The aim of this post is to motivate the idea of representing probability spaces as states on a commutative algebra. We will consider how this abstract construction relates directly to classical probabilities.
In the standard axiomatization of probability theory, due to Kolmogorov, the central construct is a probability space 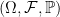 . This consists of a state space
. This consists of a state space  , an event space
, an event space  , which is a sigma-algebra of subsets of , and a probability measure
, which is a sigma-algebra of subsets of , and a probability measure 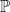 . The measure is defined as a map
. The measure is defined as a map  satisfying countable additivity and normalised as
satisfying countable additivity and normalised as 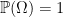 .
.
A measure space allows us to define integrals of real-valued measurable functions or, in the language of probability, expectations of random variables. We construct the set 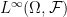 of all bounded measurable functions
of all bounded measurable functions 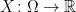 . This is a real vector space and, as it is closed under multiplication, is an algebra. Expectation, by definition, is the unique linear map
. This is a real vector space and, as it is closed under multiplication, is an algebra. Expectation, by definition, is the unique linear map  ,
, ![{X\mapsto{\mathbb E}[X]}](https://s0.wp.com/latex.php?latex=%7BX%5Cmapsto%7B%5Cmathbb+E%7D%5BX%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) satisfying
satisfying ![{{\mathbb E}[1_A]={\mathbb P}(A)}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5B1_A%5D%3D%7B%5Cmathbb+P%7D%28A%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) for
for 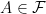 and monotone convergence: if
and monotone convergence: if 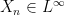 is a nonnegative sequence increasing to a bounded limit
is a nonnegative sequence increasing to a bounded limit  , then
, then ![{{\mathbb E}[X_n]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BX_n%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) tends to
tends to ![{{\mathbb E}[X]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BX%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
In the opposite direction, any nonnegative linear map 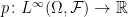 satisfying monotone convergence and
satisfying monotone convergence and 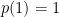 defines a probability measure by
defines a probability measure by 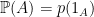 . This is the unique measure with respect to which expectation agrees with the linear map,
. This is the unique measure with respect to which expectation agrees with the linear map,  . So, probability measures are in one-to-one correspondence with such linear maps, and they can be viewed as one and the same thing. The Kolmogorov definition of a probability space can be thought of as representing the expectation on the subset of
. So, probability measures are in one-to-one correspondence with such linear maps, and they can be viewed as one and the same thing. The Kolmogorov definition of a probability space can be thought of as representing the expectation on the subset of  consisting of indicator functions
consisting of indicator functions 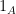 . In practice, it is often more convenient to start with a different subset of . For example, probability measures on
. In practice, it is often more convenient to start with a different subset of . For example, probability measures on  can be defined via their Laplace transform,
can be defined via their Laplace transform,  , which represents the expectation on exponential functions
, which represents the expectation on exponential functions  . Generalising to complex-valued random variables, probability measures on
. Generalising to complex-valued random variables, probability measures on 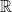 are often represented by their characteristic function
are often represented by their characteristic function  , which is just the expectation of the complex exponentials
, which is just the expectation of the complex exponentials  . In fact, by the monotone class theorem, we can uniquely represent probability measures on
. In fact, by the monotone class theorem, we can uniquely represent probability measures on  by the expectations on any subset
by the expectations on any subset 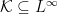 which is closed under taking products and generates the sigma-algebra .
which is closed under taking products and generates the sigma-algebra .
A simple corollary of the monotone class theorem states that there is a one-to-one correspondence between sigma-algebras on a set and algebras 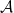 of bounded functions
of bounded functions  closed under monotone convergence, with the correspondence given by
closed under monotone convergence, with the correspondence given by 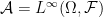 .
.
On the other hand, in quantum mechanics, we start with a Hilbert space 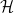 , and observables are represented as self-adjoint operators. Restricting our consideration to bounded observables, these generate a subalgebra of
, and observables are represented as self-adjoint operators. Restricting our consideration to bounded observables, these generate a subalgebra of  , the space of bounded linear maps on . A pure state is represented by an element
, the space of bounded linear maps on . A pure state is represented by an element  normalised so that
normalised so that  , and the expectation of an observable is
, and the expectation of an observable is  . This is a nonnegative linear map from a sub-algebra of to
. This is a nonnegative linear map from a sub-algebra of to 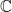 .
.
All of this suggests that it would be useful to consider an alternative approach to probability. Instead of a measurable space , we have an algebra . Instead of a probability measure , we have a positive linear map  from to or . The underlying state space is not required at all — it is a pointless approach to probability, as we no longer include the points
from to or . The underlying state space is not required at all — it is a pointless approach to probability, as we no longer include the points 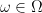 in the representation of the probability space. As multiplication of real (and complex) numbers is commutative,
in the representation of the probability space. As multiplication of real (and complex) numbers is commutative, 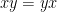 , algebras of the form are commutative. Hence, classical probability spaces will correspond to commutative algebras, with the generalisation to non-commutative algebras incorporating quantum probability.
, algebras of the form are commutative. Hence, classical probability spaces will correspond to commutative algebras, with the generalisation to non-commutative algebras incorporating quantum probability.
As this post is primarily intended to motivate the algebraic approach to probability, rather than go into technical details, I will not give proofs of all theorems quoted here and, instead, will refer to the literature. We start with the definition of an algebra.
Definition 1 Let  be a field. Then, a -algebra, or algebra over , is a -vector space equipped with a binary product,
be a field. Then, a -algebra, or algebra over , is a -vector space equipped with a binary product, 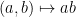 , and identity element
, and identity element 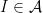 satisfying the following for all
satisfying the following for all  .
.
- Associativity:
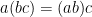 .
.
- Compatability with scalars:
 for all
for all 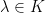 .
.
- Left-distributivity:
 .
.
- Right-distributivity:

- Identity:
 .
.
If, furthermore,  for all
for all 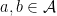 then the algebra is said to be commutative.
then the algebra is said to be commutative.
Strictly speaking, this defines a unitial associative algebra. Sometimes, the axiom of associativity is dropped, although I do not look at such non-associative algebras here. Similarly, the existence of the identity  is sometimes dropped along with its corresponding axiom. In this post, whenever the unqualified term `algebra’ is used, then it refers to a structure satisfying definition 1, so is unitial. Also, I will use the symbol
is sometimes dropped along with its corresponding axiom. In this post, whenever the unqualified term `algebra’ is used, then it refers to a structure satisfying definition 1, so is unitial. Also, I will use the symbol  to denote the identity element. This creates some ambiguity as to whether an expression of the form
to denote the identity element. This creates some ambiguity as to whether an expression of the form  refers to multiplication by the identity element or by the scalar
refers to multiplication by the identity element or by the scalar  . However, as they both evaluate to
. However, as they both evaluate to  , it should not cause any confusion.
, it should not cause any confusion.
A subset  is called commutative if for all
is called commutative if for all  . In particular, the algebra itself is commutative if and only if is commutative as a set of elements. It is also easy to show that the sub-algebra of generated by a commutative set
. In particular, the algebra itself is commutative if and only if is commutative as a set of elements. It is also easy to show that the sub-algebra of generated by a commutative set  (i.e., the smallest subalgebra containing ) is itself commutative. Note that this means that the subalgebra generated by a single element is commutative.
(i.e., the smallest subalgebra containing ) is itself commutative. Note that this means that the subalgebra generated by a single element is commutative.
Examples of algebras abound in mathematics. A small set of examples is:
- Polynomial rings
![{K[X_1,X_2,\ldots,X_n]}](https://s0.wp.com/latex.php?latex=%7BK%5BX_1%2CX_2%2C%5Cldots%2CX_n%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) are commutative -algebras.
are commutative -algebras.
- For a set
 , the collection of functions
, the collection of functions  is a commutative -algebra, where the operations of addition, scalar multiplication, and multiplication are defined point-wise.
is a commutative -algebra, where the operations of addition, scalar multiplication, and multiplication are defined point-wise.
- For a measurable space
 , the collection of
, the collection of  -measurable functions
-measurable functions  is an -algebra.
is an -algebra.
- For a normed real vector space
 , the collection of bounded linear maps
, the collection of bounded linear maps  is an -algebra.
is an -algebra.
We define the notion of a state on a commutative real algebra.
Definition 2 Let be a commutative real algebra. Then, a linear map  is
is
- positive if
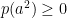 for all
for all 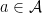 .
.
- a state if it is positive and .
Correspondence with classical probabilities
As discussed above, a classical probability space determines a commutative real algebra, consisting of the bounded random variables, and a state on this algebra given by expectation. The question is, can this process be inverted? When can a state on a commutative real algebra be represented as an expectation on a set of random variables on some probability space? We start by considering a single element . This defines a map ![{{\mathbb R}[X]\rightarrow\mathcal A}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+R%7D%5BX%5D%5Crightarrow%5Cmathcal+A%7D&bg=ffffff&fg=000000&s=0&c=20201002) taking any polynomial
taking any polynomial  to its evaluation
to its evaluation  , and the image is the sub-algebra generated by . For to be considered as a random variable on a probability space, then its distribution
, and the image is the sub-algebra generated by . For to be considered as a random variable on a probability space, then its distribution  is a probability measure on satisfying
is a probability measure on satisfying
 |
(1) |
for all polynomials ![{f\in{\mathbb R}[X]}](https://s0.wp.com/latex.php?latex=%7Bf%5Cin%7B%5Cmathbb+R%7D%5BX%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . By linearity, (1) holds whenever it holds on monomials
. By linearity, (1) holds whenever it holds on monomials 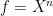 . That is, we require
. That is, we require
for all positive integers  and, for this to make sense, must have finite moments. This is the classical moment problem, to construct a probability measure from its moments. In the one factor case, it is known that the positivity of ensures existence of a solution.
and, for this to make sense, must have finite moments. This is the classical moment problem, to construct a probability measure from its moments. In the one factor case, it is known that the positivity of ensures existence of a solution.
Theorem 3 Let be a state on commutative real algebra . Then, for any , there exists a probability measure on satisfying (1).
The existence of a measure with specified moments is known as the Hamburger problem. Unfortunately, uniqueness need not hold, as there do exist distinct probability measures on with the same moments. As an example, consider the log-normal distribution on the nonnegative reals, and a perturbation of this,
These measures have all the same moments,
and therefore generate the same state on the algebra ![{\mathcal A={\mathbb R}[X]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal+A%3D%7B%5Cmathbb+R%7D%5BX%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . On the other hand, it is not difficult to show that the distribution of a bounded random variable is uniquely determined by its moments. This follows from the Stone–Weierstrass theorem, which states that the polynomials are dense in the space of continuous functions on any closed bounded interval. Furthermore, the distribution will be supported by an interval
. On the other hand, it is not difficult to show that the distribution of a bounded random variable is uniquely determined by its moments. This follows from the Stone–Weierstrass theorem, which states that the polynomials are dense in the space of continuous functions on any closed bounded interval. Furthermore, the distribution will be supported by an interval ![{[-K,K]}](https://s0.wp.com/latex.php?latex=%7B%5B-K%2CK%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) if
if 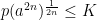 for all positive . It is possible to relax this condition to bounds on the growth of the moments, such as Carleman’s condition (2).
for all positive . It is possible to relax this condition to bounds on the growth of the moments, such as Carleman’s condition (2).
Theorem 4 Let be a state on commutative real algebra . If satisfies
 |
(2) |
then there exists a unique probability measure on satisfying (1).
This result goes back to T. Carleman, Les fonctions quasi analytiques, Gauthier–Villars, Paris, 1926. A proof of this result, and also of the Hamburger problem, is given in the lecture notes, The classical moment problem, by Sasha Sodin, 2019. See Theorem 3.1 and Corollary 2.12.
Moving to the mutifactor situation, where we have a sequence 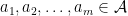 , the aim is to find a probability measure on
, the aim is to find a probability measure on  satisfying
satisfying
 |
(3) |
for all polynomials ![{f\in{\mathbb R}[X_1,\ldots,X_m]}](https://s0.wp.com/latex.php?latex=%7Bf%5Cin%7B%5Cmathbb+R%7D%5BX_1%2C%5Cldots%2CX_m%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) and, as in the single factor case, must have finite moments for this to make sense. Unlike the single factor case, this is not always possible, so theorem 3 does not generalise to
and, as in the single factor case, must have finite moments for this to make sense. Unlike the single factor case, this is not always possible, so theorem 3 does not generalise to 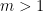 . The reason for this is that there exists multifactor polynomials which are positive on all of , yet cannot be expressed as a sum of squares. Consider
. The reason for this is that there exists multifactor polynomials which are positive on all of , yet cannot be expressed as a sum of squares. Consider
The AM-GM inequality shows that  everywhere on
everywhere on 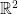 . However, it is not possible to express as
. However, it is not possible to express as 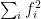 for a finite sequence of polynomials
for a finite sequence of polynomials ![{f_i\in{\mathbb R}[X,Y]}](https://s0.wp.com/latex.php?latex=%7Bf_i%5Cin%7B%5Cmathbb+R%7D%5BX%2CY%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . This means that the definition of positivity for a state on
. This means that the definition of positivity for a state on ![{{\mathbb R}[X,Y]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+R%7D%5BX%2CY%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is insufficient to ensure that
is insufficient to ensure that  , and the hyperplane separation theorem implies the existence of states with
, and the hyperplane separation theorem implies the existence of states with 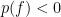 . No such state can arise from the expectation under a probability measure.
. No such state can arise from the expectation under a probability measure.
Fortunately, if sufficient bounds are imposed on the growth of the moments  , then it is possible to show that a unique measure exists satisfying (3). Again, in the case that
, then it is possible to show that a unique measure exists satisfying (3). Again, in the case that  for all
for all 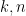 and some real , then the Stone–Weierstrass theorem can be used to show uniqueness of , which must be supported on
and some real , then the Stone–Weierstrass theorem can be used to show uniqueness of , which must be supported on ![{[-K,K]^m}](https://s0.wp.com/latex.php?latex=%7B%5B-K%2CK%5D%5Em%7D&bg=ffffff&fg=000000&s=0&c=20201002) , with the Riesz representation theorem providing existence. These conditions can be weakened considerably and, in fact, it is known that Carleman’s condition for each of the individual elements
, with the Riesz representation theorem providing existence. These conditions can be weakened considerably and, in fact, it is known that Carleman’s condition for each of the individual elements 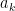 is sufficient to guarantee existence and uniqueness.
is sufficient to guarantee existence and uniqueness.
Theorem 5 Let be a state on commutative real algebra . If  each satisfy Carleman’s condition (2) then there is a unique probability measure on satisfying (3).
each satisfy Carleman’s condition (2) then there is a unique probability measure on satisfying (3).
This result originates from Nussbaum, A. E., Quasi-analytic vectors, Arkiv för Matematik. 6 (1965), no. 2, 179–191.
Taking the idea a step further, we can consider infinite subsets  of . Let
of . Let  be the space of functions
be the space of functions  and
and  denote the coordinate map
denote the coordinate map  . Let be the sigma-algebra on generated by
. Let be the sigma-algebra on generated by 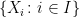 . That is, is the smallest sigma-algebra on with respect to which each
. That is, is the smallest sigma-algebra on with respect to which each  is measurable. In particular, it is generated by the sets
is measurable. In particular, it is generated by the sets  for Borel
for Borel 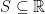 . The collection
. The collection  generates an algebra
generates an algebra  of random variables, which can be expressed as real polynomials in . Evaluating the polynomials at the values
of random variables, which can be expressed as real polynomials in . Evaluating the polynomials at the values  gives an algebra homomorphism
gives an algebra homomorphism 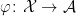 . The aim is to find a probability measure on
. The aim is to find a probability measure on 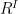 satisfying
satisfying
![\displaystyle {\mathbb E}[X]=p(\varphi(X))](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7B%5Cmathbb+E%7D%5BX%5D%3Dp%28%5Cvarphi%28X%29%29+&bg=ffffff&fg=000000&s=0&c=20201002) |
(4) |
for all  which, to make sense, requires to be integrable.
which, to make sense, requires to be integrable.
If we choose to be a generating set for , so that the smallest subalgebra of containing every is all of , then we obtain a representation of 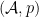 as an algebra of random variables on a probability space together with the expectation operator.
as an algebra of random variables on a probability space together with the expectation operator.
Theorem 6 Let be a state on commutative real algebra . If  each satisfy Carleman’s condition (2) then, there exists a unique probability measure on satisfying (4).
each satisfy Carleman’s condition (2) then, there exists a unique probability measure on satisfying (4).
Proof: For each finite subset 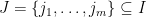 , theorem 5 uniquely determines a probability measure
, theorem 5 uniquely determines a probability measure  on
on  satisfying
satisfying
for all polynomials .
Define the projection map  by
by  for all
for all 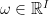 and
and 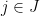 . For a probability measure on , the pushforward measure
. For a probability measure on , the pushforward measure  on is defined by
on is defined by 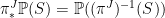 . Condition (4) is then,
. Condition (4) is then,
or, equivalently, 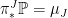 . Existence and uniqueness of follows from Kolmogorov’s extension theorem. ⬜
. Existence and uniqueness of follows from Kolmogorov’s extension theorem. ⬜
Continued…




![\displaystyle f=1+X^4Y^2+X^2Y^4-3X^2Y^2\in{\mathbb R}[X,Y].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+f%3D1%2BX%5E4Y%5E2%2BX%5E2Y%5E4-3X%5E2Y%5E2%5Cin%7B%5Cmathbb+R%7D%5BX%2CY%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rl} \displaystyle p(f(a_{j_1},\ldots,a_{j_m}))&\displaystyle={\mathbb E}[f(X_{j_1},\ldots,X_{j_m})]\smallskip\\ &\displaystyle=\int f(\omega(j_1),\ldots,\omega(j_m))d{\mathbb P}(\omega)\smallskip\\ &\displaystyle=\int f(\omega(j_1),\ldots,\omega(j_m))d\pi^J_*{\mathbb P}(\omega) \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brl%7D+%5Cdisplaystyle+p%28f%28a_%7Bj_1%7D%2C%5Cldots%2Ca_%7Bj_m%7D%29%29%26%5Cdisplaystyle%3D%7B%5Cmathbb+E%7D%5Bf%28X_%7Bj_1%7D%2C%5Cldots%2CX_%7Bj_m%7D%29%5D%5Csmallskip%5C%5C+%26%5Cdisplaystyle%3D%5Cint+f%28%5Comega%28j_1%29%2C%5Cldots%2C%5Comega%28j_m%29%29d%7B%5Cmathbb+P%7D%28%5Comega%29%5Csmallskip%5C%5C+%26%5Cdisplaystyle%3D%5Cint+f%28%5Comega%28j_1%29%2C%5Cldots%2C%5Comega%28j_m%29%29d%5Cpi%5EJ_%2A%7B%5Cmathbb+P%7D%28%5Comega%29+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)

This a great post, I can’t wait to read the continued notes. I have a question on the example ,we can indeed prove that
,we can indeed prove that  using AM-GM inequality. But I didn’t not understand the sentence that
using AM-GM inequality. But I didn’t not understand the sentence that  cannot be expressed as
cannot be expressed as 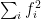 , do you mean that each
, do you mean that each 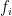 is a polynomial in one variable, otherwise we can write
is a polynomial in one variable, otherwise we can write  . Also, can you develop a little bit how do you use the hyperplane separation theorem to prove the existence of states with
. Also, can you develop a little bit how do you use the hyperplane separation theorem to prove the existence of states with  ? Thanks
? Thanks
I mean that each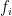 is in
is in ![\mathbb R[X,Y]](https://s0.wp.com/latex.php?latex=%5Cmathbb+R%5BX%2CY%5D&bg=ffffff&fg=000000&s=0&c=20201002) [I edited]. I might come back and add some detail on the use of the hyperplane separation theorem, but it is intended as a brief counterexample and was wanting to get some new posts up first. Alternatively, should be able to find reference giving more detail on this.
[I edited]. I might come back and add some detail on the use of the hyperplane separation theorem, but it is intended as a brief counterexample and was wanting to get some new posts up first. Alternatively, should be able to find reference giving more detail on this.
Thank you for your quick reply. I can wait , atfer all I really want to learn the quantum part note.