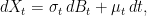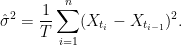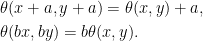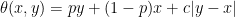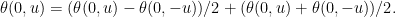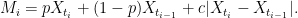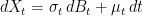Probability and measure theory relies on the concept of measurable sets. On the real numbers ℝ, in particular, there are several different sigma-algebras which are commonly used, and a set is said to be measurable if it lies in the one under consideration. Probabilities and measures are only defined for events lying in a specific sigma-algebra, so it is essential to know if sets are measurable. Fortunately, most simply constructed events will indeed be measurable, but this is not always the case. In fact, once we start working with more complex setups, such as continuous-time stochastic processes observed at random times, non-measurable sets occur more commonly than might be expected. To avoid such issues, it is usual to enlarge the underlying sigma-algebra defining a probability space as much as possible.
The Borel sets form the smallest sigma-algebra containing the open sets or, equivalently, containing all intervals. This is denoted as , which I will also shorten to . An explicit construction of a non-Borel set was given by Lusin in 1927. Every irrational real number can be expressed uniquely as a continued fraction
where a0 is an integer and ai are positive integers for i ≥ 1. Lusin considered the set of irrationals whose continued fraction coefficients contain a subsequence ak1, ak2, … such that each term is a divisor of the subsequent term.
Other examples can be given along similar lines to Lusin’s. Every real number has a binary expansion
where a0 is an integer and ai is in {0, 1} for each i ≥ 1. Consider the set of reals having a binary expansion for which there is an infinite sequence of positive integers k1, k2, …, each term strictly dividing the next, such that aki = 1. I will give proofs that these examples are non-Borel in this post.
There is a general method of enlarging sigma-algebras known as the completion. Consider a measure μ defined on a measurable space consisting of sigma-algebra on set X. The completion consists of all subsets S ⊆ X which can be sandwiched between sets in whose difference has zero measure. That is, A ⊆ S ⊆ B for with μ(B ∖ A) = 0. It can be shown that is a sigma-algebra containing , and μ uniquely extends to a measure on this by taking μ(S) = μ(A) = μ(B) for S, A, B as above.
The Lebesgue measure λ is uniquely defined on the Borel sets by specifiying its value on intervals as λ((a, b)) = b – a. The completion is the Lebesgue sigma-algebra, which I will denote by . Usually, when saying that a subset of the reals is measurable without further qualification, it is understood to mean that it is in . The non-Borel set constructed by Lusin can be shown to be measurable (in fact, its complement has zero Lebesgue measure).
While the Lebesgue measure extends uniquely to , this is not true for for all measures defined on the Borel sigma-algebra. In particular, it will not be true for singular measures, which assign a positive value to some Lebesgue-null sets. An example is the uniform probability measure (or, Haar measure) on the Cantor middle-thirds setC. This has zero Lebesgue measure, so every subset of C is in , but the uniform measure on C cannot be extended uniquely to all subsets. For this reason, universal completions are often used. For a measurable space , the universal completion consists of the subsets of X which lie in the completion of with respect to every possible sigma-finite measure.
The intersection is taken over all sigma-finite measures μ on . It is enough to take the intersection over finite or, even, probability measures, since every sigma-finite measure is equivalent to such. The universal completion is a bit tricky to understand in an explicit way but, by construction, all sigma-finite measures on a sigma-algebra extend uniquely to its universal completion. It can be shown that Lusin’s example of a non-Borel set does lie in the universal completion .
Finally, the power set consisting of all subsets of a set X is a sigma-algebra. For uncountable sets such as the reals, this is often too large to be of use and measures cannot be extended in any unique way. However, we have four common sigma-algebras of the real numbers,
(1)
In this post, I show that each of these inclusions is strict. That is, there are subsets of the reals which are not Lebesgue measurable, there are Lebesgue sets which are not in the universal completion , and there are sets in which are not Borel. Lusin’s construction is an example of the latter. The strictness of the other two inclusions does depend crucially on the axiom of choice so, unlike Lusin’s set, the examples demonstrating that these are strict are not explicit. Continue reading “Non-Measurable Sets”→
I continue the investigation of discrete barrier approximations started in an earlier post. The idea is to find good approximations to a continuous barrier condition, while only sampling the process at a discrete set of times. The difference now is that I will look at model independent methods which do not explicitly depend on properties of the underlying process, such as the volatility. This will enable much more generic adjustments which can be applied more easily and more widely. I point out now, the techniques that I will describe here are original research and cannot currently be found in the literature outside of this blog, to the best of my knowledge.
Recall that the problem is to compute the expected value of a function of a stochastic process X,
(1)
which depends on whether or not the process crosses a continuous barrier level K. In many applications, such as with Monte Carlo simulation, we typically only sample X at a discrete set of times 0 < t1 < t2 < ⋯< tn = T. In that case, the continuous barrier is necessarily approximated by a discrete one
(2)
As we saw, this converges slowly as the number n of sampling times increases, with the error between this and the limiting continuous barrier (1) only going to zero at rate 1/√n.
A barrier adjustment as described in the earlier post is able to improve this convergence rate. If X is a Brownian motion with constant drift μ and positive volatility σ, then the discrete barrier level K is shifted down by an amount βσ√δt where β ≈ 0.5826 is a constant and δt = T/n is the sampling width. We are assuming, for now, that the sampling times are equally spaced. As was seen, using the shifted barrier level in (2) improves the rate of convergence. Although we did not theoretically derive the new convergence rate, numerical experiment suggests that it is close to 1/n.
Another way to express this is to shift the values of X up,
(3)
Then, (2) is replaced to use these shifted values, which are a proxy for the maximum value of X across each of the intervals (ti-1, ti),
(4)
As it is equivalent to shifting the level K down, we still obtain the improved rate of convergence.
This idea is especially useful because of its generality. For non-equally spaced sampling times, the adjustment (3) can still be applied. Now, we just set δt = ti – ti-1 to be the spacing for the specific time, so depends on index i. It can also be used for much more general expressions than (1). Any function of X which depends on whether or not it crosses a continuous barrier can potentially make use of the adjustment described. Even if X is an Ito process with time dependent drift and volatility
(5)
the method can be applied. Now, the volatility in (3) is replaced by an average value across the interval (ti-1, ti).
The methods above are very useful, but there is a further improvement that can be made. Ideally, we would not have to specify an explicit value of the volatility σ. That is, it should be model independent. There are many reasons why this is desirable. Suppose that we are running a Monte Carlo simulation and generate samples of X at the times ti. If the simulation only outputs values of X, then this is not sufficient to compute (3). So, it will be necessary to update the program running the simulation to also output the volatility. In some situations this might not be easy. For example, X could be a complicated function of various other processes and, although we could use Ito’s lemma to compute the volatility of X from the other processes, it could be messy. In some situations we might not even have access to the volatility or any method of computing it. For example, the values of X could be computed from historical data. We could be looking at the probability of stock prices crossing a level by looking at historical close fixings, without access to the complete intra-day data. In any case, a model independent discrete barrier adjustment would make applying it much easier.
Removing Volatility Dependence
How can the volatility term be removed from adjustment (3)? One idea is to replace it by an estimator computed from the samples of X, such as
While this would work, at least for a constant volatility process, it does not meet the requirements. For a general Ito process (5) with stochastic volatility, using an estimator computed over the whole time interval [0, T] may not be a good approximation for the volatility at the time that the barrier is hit. A possible way around this is for the adjustment (3) applied at time ti to only depend on a volatility estimator computed from samples near the time. This would be possible, although it is not clear what is the best way to select these times. Besides, an important point to note is that we do not need a good estimate of the volatility, since that is not the goal here.
As explained in the previous post, adjustment (3) works because it corrects for the expected overshoot when the barrier is hit. Specifically, at the first time for which Mi ≥ K, the overshoot is R = Xti – K. If there was no adjustment then the overshoot is positive and the leading order term in the discrete barrier approximation error is proportional to 𝔼[R]. The positive shift added to Xti is chosen to compensate for this, giving zero expected overshoot to leading order, and reducing the barrier approximation error. The same applies to any similar adjustment. As long as there is sufficient freedom in choosing Mi, then it should be possible to do it in a way that has zero expected overshoot. Taking this to the extreme, it should be possible to compute the adjustment at time ti using only the sampled values Xti-1 and Xti.
Figure 1: Barrier overshoot
Consider adjustments of the form
for θ: ℝ2 → ℝ. By model independence, if this adjustment applies to a process X, then it should equally apply to the shifted and scaled processes X + a and bX for constants a and b > 0. Equivalently, θ satisfies the scaling and translation invariance,
(6)
This restricts the possible forms that θ can take.
Lemma 1 A function θ: ℝ2 → ℝ satisfies (6) if and only if
for constants p, c.
Proof: Write θ(0, u) as the sum of its antisymmetric and symmetric parts
By scaling invariance, the first term on the right is proportional to u and the second is proportional to |u|. Hence,
for constants p and c. Using translation invariance,
as required. ⬜
I will therefore only consider adjustments where the maximum of the process across the interval (ti-1, ti) is replaced by
(7)
According to (3), the barrier condition supt≤TXt ≥ K is replaced by the discrete approximation maxiMi ≥ K.
There are various ways in which (7) can be parameterized, but this form is quite intuitive. The term pXti + (1 - p)Xti-1 is an interpolation of the path of X, and c|Xti – Xti-1| represents a shift proportional to the sample deviation across the interval replacing the σ√δt term of the simple shift (3). The purpose of this post is to find values for p and c giving a good adjustment, improving convergence of the discrete approximation.
Figure 2: Adjusted barrier overshoot
The discrete barrier condition Mi ≥ K given by (7) can be satisfied while the process is below the barrier level, giving a negative barrier ‘overshoot’ R = Xti – K as in figure 2. As we will see, this is vital to obtaining an accurate approximation for the hitting probability. Continue reading “Model-Independent Discrete Barrier Adjustments”→
It is quite common to consider functions of real-time stochastic process which depend on whether or not it crosses a specified barrier level K. This can involve computing expectations involving a real-valued process X of the form
(1)
for a positive time T and function f: ℝ → ℝ. I am using the notation 𝔼[A;S] to denote the expectation of random variable A restricted to event S, or 𝔼[A1S].
One example is computing prices of financial derivatives such as barrier options, where T represents the expiration time and f is the payoff at expiry conditional on hitting upper barrier level K. A knock-in call option would have the final payoff f(x) = (x - a)+ for a contractual strike of a. Knock-out options are similar, except that the payoff is conditioned on not hitting the barrier level. As the sum of knock-in and knock-out options is just an option with no barrier, both cases involve similar calculations.
Alternatively, the barrier can be discrete, meaning that it only involves sampling the process at a finite set of times 0 ≤ t1 ≤ ⋯ ≤ tn ≤ T. Then, equation (1) is replaced by
(2)
Naturally, sampling at a finite set of times will reduce the probability of the barrier being reached and, so, if f is nonnegative then (2) will have a lower value than (1). It should still converge though as n goes to infinity and the sampling times become dense in the interval.
If the underlying process X is Brownian motion or geometric Brownian motion, possibly with a constant drift, then there are exact expressions for computing (1) in terms of integrating f against a normal density. See the post on the reflection principle for more information. However, it is difficult to find exact expressions for the discrete barrier (2) other than integrating over high-dimensional joint normal distributions. So, it can be useful to approximate a discrete barrier with analytic formulas for the continuous barrier. This is the idea used in the classic 1997 paper A Continuity Correction for Discrete Barrier Options by Broadie, Glasserman and Kou (freely available here).
We may want to compute the continuous barrier expectation (1) using Monte Carlo simulation. This is a common method, but involves generating sample paths of the process X at a finite set of times. This means that we are only able to sample at these times so, necessarily, are restricted to discrete barrier calculations as in (2).
I am primarily concerned with the second idea This is a very general issue, since Monte Carlo simulation is a common technique used in many applications. However, as it only represents sample paths at discrete time points, it necessarily involves discretely approximating continuous barrier levels. You may well ask why we would even want to use Monte Carlo if, as I mentioned above, there are exact expressions in these cases.In answer, such formulas only hold in very restrictive situations where the process X is a Brownian motion or geometric Brownian motion with constant drift. More generally it could be an ‘Ito process’ of the form
(3)
where B is standard Brownian motion. This describes X as a stochastic integral with respect to the predictable integrands σ and μ, which represent the volatility and drift of the process. Strictly speaking, these are ‘linear’ volatility and drift terms, rather than log-linear as used in many financial models applied to nonnegative processes such as stock prices. This is simply the choice made here, since this post is addressing a general mathematical problem of approximating continuous barriers and not restricting to such specific applications.
If the volatility and drift terms in (3) are not constant, then the exact formulas no longer hold. This is true, even if they are deterministic functions of time. In practice, these terms are often stochastic and can be rather general, in which case trying to find exact expressions is an almost hopeless task. Even though I concentrate on the case with constant volatility and drift in any calculations performed here, this is for convenience of exposition. The idea is that, as long as σ is piecewise continuous then, locally, it is well approximate as constant and the techniques discussed here should still apply.
In addition to considering general Ito processes (3), the ideas described here will apply to much more general functions of the process X than stated in (1). In the financial context, this means more general payoffs than simple knock-in or knock-out options. For example, autocallable trades involve a down-and-in put option but, additionally, contain a discrete set of upper barriers which cause the trade to make a final payment and terminate. They may also allow the issuer to early terminate the trade on a discrete set of dates. Furthermore, trades can depend on different assets with separate barriers on each of them, or on the average of a basket of assets, or have different barrier levels in different time periods. The list of possibilities is endless but, the idea is that each continuous barrier inside a complex payoff will be approximated by discretely sampled barrier conditions.
For efficiency, we may also want to approximate a discrete barrier with a large number of sampling times by one with fewer. The methods outlined in the post can also be used for this. In particular, the simple barrier shift described below could be used by taking the difference between the shift computed for the times actually sampled and the one for the required sample times. I do not go into details of this, but mention it now give an idea of the generality of the technique.
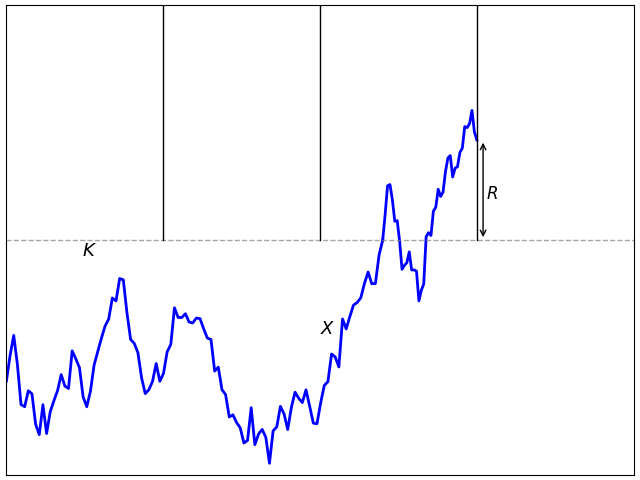
Figure 1: Discrete barrier approximation error
Let’s consider simply approximating a continuous barrier in (1) by the discrete barrier in (2). This will converge as the number of sampling times ti increases but, the problem is, it converges very slowly. We can get an idea of the order of the error when the sampling times have a δt spacing which, with equally spaced times, is given by δt = T/n. This is as shown in figure 1 above. When the process first hits the continuous barrier level, it will be on average about δt/2 before the next sampling time. If X behaves approximately like a Brownian motion with volatiity σ over this interval then it will have about 50% chance of being above K at the next discrete time. On the other hand, it will be below K with about 50% probability, in which case with will drop a distance proportional to σ√δt below on average. This means that if the continuous barrier is hit, there is a probability roughly proportional to σ√δt that the discrete barrier is not hit. So, the error in approximating a continuous barrier (1) by the discrete case (2) is of the order of σ√δt which only tends to zero at rate 1/√n. Continue reading “Discrete Barrier Approximations”→
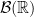
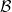
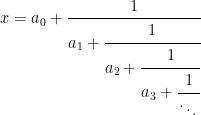

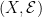



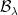
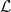

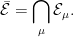
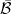
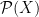
![\displaystyle V={\mathbb E}\left[f(X_T);\;\sup{}_{t\le T}X_t \ge K\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+V%3D%7B%5Cmathbb+E%7D%5Cleft%5Bf%28X_T%29%3B%5C%3B%5Csup%7B%7D_%7Bt%5Cle+T%7DX_t+%5Cge+K%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle V={\mathbb E}\left[f(X_T);\;\sup{}_{i=1,\ldots,n}X_{t_i}\ge K\right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+V%3D%7B%5Cmathbb+E%7D%5Cleft%5Bf%28X_T%29%3B%5C%3B%5Csup%7B%7D_%7Bi%3D1%2C%5Cldots%2Cn%7DX_%7Bt_i%7D%5Cge+K%5Cright%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle V={\mathbb E}\left[f(X_T);\;\sup{}_{i=1,\ldots,n}M_i\ge K\right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+V%3D%7B%5Cmathbb+E%7D%5Cleft%5Bf%28X_T%29%3B%5C%3B%5Csup%7B%7D_%7Bi%3D1%2C%5Cldots%2Cn%7DM_i%5Cge+K%5Cright%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)