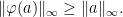In an earlier post, I described four simple thought experiments, involving some black boxes and two or more participants. As described there, the results of these experiments were inconsistent with any classical description, assuming that the boxes cannot communicate. However, I also stated that all of these experiments are consistent with quantum probability, and that I would give the mathematical details in a further post. I will do this now. Continue reading “Quantum Entanglement States”
Category: Probability Theory
Quantum Entanglement
Quantum entanglement is one of the most striking differences between the behaviour of the universe described by quantum theory, and that given by classical physics. If two physical systems interact then, even if they later separate, their future evolutions can no longer be considered purely in isolation. Any attempt to describe the systems with classical logic leads inevitably to an apparent link between them, where simply observing one instantaneously impacts the state of the other. This effect remains, regardless of how far apart the systems become.

As it is a very famous quantum phenomenon, a lot has been written about entanglement in both the scientific and popular literature. However, it does still seem to be frequently misunderstood, with many surrounding misconceptions. I will attempt to explain the effects of entanglement in as straightforward a way as possible, with some very basic thought experiments. These can be followed without any understanding of what physical processes may be going on underneath. They only involve pressing a button on a box and observing the colour of a light bulb mounted on it. In fact, this is one of the features of quantum entanglement. It does not matter how you describe the physical world, whether you think of things as particles, waves, or whatever. Entanglement is an observable property independently of how, or even if, we try to describe the physical processes. Continue reading “Quantum Entanglement”
The Khintchine Inequality
For a Rademacher sequence 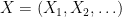


We use 

for the associated Banach norm.
Theorem 1 (Khintchine) For each
, there exists positive constants
such that,
(1) for all
.
![\displaystyle c_p\lVert a\rVert_2^p\le{\mathbb E}\left[\lvert a\cdot X\rvert^p\right]\le C_p\lVert a\rVert_2^p,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++c_p%5ClVert+a%5CrVert_2%5Ep%5Cle%7B%5Cmathbb+E%7D%5Cleft%5B%5Clvert+a%5Ccdot+X%5Crvert%5Ep%5Cright%5D%5Cle+C_p%5ClVert+a%5CrVert_2%5Ep%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
Rademacher Series
The Rademacher distribution is probably the simplest nontrivial probability distribution that you can imagine. This is a discrete distribution taking only the two possible values 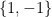
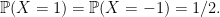
A Randemacher sequence is an IID sequence of Rademacher random variables,
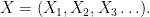
Recall that the partial sums 
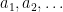
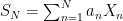
Rademacher series serve as simple prototypes of more general IID series, but also have applications in various areas. Results include concentration and anti-concentration inequalities, and the Khintchine inequality, which imply various properties of 
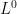
Completions of *-Probability Spaces
We previously defined noncommutative probability spaces as a *-algebra together with a nondegenerate state satisfying a completeness property. Justification for the stated definition was twofold. First, an argument similar to the construction of measurable random variables on classical probability spaces was used, by taking all possible limits for which an expectation can reasonably be defined. Second, I stated various natural mathematical properties of this construction, including the existence of completions and their functorial property, which allows us to pass from preprobability spaces, and homomorphisms between these, to the NC probability spaces which they generate. However, the statements were given without proof, so the purpose of the current post is to establish these results. Specifically, I will give proofs of each of the theorems stated in the post on noncommutative probability spaces, with the exception of the two theorems relating commutative *-probability spaces to their classical counterpart (theorems 2 and 10), which will be looked at in a later post. Continue reading “Completions of *-Probability Spaces”
Noncommutative Probability Spaces
In classical probability theory, we start with a sample space 

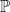

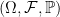

![\displaystyle \setlength\arraycolsep{2pt} \begin{array}{rl} &\displaystyle L^\infty(\Omega,\mathcal F,{\mathbb P})\rightarrow{\mathbb C},\smallskip\\ &\displaystyle X\mapsto{\mathbb E}[X]=\int X(\omega)d{\mathbb P}(\omega). \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csetlength%5Carraycolsep%7B2pt%7D+%5Cbegin%7Barray%7D%7Brl%7D+%26%5Cdisplaystyle+L%5E%5Cinfty%28%5COmega%2C%5Cmathcal+F%2C%7B%5Cmathbb+P%7D%29%5Crightarrow%7B%5Cmathbb+C%7D%2C%5Csmallskip%5C%5C+%26%5Cdisplaystyle+X%5Cmapsto%7B%5Cmathbb+E%7D%5BX%5D%3D%5Cint+X%28%5Comega%29d%7B%5Cmathbb+P%7D%28%5Comega%29.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
In this post I provide definitions of probability spaces from the algebraic viewpoint. Statements of some of their first properties will be given in order to justify and clarify the definitions, although any proofs will be left until later posts. In the algebraic setting, we begin with a *-algebra 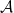
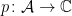

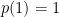
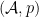

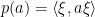

The GNS Representation
As is well known, the space of bounded linear operators on any Hilbert space forms a *-algebra, and (pure) states on this algebra are defined by unit vectors. Considering a Hilbert space 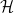
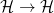


for any 
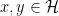
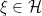
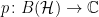
The Gelfand-Naimark–Segal (GNS) representation allows us to go in the opposite direction and, starting from a state on an abstract *-algebra, realises this as a pure state on a *-subalgebra of
Consider a *-algebra 
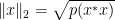

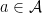
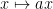
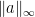

Theorem 1 Let
where,
is a *-homomorphism.
for all
is dense in
Furthermore, this representation is unique up to isomorphism: if
is any other such triple, then there exists a unique invertible linear isometry of Hilbert spaces
such that

Normal Maps
Given two *-probability spaces 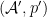

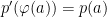
In contrast to the previous few posts on algebraic probability, the current post is a bit of a gear-change. We are still concerned with with the basic concepts of *-algebras and states. However, the main theorem stated below, which reduces to the Radon-Nikodym theorem in the commutative case, is deeper and much more difficult to prove than the relatively simple results with which I have been concerned with so far. Continue reading “Normal Maps”
Operator Topologies
We previously defined the notion of positive linear maps and states on *-algebras, and noted that there always exists seminorms defining the
Weak convergence on a *-probability space 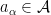



Homomorphisms of *-Probability Spaces
I previously introduced the concept of a *-probability space as a pair
A *-homomorphism between *-algebras 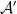

for all 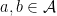

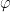

for all
Now, recall that for any *-probability space 

For each 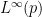
Lemma 1 If
is a homomorphism of *-probability spaces then, for any
(1)