Crvert%5E%7B-1%2F2%7D.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
(18) |
Here, 
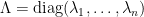

![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rl} \displaystyle\lvert1+C\Lambda\rvert&\displaystyle=1+\sum_{\emptyset\not=J\subseteq[n]}\lvert(C\Lambda)_J\rvert\smallskip\\ &\displaystyle=1+\sum_{\emptyset\not=J\subseteq[n]}\lvert C_J\rvert \lambda^J. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brl%7D+%5Cdisplaystyle%5Clvert1%2BC%5CLambda%5Crvert%26%5Cdisplaystyle%3D1%2B%5Csum_%7B%5Cemptyset%5Cnot%3DJ%5Csubseteq%5Bn%5D%7D%5Clvert%28C%5CLambda%29_J%5Crvert%5Csmallskip%5C%5C+%26%5Cdisplaystyle%3D1%2B%5Csum_%7B%5Cemptyset%5Cnot%3DJ%5Csubseteq%5Bn%5D%7D%5Clvert+C_J%5Crvert+%5Clambda%5EJ.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
(19) |
The summation is over all finite nonempty subsets J of ![{[n]=\{1,2,\ldots,n\}}](https://s0.wp.com/latex.php?latex=%7B%5Bn%5D%3D%5C%7B1%2C2%2C%5Cldots%2Cn%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)



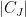
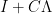

Let us now consider the covariance matrix to be a differentiable function of time, 
![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rl} \displaystyle \frac{d}{dt} {\mathbb E}\left[\exp\left(-\lambda\cdot Z\right)\right]&\displaystyle=-\frac12\lvert1+C\Lambda\rvert^{-3/2}\frac{d}{dt}\lvert1+C\Lambda\rvert\smallskip\\ &\displaystyle=-\frac12\lvert1+C\Lambda\rvert^{-3/2}\sum_{\emptyset\not=J\subseteq[n]}\frac{d}{dt}\lvert C_J\rvert\lambda^J. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brl%7D+%5Cdisplaystyle+%5Cfrac%7Bd%7D%7Bdt%7D+%7B%5Cmathbb+E%7D%5Cleft%5B%5Cexp%5Cleft%28-%5Clambda%5Ccdot+Z%5Cright%29%5Cright%5D%26%5Cdisplaystyle%3D-%5Cfrac12%5Clvert1%2BC%5CLambda%5Crvert%5E%7B-3%2F2%7D%5Cfrac%7Bd%7D%7Bdt%7D%5Clvert1%2BC%5CLambda%5Crvert%5Csmallskip%5C%5C+%26%5Cdisplaystyle%3D-%5Cfrac12%5Clvert1%2BC%5CLambda%5Crvert%5E%7B-3%2F2%7D%5Csum_%7B%5Cemptyset%5Cnot%3DJ%5Csubseteq%5Bn%5D%7D%5Cfrac%7Bd%7D%7Bdt%7D%5Clvert+C_J%5Crvert%5Clambda%5EJ.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
(20) |
Now, an important step in Royen’s proof of the Gaussian correlation inequality is to note that the right hand side of (20) can also be expressed in terms of a Laplace transform, but with respect to a different distribution than that used for Z. In fact, 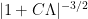



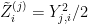
![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rl} \displaystyle {\mathbb E}\left[\exp\left(-\lambda\cdot \tilde Z\right)\right] &\displaystyle={\mathbb E}\left[\prod_{j=1}^d\exp\left(-\lambda\cdot \tilde Z^{(j)}\right)\right]\smallskip\\ &\displaystyle=\prod_{j=1}^d \lvert1+C\Lambda\rvert^{-1/2}\smallskip\\ &\displaystyle=\lvert1+C\Lambda\rvert^{-d/2}. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brl%7D+%5Cdisplaystyle+%7B%5Cmathbb+E%7D%5Cleft%5B%5Cexp%5Cleft%28-%5Clambda%5Ccdot+%5Ctilde+Z%5Cright%29%5Cright%5D+%26%5Cdisplaystyle%3D%7B%5Cmathbb+E%7D%5Cleft%5B%5Cprod_%7Bj%3D1%7D%5Ed%5Cexp%5Cleft%28-%5Clambda%5Ccdot+%5Ctilde+Z%5E%7B%28j%29%7D%5Cright%29%5Cright%5D%5Csmallskip%5C%5C+%26%5Cdisplaystyle%3D%5Cprod_%7Bj%3D1%7D%5Ed+%5Clvert1%2BC%5CLambda%5Crvert%5E%7B-1%2F2%7D%5Csmallskip%5C%5C+%26%5Cdisplaystyle%3D%5Clvert1%2BC%5CLambda%5Crvert%5E%7B-d%2F2%7D.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
(21) |
Royen refers to this as an n-variate gamma distribution, which I will denote by 
Putting the above calculations together, we can now compute how the expectations of functions of Z vary as the covariance matrix C is varied. This is stated in Lemma 3 below. I will deviate slightly from Royen’s argument here. Whereas he expresses the time derivative of the probability density of Z in terms of the 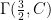
Equation (22) below can be compared with (10) above. They both express the derivative of the expectation of a function of our random variables in terms of an expectation over partial derivatives of the function. The difference is that now, we look at expectations of a function of 
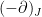
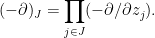
Lemma 3 Let the positive semidefinite matrix
under the measure
with compact support,
is continuously differentiable with,
(22) Here,
represents expectation under a probability measure for which
distribution, and
are the coefficients
(23)
![\displaystyle \frac{d}{dt}{\mathbb E}_t\left[f(Z)\right]=\sum_{\emptyset\not=J\subseteq[n]} c_J\tilde{\mathbb E}_t\left[(-\partial)_Jf(\tilde Z)\right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cfrac%7Bd%7D%7Bdt%7D%7B%5Cmathbb+E%7D_t%5Cleft%5Bf%28Z%29%5Cright%5D%3D%5Csum_%7B%5Cemptyset%5Cnot%3DJ%5Csubseteq%5Bn%5D%7D+c_J%5Ctilde%7B%5Cmathbb+E%7D_t%5Cleft%5B%28-%5Cpartial%29_Jf%28%5Ctilde+Z%29%5Cright%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
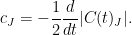
Proof: In the case where f is of the form 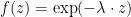

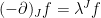


I demonstrate how Fourier transforms allow us to extend to the general case of (22). By analytic continuation, the above can be extended to imaginary values of 

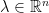

where the Fourier transform 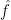
![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rl} \displaystyle \frac{d}{dt}{\mathbb E}_t[f(Z)] &\displaystyle=\frac{d}{dt}\int_{{\mathbb R}^n}\hat f(\lambda){\mathbb E}_t[g(Z,\lambda)]\,d\lambda\smallskip\\ &\displaystyle=\sum_{\emptyset\not=J\subseteq[n]}c_J\int_{{\mathbb R}^n}\hat f(\lambda)\tilde{\mathbb E}_t[(-\partial)_Jg(\tilde Z,\lambda)]\,d\lambda\smallskip\\ &\displaystyle=\sum_{\emptyset\not=J\subseteq[n]}c_J\tilde{\mathbb E}_t[(-\partial)_Jf(\tilde Z)]. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brl%7D+%5Cdisplaystyle+%5Cfrac%7Bd%7D%7Bdt%7D%7B%5Cmathbb+E%7D_t%5Bf%28Z%29%5D+%26%5Cdisplaystyle%3D%5Cfrac%7Bd%7D%7Bdt%7D%5Cint_%7B%7B%5Cmathbb+R%7D%5En%7D%5Chat+f%28%5Clambda%29%7B%5Cmathbb+E%7D_t%5Bg%28Z%2C%5Clambda%29%5D%5C%2Cd%5Clambda%5Csmallskip%5C%5C+%26%5Cdisplaystyle%3D%5Csum_%7B%5Cemptyset%5Cnot%3DJ%5Csubseteq%5Bn%5D%7Dc_J%5Cint_%7B%7B%5Cmathbb+R%7D%5En%7D%5Chat+f%28%5Clambda%29%5Ctilde%7B%5Cmathbb+E%7D_t%5B%28-%5Cpartial%29_Jg%28%5Ctilde+Z%2C%5Clambda%29%5D%5C%2Cd%5Clambda%5Csmallskip%5C%5C+%26%5Cdisplaystyle%3D%5Csum_%7B%5Cemptyset%5Cnot%3DJ%5Csubseteq%5Bn%5D%7Dc_J%5Ctilde%7B%5Cmathbb+E%7D_t%5B%28-%5Cpartial%29_Jf%28%5Ctilde+Z%29%5D.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Boundedness and continuity of ![{d{\mathbb E}_t[g(Z,\lambda)]/dt}](https://s0.wp.com/latex.php?latex=%7Bd%7B%5Cmathbb+E%7D_t%5Bg%28Z%2C%5Clambda%29%5D%2Fdt%7D&bg=ffffff&fg=000000&s=0&c=20201002)
As in the explanation of the local approach to the correlation conjecture above, we consider covariance matrices 
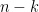
Lemma 4 Suppose that covariance matrix
for rxr matrix
. It is assumed that C is positive semidefinite over
Proof: For any ![{J\subseteq[n]}](https://s0.wp.com/latex.php?latex=%7BJ%5Csubseteq%5Bn%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


where 


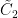
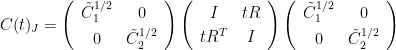
where 
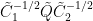
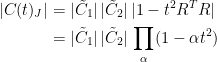
where 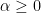
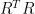
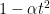

In the case where 



The previous two lemmas can be combined to show that we can continuously transform the probabilities on the right hand side of inequality (16) into the left hand side in such a way that they are increasing. This is a special case of conjecture C3 above.
Lemma 5 Let X be a random vector with values in
(24) is increasing in t
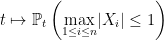
Proof: Let Z be the random vector taking values in 



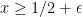

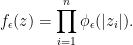
This is smooth with compact support. For any 
![\displaystyle (-\partial)_J f_\epsilon(z)=\prod_{i\in J}(-\phi^\prime(z_i))\prod_{i\in[n]\setminus J}\phi(z_i)\ge0.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%28-%5Cpartial%29_J+f_%5Cepsilon%28z%29%3D%5Cprod_%7Bi%5Cin+J%7D%28-%5Cphi%5E%5Cprime%28z_i%29%29%5Cprod_%7Bi%5Cin%5Bn%5D%5Csetminus+J%7D%5Cphi%28z_i%29%5Cge0.+&bg=ffffff&fg=000000&s=0&c=20201002)
From Lemma 3,
![\displaystyle \frac{d}{dt}{\mathbb E}_t\left[f_\epsilon(Z)\right]=\sum_{\emptyset\not=J\subseteq[n]}c_J\tilde{\mathbb E}_t\left[(-\partial)_Jf_\epsilon(\tilde Z)\right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cfrac%7Bd%7D%7Bdt%7D%7B%5Cmathbb+E%7D_t%5Cleft%5Bf_%5Cepsilon%28Z%29%5Cright%5D%3D%5Csum_%7B%5Cemptyset%5Cnot%3DJ%5Csubseteq%5Bn%5D%7Dc_J%5Ctilde%7B%5Cmathbb+E%7D_t%5Cleft%5B%28-%5Cpartial%29_Jf_%5Cepsilon%28%5Ctilde+Z%29%5Cright%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
The coefficients ![{{\mathbb E}_t[f_\epsilon(Z)]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D_t%5Bf_%5Cepsilon%28Z%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Finally, letting
![\displaystyle {\mathbb E}_t[f_\epsilon(Z)]\rightarrow{\mathbb P}_t\left(\max_{1\le i\le n}\lvert X_i\rvert\le1\right)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D_t%5Bf_%5Cepsilon%28Z%29%5D%5Crightarrow%7B%5Cmathbb+P%7D_t%5Cleft%28%5Cmax_%7B1%5Cle+i%5Cle+n%7D%5Clvert+X_i%5Crvert%5Cle1%5Cright%29+&bg=ffffff&fg=000000&s=0&c=20201002)
so that (24) is increasing in t as claimed. ⬜
Finally, GCI follows from Lemma 5.
Theorem 6 (Gaussian Correlation Inequality) If X is an n-dimensional centered Gaussian random vector then inequality (16),
holds, for each
Proof: Setting 


for rxr matrix 

So, we can define
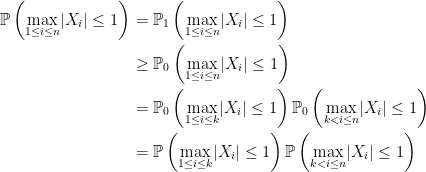
as required. ⬜
The Local Method Revisited
Looking at Royen’s proof, it is very similar in appearance to the local method described previously. Both consider continuously varying the coviarance matrix of the joint multidimensional Gaussian random vectors according to (14), and attempt to show that the resulting probabilities are increasing. Royen diverges from previous methods in two ways. First, rather than looking directly at Gaussian measures, by squaring the components of the random vector he instead brings in properties of the multidimensional gamma distribution. Secondly, he considers GCI in the special form (4). This results in showing that the probability (24) stated in Lemma 5 is increasing, rather than the more general form (15) stated in conjecture C3 above.
However, it follows from Royen’s proof that the conjectures discussed in the local approach above are true. It is surprising then that no-one has managed previously to solve the Gaussian correlation inequality using that approach.
Proof: We already know, as shown in Lemma 2, that these conjectures are equivalent. I will concentrate on proving C1. That is, if X and Y are independent standard Gaussian random vectors of dimension n then, setting 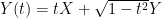
 |
(25) |
is increasing in t over the range
Consider the case where A and B are convex polytopes of the form (7),

for some 

its covariance matrix is seen to be as in (14) with 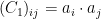
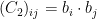


is increasing in t.
This proves the result for convex polytopes. As was noted above, every closed symmetric convex set is the limit of a decreasing sequence of convex polytopes. So by taking limits, (25) is increasing in t for any closed symmetric convex sets A and B. Finally, if the sets are symmetric and convex we can use the fact that their closures
References
- Das Gupta, S., Eaton, M. L., Olkin, I., Perlman, M., Savage, L. J., Sobel, M. (1972)Inequalitites on the probability content of convex regions for elliptically contoured distributions Proceedings of the Sixth Berkeley Symposium on Mathematical Statistics and Probability, Vol. 2: Probability Theory, University of California Press, 241–265. Link
- Hargé, Gilles (1999) A Particular Case of Correlation Inequality for the Gaussian Measure. The Annals of Probability. Vol. 27, No. 4, 1939–1951. doi:10.1214/aop/1022874822
- Khatri, C.G. (1967) On Certain Inequalities for Normal Distributions and their Applications to Simultaneous Confidence Bounds. Ann. Math. Statist. 38, No. 6, 1853–1867. doi:10.1214/aoms/1177698618
- Latała, R., and Matlak, D. (2017) Royen’s Proof of the Gaussian Correlation Inequality. Geometric Aspects of Functional Analysis: Israel Seminar (GAFA) 2014–2016, Springer International Publishing, 265–275. doi:10.1007/978-3-319-45282-1_17. Preprint (2015) available at arXiv:1512.08776
- Lipton, R.J., Regan, K.W. A Great Solution. Gödel’s Lost Letter and P=NP (blog), 30 Apr 2017.
- Pitt, Loren D. (1977) A Gaussian Correlation Inequality for Symmetric Convex Sets. The Annals of Probability. Vol. 5, No. 3, 470–474. doi:10.1214/aop/1176995808.
- Royen, T. (2014) A simple proof of the Gaussian correlation conjecture extended to multivariate gamma distributions. Far East Journal of Theoretical Statistics. Vol 48, Issue 2, 139–145. Preprint available at arXiv:1408.1028
- Sidak, Z. (1967) Rectangular Confidence Regions for the Means of Multivariate Normal Distributions. Journal of the American Statistical Association. Vol. 62, No. 318, 626–633. doi:10.2307/2283989
- Sidak, Z. (1968) On Multivariate Normal Probabilities of Rectangles: Their Dependence on Correlations. The Annals of Mathematical Statistics. Vol. 39, No. 5, 1425–1434. Link
- Retired German man solves one of world’s most complex maths problem with simple proof. Independent, Mon 3 April 2017.
- Retired 67-year-old man solves one of the world’s most complex maths problems while brushing his teeth using a ‘surprisingly simple’ solution. Daily Mail, Tues 4 April 2017.
- A Long-Sought Proof, Found and Almost Lost. Quanta Magazine, 28 Mar 2017.

Thanks for this very nice blog post. Royen has subsequently simplified his proof even further, see: https://arxiv.org/abs/1507.00528 . He now looks at the Laplace transform of the cdf rather than the pdf, reducing the proof to half a page!
Thanks. Giving the new paper a first look through, it seems that he has further extended his inequalities. Although the proof of Theorem 1 stated there is only half a page, I think this would be rather difficult to follow in isolation, and is rather longer when you add the required lemmas and explanations.
Are there any interesting open problems remaining in this general area?