The concept of a stopping times was introduced a couple of posts back. Roughly speaking, these are times for which it is possible to observe when they occur. Often, however, it is useful to distinguish between different types of stopping times. A random time for which it is possible to predict when it is about to occur is called a predictable stopping time. As always, we work with respect to a filtered probability space 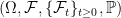 .
.
Definition 1 A map  is a predictable stopping time if there exists a sequence of stopping times
is a predictable stopping time if there exists a sequence of stopping times  satisfying
satisfying 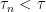 whenever
whenever  .
.
Predictable stopping times are alternatively referred to as previsible. The sequence of times  in this definition are said to announce
in this definition are said to announce  . Note that, in this definition, the random time was not explicitly required to be a stopping time. However, this is automatically the case, as the following equation shows.
. Note that, in this definition, the random time was not explicitly required to be a stopping time. However, this is automatically the case, as the following equation shows.

One way in which predictable stopping times occur is as hitting times of a continuous adapted process. It is easy to predict when such a process is about to hit any level, because it must continuously approach that value.
Theorem 2 Let  be a continuous adapted process and
be a continuous adapted process and  be a real number. Then
be a real number. Then
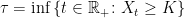
is a predictable stopping time.
Proof: Let be the first time at which 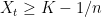 which, by the debut theorem, is a stopping time. This gives an increasing sequence bounded above by . Also,
which, by the debut theorem, is a stopping time. This gives an increasing sequence bounded above by . Also,  whenever
whenever  and, by left-continuity, setting
and, by left-continuity, setting  gives
gives 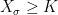 whenever
whenever 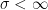 . So,
. So, 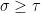 , showing that the sequence increases to . If
, showing that the sequence increases to . If  then, by continuity,
then, by continuity, 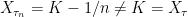 . So, whenever
. So, whenever 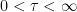 and the sequence
and the sequence 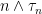 announces . ⬜
announces . ⬜
In fact, predictable stopping times are always hitting times of continuous processes, as stated by the following result. Furthermore, by the second condition below, it is enough to prove the much weaker condition that a random time can be announced `in probability’ to conclude that it is a predictable stopping time.
Lemma 3 Suppose that the filtration is complete and is a random time. The following are equivalent.
- is a predictable stopping time.
- For any
 there is a stopping time
there is a stopping time  satisfying
satisfying
 |
(1) |
-
 for some continuous adapted process .
for some continuous adapted process .
Continue reading “Predictable Stopping Times” →

![{(\sigma,\tau]}](https://s0.wp.com/latex.php?latex=%7B%28%5Csigma%2C%5Ctau%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{1_{(\sigma,\tau]}}](https://s0.wp.com/latex.php?latex=%7B1_%7B%28%5Csigma%2C%5Ctau%5D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle {\mathbb E}\left[X_\tau-X_\sigma\right]={\mathbb E}\left[\int_0^\infty 1_{(\sigma,\tau]}\,dX\right]\ge 0.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Cleft%5BX_%5Ctau-X_%5Csigma%5Cright%5D%3D%7B%5Cmathbb+E%7D%5Cleft%5B%5Cint_0%5E%5Cinfty+1_%7B%28%5Csigma%2C%5Ctau%5D%7D%5C%2CdX%5Cright%5D%5Cge+0.+&bg=ffffff&fg=000000&s=0&c=20201002)

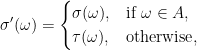

![\displaystyle {\mathbb E}\left[1_A(X_\tau-X_\sigma)\right]={\mathbb E}\left[X_\tau-X_{\sigma^\prime}\right]\ge 0.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Cleft%5B1_A%28X_%5Ctau-X_%5Csigma%29%5Cright%5D%3D%7B%5Cmathbb+E%7D%5Cleft%5BX_%5Ctau-X_%7B%5Csigma%5E%5Cprime%7D%5Cright%5D%5Cge+0.+&bg=ffffff&fg=000000&s=0&c=20201002)

![{X_\sigma\le{\mathbb E}[X_\tau\vert\mathcal{F}_\sigma]}](https://s0.wp.com/latex.php?latex=%7BX_%5Csigma%5Cle%7B%5Cmathbb+E%7D%5BX_%5Ctau%5Cvert%5Cmathcal%7BF%7D_%5Csigma%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
are integrable and the following are satisfied.
![{X_\sigma={\mathbb E}\left[X_{\tau}\vert\mathcal{F}_\sigma\right].}](https://s0.wp.com/latex.php?latex=%7BX_%5Csigma%3D%7B%5Cmathbb+E%7D%5Cleft%5BX_%7B%5Ctau%7D%5Cvert%5Cmathcal%7BF%7D_%5Csigma%5Cright%5D.%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{X_\sigma\le{\mathbb E}\left[X_{\tau}\vert\mathcal{F}_\sigma\right].}](https://s0.wp.com/latex.php?latex=%7BX_%5Csigma%5Cle%7B%5Cmathbb+E%7D%5Cleft%5BX_%7B%5Ctau%7D%5Cvert%5Cmathcal%7BF%7D_%5Csigma%5Cright%5D.%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{X_\sigma\ge{\mathbb E}\left[X_{\tau}\vert\mathcal{F}_\sigma\right].}](https://s0.wp.com/latex.php?latex=%7BX_%5Csigma%5Cge%7B%5Cmathbb+E%7D%5Cleft%5BX_%7B%5Ctau%7D%5Cvert%5Cmathcal%7BF%7D_%5Csigma%5Cright%5D.%7D&bg=ffffff&fg=000000&s=0&c=20201002)
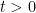 is denoted by
is denoted by  (and
(and 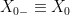 ). The jump at time
). The jump at time  is denoted by
is denoted by  .
.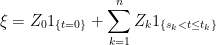
 ,
,  -measurable random variable
-measurable random variable  and
and 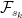 -measurable random variables
-measurable random variables 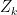 . Its integral with respect to a stochastic process
. Its integral with respect to a stochastic process 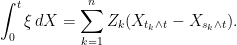
 which is a finite union of sets of the form
which is a finite union of sets of the form  for
for  and
and ![{(s,t]\times F}](https://s0.wp.com/latex.php?latex=%7B%28s%2Ct%5D%5Ctimes+F%7D&bg=ffffff&fg=000000&s=0&c=20201002) for nonnegative reals
for nonnegative reals  and
and  . Then, a process is an indicator function
. Then, a process is an indicator function  of some elementary predictable set
of some elementary predictable set  if and only if it is elementary predictable and takes values in
if and only if it is elementary predictable and takes values in  .
.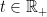 ,
,
![\displaystyle \left\{{\mathbb E}\left[\int_0^t1_A\,dX\right]\colon A\textrm{ is elementary}\right\}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cleft%5C%7B%7B%5Cmathbb+E%7D%5Cleft%5B%5Cint_0%5Et1_A%5C%2CdX%5Cright%5D%5Ccolon+A%5Ctextrm%7B+is+elementary%7D%5Cright%5C%7D+&bg=ffffff&fg=000000&s=0&c=20201002)


 whose time index
whose time index 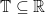 . For real numbers
. For real numbers 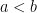 , the number of upcrossings of
, the number of upcrossings of ![{[a,b]}](https://s0.wp.com/latex.php?latex=%7B%5Ba%2Cb%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is the supremum of the nonnegative integers
is the supremum of the nonnegative integers  such that there exists times
such that there exists times 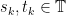 satisfying
satisfying
 . The number of upcrossings is denoted by
. The number of upcrossings is denoted by ![{U[a,b]}](https://s0.wp.com/latex.php?latex=%7BU%5Ba%2Cb%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , which is either a nonnegative integer or is infinite. Similarly, the number of downcrossings, denoted by
, which is either a nonnegative integer or is infinite. Similarly, the number of downcrossings, denoted by ![{D[a,b]}](https://s0.wp.com/latex.php?latex=%7BD%5Ba%2Cb%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , is the supremum of the nonnegative integers
, is the supremum of the nonnegative integers  .
.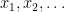 converges to a limit in the extended real numbers if and only if the number of upcrossings
converges to a limit in the extended real numbers if and only if the number of upcrossings ![{{\mathbb E}[\vert X_t\vert]<\infty}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5B%5Cvert+X_t%5Cvert%5D%3C%5Cinfty%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.![\displaystyle X_s={\mathbb E}[X_t\mid\mathcal{F}_s]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++X_s%3D%7B%5Cmathbb+E%7D%5BX_t%5Cmid%5Cmathcal%7BF%7D_s%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
 .
.  will be a measurable random variable. It is usual to study adapted processes, where
will be a measurable random variable. It is usual to study adapted processes, where 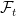 at that time. Then, it is natural to extend the notion of adapted processes to random times and ask the following. What is the sigma-algebra of observable events at the random time
at that time. Then, it is natural to extend the notion of adapted processes to random times and ask the following. What is the sigma-algebra of observable events at the random time  should be in
should be in 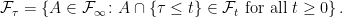
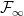 is to take account of the possibility that the stopping time can be infinite, and it ensures that
is to take account of the possibility that the stopping time can be infinite, and it ensures that 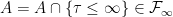 . From this definition, a random variable
. From this definition, a random variable  us
us 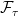 -measurable if and only if
-measurable if and only if 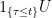 is
is 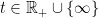 .
. . This suggests the following definition,
. This suggests the following definition,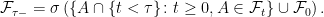
 denotes the sigma-algebra generated by a collection of sets, and in this definition the collection of elements of
denotes the sigma-algebra generated by a collection of sets, and in this definition the collection of elements of  used in these notes.
used in these notes.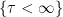 , but it is handy to allow the processes to take values at infinity. So, for the moment we consider a processes
, but it is handy to allow the processes to take values at infinity. So, for the moment we consider a processes 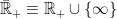 , and say that
, and say that 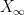 is
is  -measurable.
-measurable.  such that
such that  for each
for each 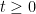 .
.  is adapted. Equivalently, at any time
is adapted. Equivalently, at any time 
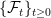 on a probability space
on a probability space 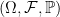 is a collection of sub-sigma-algebras of
is a collection of sub-sigma-algebras of  satisfying
satisfying 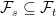 whenever
whenever 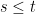 . The idea is that
. The idea is that 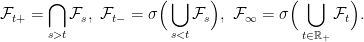
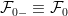 . The filtration is said to be right-continuous if
. The filtration is said to be right-continuous if 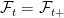 .
. 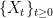 defined on a probability space
defined on a probability space  is a measurable function from
is a measurable function from  to the real numbers.
to the real numbers.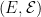 but, in these notes, I concentrate on real valued processes. I am also restricting to the case where the time index
but, in these notes, I concentrate on real valued processes. I am also restricting to the case where the time index  can be viewed in either of the following three ways.
can be viewed in either of the following three ways.
 . These are referred to as the sample paths of the process.
. These are referred to as the sample paths of the process.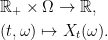
 spaces, convergence in probability, etc.).
spaces, convergence in probability, etc.).