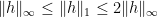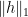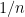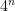Figure 1: The function f, convex in x and decreasing in t
Here, I attempt to construct a counterexample to the hypotheses of the earlier post, Do convex and decreasing functions preserve the semimartingale property? There, it was asked, for any semimartingaleX and function such that is convex in x and right-continuous and decreasing in t, is necessarily a semimartingale? It was explained how this is equivalent to the hypothesis: for any function such that is convex and Lipschitz continuous in x and decreasing in t, does it decompose as where and are convex in x and increasing in t. This is the form of the hypothesis which this post will be concerned with, so the example will only involve simple real analysis and no stochastic calculus. I will give some numerical calculations suggesting that the construction below is a counterexample, but do not have any proof of this. So, the hypothesis is still open.
Although the construction given here will be self-contained, it is worth noting that it is connected to the example of a martingale which moves along a deterministic path. If is the martingale constructed there, then
defines a function from to which is convex in x and increasing in t. The question is then whether C can be expressed as the difference of functions which are convex in x and decreasing in t. The example constructed in this post will be the same as C with the time direction reversed, and with a linear function of x added so that it is zero at .
I now move on to the construction of the example. For symmetry, I will consider x to take values in rather than the unit interval. So, we will construct a function where is the rectangle
such that is convex in x and decreasing in t. We start by defining f for ,
(1)
Next, extend to times () by successively linearly interpolating across intervals ,
Specifically, using the following intervals
gives the plots as in the first two iterations in Figure 2.
We now interpolate f between the times . For we have so, by monotonicity, f must be constant in t across the interval . On the other hand, for , we interpolate f as a scaled copy of itself on the whole of , plus a linear term in x in order to line up at times and . So, f will be self-similar on the rectangles . To express this self-similarity, define functions
We also let be the change in across the interval . To be explicit,
Then, f is defined on by,
This construction of f can be done iteratively. Let denote the space of functions such that is convex in x and continuous and decreasing in t, and satisfying (1). Then define by where, for ,
It can be seen that, with respect to the supremum norm, F is Lipschitz continuous on with Lipschitz constant 1/2. So, by the Banach fixed point theorem, there is a unique fixed point . The fixed point can be constructed iteratively. First choose any and, then, inductively define . By the Banach fixed point theorem this will converge uniformly to the required f. Furthermore, for each fixed n, the values of on the time slices () are fixed over all . So, equals at these time slices. Computing successive iterations generates f at these sequences of time slices, as in Figure 2. Figure 1 shows f computed in this way using 5 iterations.
Figure 2: Iteratively computing f
Computing the decomposition
With the function f constructed as above, we ask if it is possible to decompose
(2)
for functions and convex in x and increasing in t. The hypotheses of the post Do convex and decreasing functions preserve the semimartingale property? state that this is possible. However, some numerical calculations which I will present here suggest that f is a counterexample, and decomposition (2) does not exist. I do not have any proof of this though, so the hypotheses are still open.
The method described in the earlier post can be used to construct the decomposition (2), if it exists. The idea is to construct to be convex in x such that is increasing in t and, then, (2) would follow by taking . This is done by approximating h along partitions of the unit interval. Using to denote the convex hull of a function u, the approximation is defined inductively at times by
As the function f was constructed on the n‘th iteration at times (), it is convenient to also compute the approximation to h along these partitions. Also, as is piecewise linear in x at these times, the same holds for h. This makes it relatively simple to compute the approximation to h for each successive iteration of f on a computer. The resulting time-slices, are shown in Figure 3.
Figure 3: Iteratively computing h
It can be seen that the successive approximations to h are decreasing, initially having a minimum of -1 for the first two iterations, but a minimum of around -1.2 at the fourth iteration. The plot of h calculated at iteration 5 is given in Figure 4, showing that the minimum is slightly less than -1.3.
Figure 4: The function h, computed with 5 iterations
Now, by Lemma 2 of the previous post, one of the following statements holds.
Decomposition (2) exists, and the successive approximations for h converge to a finite limit.
Decomposition (2) does not exist, and the successive approximations for diverge to .
In an attempt to determine which of these cases is true, I computed h for a few iterations and looked at the successive and norms of h at time ,
Using convexity it can be shown that the norms are equivalent, , although I would expect the norm to be a bit better behaved as we compute successive iterations. The calculations for up to iteration 13 are given in the table below, and it can be seen that the norm is slowly but steadily increasing.
Iteration
0
1
1
1
1.25
1
2
1.398
1.115
3
1.520
1.183
4
1.635
1.252
5
1.743
1.336
6
1.846
1.414
7
1.950
1.491
8
2.050
1.568
9
2.151
1.645
10
2.249
1.721
11
2.347
1.796
12
2.444
1.870
13
2.541
1.944
The function f constructed in this post is a counterexample to the hypothesis of the previous post if and only if the norm is increasing to infinity. Figure 5 displays the behaviour, and it does look like the norm is increasing roughly linearly in the number of iterations.
Figure 5: The norm of h for increasing iterations
The successive differences in the norms are monotonically decreasing, but only very slowly. Certainly, they seem to be decreasing much more slowly than , in which case the norm would tend to infinity and f would be the counterexample to the hypotheses mentioned above. However, I do not have any proof of this. Also, the complexity of calculations used to obtain the numbers above grow exponentially in the number n of iterations. The number of time points in the partition grows like , and the number of x at which f and h are computed grows at rate . So, the time taken is of order and it quickly becomes infeasible to compute h as the number of iterations becomes large.





![{f\colon[0,1]^2\rightarrow{\mathbb R}}](https://s0.wp.com/latex.php?latex=%7Bf%5Ccolon%5B0%2C1%5D%5E2%5Crightarrow%7B%5Cmathbb+R%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


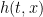
![{\{M_t\}_{t\in[0,1]}}](https://s0.wp.com/latex.php?latex=%7B%5C%7BM_t%5C%7D_%7Bt%5Cin%5B0%2C1%5D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle C(t,x)={\mathbb E}[(M_t-x)_+]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++C%28t%2Cx%29%3D%7B%5Cmathbb+E%7D%5B%28M_t-x%29_%2B%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![{[0,1]\times[-1,1]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%5Ctimes%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
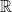

![{[-1,1]}](https://s0.wp.com/latex.php?latex=%7B%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

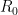
![\displaystyle R_0=[0,1]\times[-1,1],](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++R_0%3D%5B0%2C1%5D%5Ctimes%5B-1%2C1%5D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)





![{[a_i,b_i]}](https://s0.wp.com/latex.php?latex=%7B%5Ba_i%2Cb_i%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle f(t_{i-1},x)=\begin{cases} \frac{(b_i-x)f(t_i,a_i)+(x-a_i)f(t_i,b_i)}{b_i-a_i},&x\in[a_i,b_i],\\ f(t_i,x),&x\not\in[a_i,b_i]. \end{cases}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++f%28t_%7Bi-1%7D%2Cx%29%3D%5Cbegin%7Bcases%7D+%5Cfrac%7B%28b_i-x%29f%28t_i%2Ca_i%29%2B%28x-a_i%29f%28t_i%2Cb_i%29%7D%7Bb_i-a_i%7D%2C%26x%5Cin%5Ba_i%2Cb_i%5D%2C%5C%5C+f%28t_i%2Cx%29%2C%26x%5Cnot%5Cin%5Ba_i%2Cb_i%5D.+%5Cend%7Bcases%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rl} \displaystyle [a_1,b_1] &= [-1,1],\smallskip\\ \displaystyle [a_2,b_2] &= [-1,0],\smallskip\\ \displaystyle [a_3,b_3] &= [0,1],\smallskip\\ \displaystyle [a_4,b_4] &= [-1/2,1/2], \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brl%7D+%5Cdisplaystyle+%5Ba_1%2Cb_1%5D+%26%3D+%5B-1%2C1%5D%2C%5Csmallskip%5C%5C+%5Cdisplaystyle+%5Ba_2%2Cb_2%5D+%26%3D+%5B-1%2C0%5D%2C%5Csmallskip%5C%5C+%5Cdisplaystyle+%5Ba_3%2Cb_3%5D+%26%3D+%5B0%2C1%5D%2C%5Csmallskip%5C%5C+%5Cdisplaystyle+%5Ba_4%2Cb_4%5D+%26%3D+%5B-1%2F2%2C1%2F2%5D%2C+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)

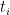
![{x\not\in[a_i,b_i]}](https://s0.wp.com/latex.php?latex=%7Bx%5Cnot%5Cin%5Ba_i%2Cb_i%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{[t_{i-1},t_i]}](https://s0.wp.com/latex.php?latex=%7B%5Bt_%7Bi-1%7D%2Ct_i%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{x\in[a_i,b_i]}](https://s0.wp.com/latex.php?latex=%7Bx%5Cin%5Ba_i%2Cb_i%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{R_i=[t_{i-1},t_i]\times[a_i,b_i]}](https://s0.wp.com/latex.php?latex=%7BR_i%3D%5Bt_%7Bi-1%7D%2Ct_i%5D%5Ctimes%5Ba_i%2Cb_i%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rl} &\displaystyle\varphi_i\colon[a_i,b_i]\rightarrow{\mathbb R},\smallskip\\ &\displaystyle \varphi_i(x)= \frac{(b_i-x)f(t_i,a_i)+(x-a_i)f(t_i,b_i)}{b_i-a_i}. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brl%7D+%26%5Cdisplaystyle%5Cvarphi_i%5Ccolon%5Ba_i%2Cb_i%5D%5Crightarrow%7B%5Cmathbb+R%7D%2C%5Csmallskip%5C%5C+%26%5Cdisplaystyle+%5Cvarphi_i%28x%29%3D+%5Cfrac%7B%28b_i-x%29f%28t_i%2Ca_i%29%2B%28x-a_i%29f%28t_i%2Cb_i%29%7D%7Bb_i-a_i%7D.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
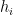


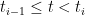
![\displaystyle f(t,x)=\begin{cases} h_if\left(4(t-t_{i-1}),\frac{2x-a_i-b_i}{b_i-a_i}\right)+\varphi_i(x),&x\in[a_i,b_i],\\ f(t_i,x),&x\not\in[a_i,b_i]. \end{cases}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++f%28t%2Cx%29%3D%5Cbegin%7Bcases%7D+h_if%5Cleft%284%28t-t_%7Bi-1%7D%29%2C%5Cfrac%7B2x-a_i-b_i%7D%7Bb_i-a_i%7D%5Cright%29%2B%5Cvarphi_i%28x%29%2C%26x%5Cin%5Ba_i%2Cb_i%5D%2C%5C%5C+f%28t_i%2Cx%29%2C%26x%5Cnot%5Cin%5Ba_i%2Cb_i%5D.+%5Cend%7Bcases%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
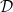

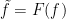

![\displaystyle \tilde f(t,x)=\begin{cases} h_i f\left(4(t-t_{i-1}),\frac{2x-a_i-b_i}{b_i-a_i}\right)+\varphi_i(x),&x\in[a_i,b_i],\\ \tilde f(t_i,x),&x\not\in[a_i,b_i]. \end{cases}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Ctilde+f%28t%2Cx%29%3D%5Cbegin%7Bcases%7D+h_i+f%5Cleft%284%28t-t_%7Bi-1%7D%29%2C%5Cfrac%7B2x-a_i-b_i%7D%7Bb_i-a_i%7D%5Cright%29%2B%5Cvarphi_i%28x%29%2C%26x%5Cin%5Ba_i%2Cb_i%5D%2C%5C%5C+%5Ctilde+f%28t_i%2Cx%29%2C%26x%5Cnot%5Cin%5Ba_i%2Cb_i%5D.+%5Cend%7Bcases%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
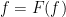


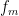

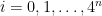
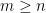



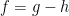

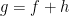
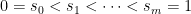




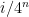



diverge to
.

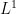

![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rl} \displaystyle\lVert h\rVert_\infty&\displaystyle=\sup_{x\in[-1,1]}\lvert h(0,x)\rvert,\smallskip\\ \displaystyle\lVert h\rVert_1&\displaystyle=\int_{-1}^1\lvert h(0,x)\rvert\,dx. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brl%7D+%5Cdisplaystyle%5ClVert+h%5CrVert_%5Cinfty%26%5Cdisplaystyle%3D%5Csup_%7Bx%5Cin%5B-1%2C1%5D%7D%5Clvert+h%280%2Cx%29%5Crvert%2C%5Csmallskip%5C%5C+%5Cdisplaystyle%5ClVert+h%5CrVert_1%26%5Cdisplaystyle%3D%5Cint_%7B-1%7D%5E1%5Clvert+h%280%2Cx%29%5Crvert%5C%2Cdx.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)