Given a sequence 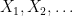 of real-valued random variables defined on a probability space
of real-valued random variables defined on a probability space 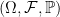 , it is a standard result that the supremum
, it is a standard result that the supremum

is measurable. To ensure that this is well-defined, we need to allow X to have values in 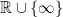 , so that
, so that 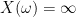 whenever the sequence
whenever the sequence  is unbounded above. The proof of this fact is simple. We just need to show that
is unbounded above. The proof of this fact is simple. We just need to show that ![{X^{-1}((-\infty,a])}](https://s0.wp.com/latex.php?latex=%7BX%5E%7B-1%7D%28%28-%5Cinfty%2Ca%5D%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) is in
is in  for all
for all 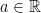 . Writing,
. Writing,
![\displaystyle X^{-1}((-\infty,a])=\bigcap_nX_n^{-1}((-\infty,a]),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++X%5E%7B-1%7D%28%28-%5Cinfty%2Ca%5D%29%3D%5Cbigcap_nX_n%5E%7B-1%7D%28%28-%5Cinfty%2Ca%5D%29%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
the properties that 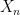 are measurable and that the sigma-algebra is closed under countable intersections gives the result.
are measurable and that the sigma-algebra is closed under countable intersections gives the result.
The measurability of the suprema of sequences of random variables is a vital property, used throughout probability theory. However, once we start looking at uncountable collections of random variables things get more complicated. Given a, possibly uncountable, collection of random variables  , the supremum
, the supremum  is,
is,
 |
(1) |
However, there are a couple of reasons why this is often not a useful construction:
The essential supremum can be used to correct these deficiencies, and has been important in several places in my notes. See, for example, the proof of the debut theorem for right-continuous processes. So, I am posting this to use as a reference. Note that there is an alternative use of the term `essential supremum’ to refer to the smallest real number almost surely bounding a specified random variable, which is the one referred to by Wikipedia. This is different from the use here, where we look at a collection of random variables and the essential supremum is itself a random variable.
The essential supremum is really just the supremum taken within the equivalence classes of random variables under the almost sure ordering. Consider the equivalence relation  if and only if
if and only if  almost surely. Writing
almost surely. Writing ![{[X]}](https://s0.wp.com/latex.php?latex=%7B%5BX%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) for the equivalence class of X, we can consider the ordering given by
for the equivalence class of X, we can consider the ordering given by ![{[X]\le[Y]}](https://s0.wp.com/latex.php?latex=%7B%5BX%5D%5Cle%5BY%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) if
if  almost surely. Then, the equivalence class of the essential supremum of a collection of random variables is the supremum of the equivalence classes of the elements of . In order to avoid issues with unbounded sets, we consider random variables taking values in the extended reals
almost surely. Then, the equivalence class of the essential supremum of a collection of random variables is the supremum of the equivalence classes of the elements of . In order to avoid issues with unbounded sets, we consider random variables taking values in the extended reals 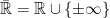 .
.
Definition 1 An essential supremum of a collection of 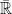 -valued random variables,
-valued random variables,

is the least upper bound of 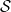 , using the almost-sure ordering on random variables. That is, S is an -valued random variable satisfying
, using the almost-sure ordering on random variables. That is, S is an -valued random variable satisfying
- upper bound:
 almost surely, for all
almost surely, for all  .
.
- minimality: for all -valued random variables Y satisfying
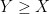 almost surely for all , we have
almost surely for all , we have  almost surely.
almost surely.
Continue reading “Essential Suprema” →
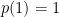
is a positive linear map
satisfying
be a probability space, and
. Then, integration w.r.t.
defines a state on

be an inner product space, and
as in example 2 of the previous post, and including the identity map
. Then, any
with
defines a state on

 to denote the complex conjugate of a complex number
to denote the complex conjugate of a complex number  .
. is a
is a 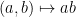 satisfying
satisfying 
 and
and 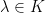 .
.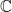 with a unary involution,
with a unary involution,  satisfying
satisfying
 .
. such that
such that
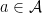 . Then,
. Then,  is called the unit or identity of
is called the unit or identity of 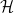 , which is used to represent the states of the system. This is a vector space over the complex numbers, together with an inner product
, which is used to represent the states of the system. This is a vector space over the complex numbers, together with an inner product 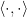 . By definition, this is linear in one argument and anti-linear in the other,
. By definition, this is linear in one argument and anti-linear in the other,
 and
and  for
for  . I am using the physicists’ convention, where the inner product is linear in the second argument and anti-linear in the first. Furthermore, physicists often use the
. I am using the physicists’ convention, where the inner product is linear in the second argument and anti-linear in the first. Furthermore, physicists often use the  , which can be split up into the `bra’
, which can be split up into the `bra’  and `ket’
and `ket’  considered as elements of the dual space of
considered as elements of the dual space of 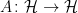 , the expression
, the expression  is often expressed as
is often expressed as  in the physicists’ language. By the Hilbert space definition,
in the physicists’ language. By the Hilbert space definition,  .
.  ,
,  .
.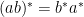 .
.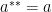
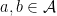 and
and  , an event space
, an event space 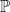 . The measure
. The measure  satisfying countable additivity and normalised as
satisfying countable additivity and normalised as 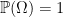 .
.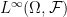 of all bounded measurable functions
of all bounded measurable functions 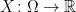 . This is a real vector space and, as it is closed under multiplication, is an algebra. Expectation, by definition, is the unique linear map
. This is a real vector space and, as it is closed under multiplication, is an algebra. Expectation, by definition, is the unique linear map  ,
, ![{X\mapsto{\mathbb E}[X]}](https://s0.wp.com/latex.php?latex=%7BX%5Cmapsto%7B%5Cmathbb+E%7D%5BX%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) satisfying
satisfying ![{{\mathbb E}[1_A]={\mathbb P}(A)}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5B1_A%5D%3D%7B%5Cmathbb+P%7D%28A%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) for
for 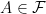 and monotone convergence: if
and monotone convergence: if 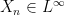 is a nonnegative sequence increasing to a bounded limit
is a nonnegative sequence increasing to a bounded limit  , then
, then ![{{\mathbb E}[X_n]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BX_n%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) tends to
tends to ![{{\mathbb E}[X]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BX%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.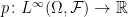 satisfying monotone convergence and
satisfying monotone convergence and 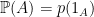 . This is the unique measure with respect to which expectation agrees with the linear map,
. This is the unique measure with respect to which expectation agrees with the linear map,  . So, probability measures are in one-to-one correspondence with such linear maps, and they can be viewed as one and the same thing. The Kolmogorov definition of a probability space can be thought of as representing the expectation on the subset of
. So, probability measures are in one-to-one correspondence with such linear maps, and they can be viewed as one and the same thing. The Kolmogorov definition of a probability space can be thought of as representing the expectation on the subset of  consisting of indicator functions
consisting of indicator functions 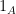 . In practice, it is often more convenient to start with a different subset of
. In practice, it is often more convenient to start with a different subset of  can be defined via their Laplace transform,
can be defined via their Laplace transform,  , which represents the expectation on exponential functions
, which represents the expectation on exponential functions  . Generalising to complex-valued random variables, probability measures on
. Generalising to complex-valued random variables, probability measures on 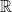 are often represented by their characteristic function
are often represented by their characteristic function  , which is just the expectation of the complex exponentials
, which is just the expectation of the complex exponentials  . In fact, by the
. In fact, by the  by the expectations on any subset
by the expectations on any subset 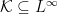 which is closed under taking products and generates the sigma-algebra
which is closed under taking products and generates the sigma-algebra  -system lemma, are simple but fundamental theorems in measure theory, and form an essential step in the proofs of many results. General measurable sets are difficult to describe explicitly so, when proving results in measure theory, it is often necessary to start by considering much simpler sets. The monotone class theorem is then used to extend to arbitrary measurable sets. For example, when proving a result about
-system lemma, are simple but fundamental theorems in measure theory, and form an essential step in the proofs of many results. General measurable sets are difficult to describe explicitly so, when proving results in measure theory, it is often necessary to start by considering much simpler sets. The monotone class theorem is then used to extend to arbitrary measurable sets. For example, when proving a result about ![{\Omega=[0,1]}](https://s0.wp.com/latex.php?latex=%7B%5COmega%3D%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) with
with ![{a\in[0,1]}](https://s0.wp.com/latex.php?latex=%7Ba%5Cin%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) define the random variable
define the random variable 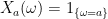 and, for a subset A of
and, for a subset A of ![{[0,1]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , consider the collection of random variables
, consider the collection of random variables  . Its supremum is
. Its supremum is

 be the random variables on
be the random variables on ![{\mathcal S=\{X_a\colon a\in[0,1]\}}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal+S%3D%5C%7BX_a%5Ccolon+a%5Cin%5B0%2C1%5D%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Its supremum is the constant function
. Its supremum is the constant function  . As every
. As every 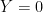 . So, the supremum
. So, the supremum 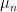 to denote the standard n-dimensional
to denote the standard n-dimensional 
 . By symmetric, we mean symmetric about the origin, so that
. By symmetric, we mean symmetric about the origin, so that 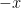 is in A if and only
is in A if and only  is in A, and similarly for B. The standard Gaussian measure by definition has zero mean and covariance matrix equal to the nxn identity matrix, so that
is in A, and similarly for B. The standard Gaussian measure by definition has zero mean and covariance matrix equal to the nxn identity matrix, so that
 denoting the Lebesgue integral on
denoting the Lebesgue integral on 