For a Rademacher sequence 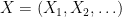 and square summable sequence of real numbers
and square summable sequence of real numbers  , the Khintchine inequality provides upper and lower bounds for the moments of the random variable,
, the Khintchine inequality provides upper and lower bounds for the moments of the random variable,

We use  for the space of square summable real sequences and
for the space of square summable real sequences and

for the associated Banach norm.
Theorem 1 (Khintchine) For each  , there exists positive constants
, there exists positive constants  such that,
such that,
![\displaystyle c_p\lVert a\rVert_2^p\le{\mathbb E}\left[\lvert a\cdot X\rvert^p\right]\le C_p\lVert a\rVert_2^p,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++c_p%5ClVert+a%5CrVert_2%5Ep%5Cle%7B%5Cmathbb+E%7D%5Cleft%5B%5Clvert+a%5Ccdot+X%5Crvert%5Ep%5Cright%5D%5Cle+C_p%5ClVert+a%5CrVert_2%5Ep%2C+&bg=ffffff&fg=000000&s=0&c=20201002) |
(1) |
for all  .
.
Note the similarity to the Burkholder-Davis-Gundy inequality. In fact, the process 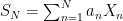 is a martingale, with time index N. Then, the quadratic variation
is a martingale, with time index N. Then, the quadratic variation ![{[S]_\infty}](https://s0.wp.com/latex.php?latex=%7B%5BS%5D_%5Cinfty%7D&bg=ffffff&fg=000000&s=0&c=20201002) is equal to
is equal to  , and (1) can be regarded as a special case of the BDG inequality — at least, when p is greater than one. However, the Khintchine inequality is much easier to prove. I will give a proof in a moment but, first, there are some simple observations that can be made. We already know, from the previous post, that the map
, and (1) can be regarded as a special case of the BDG inequality — at least, when p is greater than one. However, the Khintchine inequality is much easier to prove. I will give a proof in a moment but, first, there are some simple observations that can be made. We already know, from the previous post, that the map 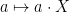 is an isometry between and
is an isometry between and  . That is,
. That is,
![\displaystyle {\mathbb E}[(a\cdot X)^2]=\lVert a\rVert_2^2.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5B%28a%5Ccdot+X%29%5E2%5D%3D%5ClVert+a%5CrVert_2%5E2.+&bg=ffffff&fg=000000&s=0&c=20201002)
So, the Khintchine inequality for 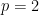 is trivial, and we can take
is trivial, and we can take  . Also, it is a simple application of Jensen’s inequality to show that
. Also, it is a simple application of Jensen’s inequality to show that ![{{\mathbb E}[Z^p]^{1/p}}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BZ%5Ep%5D%5E%7B1%2Fp%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is increasing in p, for any nonnegative random variable Z. Specifically, for
is increasing in p, for any nonnegative random variable Z. Specifically, for  , convexity of the map
, convexity of the map  gives,
gives,
![\displaystyle {\mathbb E}[Z^p]^{1/p}=\left({\mathbb E}[Z^p]^{q/p}\right)^{1/q}\le{\mathbb E}[Z^q]^{1/q}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5BZ%5Ep%5D%5E%7B1%2Fp%7D%3D%5Cleft%28%7B%5Cmathbb+E%7D%5BZ%5Ep%5D%5E%7Bq%2Fp%7D%5Cright%29%5E%7B1%2Fq%7D%5Cle%7B%5Cmathbb+E%7D%5BZ%5Eq%5D%5E%7B1%2Fq%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
Hence,
![\displaystyle {\mathbb E}[\lvert a\cdot X\rvert^p]\le{\mathbb E}[(a\cdot X)^2]^{p/2}=\lVert a\rVert_2^p](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5B%5Clvert+a%5Ccdot+X%5Crvert%5Ep%5D%5Cle%7B%5Cmathbb+E%7D%5B%28a%5Ccdot+X%29%5E2%5D%5E%7Bp%2F2%7D%3D%5ClVert+a%5CrVert_2%5Ep+&bg=ffffff&fg=000000&s=0&c=20201002)
for all 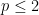 . We immediately see that the right-hand Khintchine inequality holds with
. We immediately see that the right-hand Khintchine inequality holds with 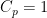 for . Similarly, for
for . Similarly, for 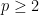 ,
,
![\displaystyle {\mathbb E}[\lvert a\cdot X\rvert^p]\ge{\mathbb E}[(a\cdot X)^2]^{p/2}=\lVert a\rVert_2^p,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5B%5Clvert+a%5Ccdot+X%5Crvert%5Ep%5D%5Cge%7B%5Cmathbb+E%7D%5B%28a%5Ccdot+X%29%5E2%5D%5E%7Bp%2F2%7D%3D%5ClVert+a%5CrVert_2%5Ep%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
and we see that the left-hand Khintchine inequality holds with 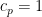 . So, the only non-trivial cases of (1) are the left-hand inequality for
. So, the only non-trivial cases of (1) are the left-hand inequality for  and the right-hand one for
and the right-hand one for  .
.
Proof of Theorem 1: We start with the right-hand inequality, by making use of inequality (2) from the previous post,
![\displaystyle \begin{aligned} {\mathbb E}[\cosh(\lambda a\cdot X)] &=\frac12{\mathbb E}[e^{\lambda a\cdot X}+e^{-\lambda a\cdot X}]\\ &\le e^{\frac12\lambda^2\lVert a\rVert_2^2}, \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5B%5Ccosh%28%5Clambda+a%5Ccdot+X%29%5D+%26%3D%5Cfrac12%7B%5Cmathbb+E%7D%5Be%5E%7B%5Clambda+a%5Ccdot+X%7D%2Be%5E%7B-%5Clambda+a%5Ccdot+X%7D%5D%5C%5C+%26%5Cle+e%5E%7B%5Cfrac12%5Clambda%5E2%5ClVert+a%5CrVert_2%5E2%7D%2C+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
for any fixed positive  . Since
. Since  grows faster than
grows faster than  , for any , there exists a positive constant
, for any , there exists a positive constant  satisfying
satisfying  . Hence,
. Hence,
![\displaystyle \lambda^p{\mathbb E}[\lvert a\cdot X\rvert^p]\le B_p{\mathbb E}[\cosh(\lambda a\cdot X)]\le B_p e^{\frac12\lambda^2\lVert a\rVert_2^2}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Clambda%5Ep%7B%5Cmathbb+E%7D%5B%5Clvert+a%5Ccdot+X%5Crvert%5Ep%5D%5Cle+B_p%7B%5Cmathbb+E%7D%5B%5Ccosh%28%5Clambda+a%5Ccdot+X%29%5D%5Cle+B_p+e%5E%7B%5Cfrac12%5Clambda%5E2%5ClVert+a%5CrVert_2%5E2%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
Dividing by 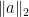 gives
gives
![\displaystyle {\mathbb E}[\lvert a\cdot X\rvert^p]\le C_p\lVert a\rVert_2^p.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5B%5Clvert+a%5Ccdot+X%5Crvert%5Ep%5D%5Cle+C_p%5ClVert+a%5CrVert_2%5Ep.+&bg=ffffff&fg=000000&s=0&c=20201002)
with the constant  .
.
The left-hand Khintchine inequality follows from the right-hand one, by making use of the fact that ![{{\mathbb E}[\lvert a\cdot X\rvert^p]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5B%5Clvert+a%5Ccdot+X%5Crvert%5Ep%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is log-convex in p (see lemma 2 below). Since we have already noted that for , we assume that . Choosing any
is log-convex in p (see lemma 2 below). Since we have already noted that for , we assume that . Choosing any  , log-convexity gives
, log-convexity gives
![\displaystyle \begin{aligned} \lVert a\rVert_2^{2(q-p)} &={\mathbb E}[\lvert a\cdot X\rvert^2]^{q-p}\\ &\le{\mathbb E}[\lvert a\cdot X\rvert^p]^{q-2}{\mathbb E}[\lvert a\cdot X\rvert^q]^{2-p}\\ &\le{\mathbb E}[\lvert a\cdot X\rvert^p]^{q-2}C_q^{2-p}\lVert a\rVert_2^{q(2-p)}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%5ClVert+a%5CrVert_2%5E%7B2%28q-p%29%7D+%26%3D%7B%5Cmathbb+E%7D%5B%5Clvert+a%5Ccdot+X%5Crvert%5E2%5D%5E%7Bq-p%7D%5C%5C+%26%5Cle%7B%5Cmathbb+E%7D%5B%5Clvert+a%5Ccdot+X%5Crvert%5Ep%5D%5E%7Bq-2%7D%7B%5Cmathbb+E%7D%5B%5Clvert+a%5Ccdot+X%5Crvert%5Eq%5D%5E%7B2-p%7D%5C%5C+%26%5Cle%7B%5Cmathbb+E%7D%5B%5Clvert+a%5Ccdot+X%5Crvert%5Ep%5D%5E%7Bq-2%7DC_q%5E%7B2-p%7D%5ClVert+a%5CrVert_2%5E%7Bq%282-p%29%7D.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Rearranging gives the result with  . ⬜
. ⬜
A function 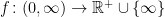 is log-convex if
is log-convex if 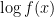 is convex or, equivalently,
is convex or, equivalently,

for all 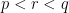 . In the proof above, I made use of log-convexity of the moments. This is equivalent to the statement that moment generating functions are log-convex. For completeness, I include a brief proof of this standard fact.
. In the proof above, I made use of log-convexity of the moments. This is equivalent to the statement that moment generating functions are log-convex. For completeness, I include a brief proof of this standard fact.
Lemma 2 Let Z be a nonnegative random variable. Then, ![{{\mathbb E}[Z^p]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BZ%5Ep%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is log-convex over .
is log-convex over .
Proof: One method is to simply differentiate ![{\log{\mathbb E}[Z^p]}](https://s0.wp.com/latex.php?latex=%7B%5Clog%7B%5Cmathbb+E%7D%5BZ%5Ep%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) twice with respect to p. Alternatively, for , set
twice with respect to p. Alternatively, for , set  and
and  so that
so that  . Applying Hölder’s inequality gives the result,
. Applying Hölder’s inequality gives the result,
![\displaystyle {\mathbb E}[Z^r] ={\mathbb E}\left[Z^{\frac{p}{p^\prime}}Z^{\frac{q}{q^\prime}}\right] \le{\mathbb E}[Z^p]^{\frac1{p^\prime}}{\mathbb E}[Z^q]^{\frac1{q^\prime}}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5BZ%5Er%5D+%3D%7B%5Cmathbb+E%7D%5Cleft%5BZ%5E%7B%5Cfrac%7Bp%7D%7Bp%5E%5Cprime%7D%7DZ%5E%7B%5Cfrac%7Bq%7D%7Bq%5E%5Cprime%7D%7D%5Cright%5D+%5Cle%7B%5Cmathbb+E%7D%5BZ%5Ep%5D%5E%7B%5Cfrac1%7Bp%5E%5Cprime%7D%7D%7B%5Cmathbb+E%7D%5BZ%5Eq%5D%5E%7B%5Cfrac1%7Bq%5E%5Cprime%7D%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
⬜
An alternative way of looking at the Khintchine inequality is that it says that, on the space of Rademacher series, the  topologies all coincide. I will use
topologies all coincide. I will use  to denote
to denote ![{{\mathbb E}[\lvert Z\rvert^p]^{1/p}}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5B%5Clvert+Z%5Crvert%5Ep%5D%5E%7B1%2Fp%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Over
. Over 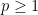 , it is well-known that this is a Banach norm. However, it defines a topology for each , so that convergence of a sequence of random variables
, it is well-known that this is a Banach norm. However, it defines a topology for each , so that convergence of a sequence of random variables 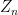 to a limit
to a limit  in the topology is equivalent to
in the topology is equivalent to 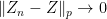 .
.
Lemma 3 Let V be a linear subspace of  for some
for some  . v Then, the and
. v Then, the and 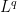 topologies are equivalent on V if and only if there exists positive constants
topologies are equivalent on V if and only if there exists positive constants 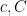 satisfying,
satisfying,
 |
(2) |
for all 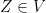 .
.
Proof: First, if (2) holds, then it is immediate that a sequence converges in if and only if it converges in , so we look at the converse. Using proof by contradiction, suppose that there was no constant C for which the right-hand inequality holds. Then, there exists a sequence  such that
such that 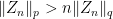 . By scaling, we can assume that
. By scaling, we can assume that  . However, this gives
. However, this gives 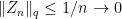 so, by assumption, we also have convergence in the topology giving the contradiction
so, by assumption, we also have convergence in the topology giving the contradiction  .
.
We have shown that the right-hand inequality of (2) holds for some positive constant C, and the left hand inequality follows by exchanging the role of p and q. ⬜
These ideas extend to the 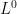 topology, which is just convergence in probability.
topology, which is just convergence in probability.
Lemma 4 Let V be a linear subspace of for some . Then, the and topologies are equivalent on V if and only if there exists strictly positive constants 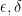 satisfying,
satisfying,
 |
(3) |
for all .
Proof: First, it is standard that convergence in in the topology implies convergence in probability. To be explicit, if 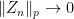 for a sequence then, for each
for a sequence then, for each  ,
,
![\displaystyle \begin{aligned} {\mathbb P}(\lvert Z_n\rvert \ge \epsilon) &={\mathbb E}[1_{\{\lvert Z_n\rvert\ge\epsilon\}}]\le{\mathbb E}[\epsilon^{-p}\lvert Z_n\rvert^p]\\ &=\epsilon^{-p}\lVert Z_n\rVert_p^p\rightarrow0 \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+P%7D%28%5Clvert+Z_n%5Crvert+%5Cge+%5Cepsilon%29+%26%3D%7B%5Cmathbb+E%7D%5B1_%7B%5C%7B%5Clvert+Z_n%5Crvert%5Cge%5Cepsilon%5C%7D%7D%5D%5Cle%7B%5Cmathbb+E%7D%5B%5Cepsilon%5E%7B-p%7D%5Clvert+Z_n%5Crvert%5Ep%5D%5C%5C+%26%3D%5Cepsilon%5E%7B-p%7D%5ClVert+Z_n%5CrVert_p%5Ep%5Crightarrow0+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
as required. Conversely, suppose that (3) holds for given 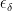 and that tends to zero in probability. We need to show that . If this was not the case then, by passing to a subsequence, we would have
and that tends to zero in probability. We need to show that . If this was not the case then, by passing to a subsequence, we would have  for some fixed positive K. So,
for some fixed positive K. So,

contradicting (3).
Finally, supposing that the and topologies coincide, we just need to show that (3) holds. I use proof by contradiction so, suppose that (3) does not hold for any 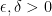 . Then, there exists a sequence satisfying
. Then, there exists a sequence satisfying

By scaling, we can suppose that so that, in particular, the sequence does not tend to zero in . However, for any  we have
we have

for 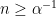 . This shows that tends to zero in but not in , contradicting the initial assumption. ⬜
. This shows that tends to zero in but not in , contradicting the initial assumption. ⬜
Statements such as (3) are known as anti-concentration inequalities, and bound, from above, the probability that a random variable can be within a given distance of its mean. So, to show the equivalence of the and topologies for Rademacher series, it is only really necessary to prove a single non-trivial anti-concentration inequality.
Lemma 5 Let X be a Rademacher sequence and . Then,
 |
(4) |
for all  .
.
Proof: Using 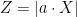 , the Paley-Zygmund inequality gives
, the Paley-Zygmund inequality gives
![\displaystyle \begin{aligned} {\mathbb P}(Z \ge x\lVert a\rVert_2) &={\mathbb P}(Z^2\ge x^2{\mathbb E}[Z^2])\\ &\ge(1-x^2)^2\frac{{\mathbb E}[Z^2]^2}{{\mathbb E}[Z^4]}\\ &\ge\frac1{C_4}(1-x^2)^2. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+P%7D%28Z+%5Cge+x%5ClVert+a%5CrVert_2%29+%26%3D%7B%5Cmathbb+P%7D%28Z%5E2%5Cge+x%5E2%7B%5Cmathbb+E%7D%5BZ%5E2%5D%29%5C%5C+%26%5Cge%281-x%5E2%29%5E2%5Cfrac%7B%7B%5Cmathbb+E%7D%5BZ%5E2%5D%5E2%7D%7B%7B%5Cmathbb+E%7D%5BZ%5E4%5D%7D%5C%5C+%26%5Cge%5Cfrac1%7BC_4%7D%281-x%5E2%29%5E2.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Here, the left-hand Khintchine inequality was used in the final inequality. In fact, we can use  , giving (4).
, giving (4).
Note that  is antisymmetric in flipping the sign of
is antisymmetric in flipping the sign of 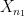 whenever
whenever 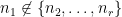 , so has zero expectation. Hence, writing , we obtain
, so has zero expectation. Hence, writing , we obtain
![\displaystyle \begin{aligned} {\mathbb E}[S_N^4] &=\sum_{n=1}^Na_n^4+6\sum_{1\le m < n\le N}a_ma_n\\ &=3\left(\sum_{n=1}^Na_n^2\right)^2-2\sum_{n=1}^Na_n^4. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5BS_N%5E4%5D+%26%3D%5Csum_%7Bn%3D1%7D%5ENa_n%5E4%2B6%5Csum_%7B1%5Cle+m+%3C+n%5Cle+N%7Da_ma_n%5C%5C+%26%3D3%5Cleft%28%5Csum_%7Bn%3D1%7D%5ENa_n%5E2%5Cright%29%5E2-2%5Csum_%7Bn%3D1%7D%5ENa_n%5E4.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Letting N go to infinity, and using convergence in 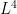 ,
,
![\displaystyle {\mathbb E}[\lvert a\cdot X\rvert^4]=3\lVert a\rVert_2^4-2\sum_{n=1}^\infty a_n^4\le3\lVert a\rVert_2^4.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5B%5Clvert+a%5Ccdot+X%5Crvert%5E4%5D%3D3%5ClVert+a%5CrVert_2%5E4-2%5Csum_%7Bn%3D1%7D%5E%5Cinfty+a_n%5E4%5Cle3%5ClVert+a%5CrVert_2%5E4.+&bg=ffffff&fg=000000&s=0&c=20201002)
So, as claimed. ⬜
Combining with lemma 4, this result shows that the and topologies coincide for Rademacher series. Similarly, lemma 3 shows that the Khintchine inequality is equivalent to stating that the topologies coincide for all . Hence, we obtain the following alternative statement of the Khintchine inequalities, which naturally incorporates the version.
Theorem 6 The space 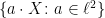 is contained in for all
is contained in for all  and, for all
and, for all  , the and topologies are equivalent on this space.
, the and topologies are equivalent on this space.
Although this statement unites the Khintchine inequalities for  with the corresponding version for
with the corresponding version for 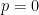 , when expressed as explicit quantitative statements as in (1) and (4), they do look rather different. For , the inequality is of the form
, when expressed as explicit quantitative statements as in (1) and (4), they do look rather different. For , the inequality is of the form
![\displaystyle g(\lVert a\rVert_2)\le{\mathbb E}[F(\lvert a\cdot X\rvert)]\le G(\lVert a\rVert_2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++g%28%5ClVert+a%5CrVert_2%29%5Cle%7B%5Cmathbb+E%7D%5BF%28%5Clvert+a%5Ccdot+X%5Crvert%29%5D%5Cle+G%28%5ClVert+a%5CrVert_2%29+&bg=ffffff&fg=000000&s=0&c=20201002)
for some increasing functions 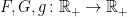 . The left-hand inequality for the case can also be expressed in a similar style.
. The left-hand inequality for the case can also be expressed in a similar style.
Lemma 7 For a random variable Z, inequality (3) holds if and only if
![\displaystyle {\mathbb E}[F(\lvert Z\rvert)]\ge\delta F(\epsilon\lVert Z\rVert_p)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5BF%28%5Clvert+Z%5Crvert%29%5D%5Cge%5Cdelta+F%28%5Cepsilon%5ClVert+Z%5CrVert_p%29+&bg=ffffff&fg=000000&s=0&c=20201002) |
(5) |
for all increasing functions 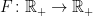 .
.
Proof: If (5) holds, then (3) follows immediately by taking  . Conversely, if (3) holds then,
. Conversely, if (3) holds then,
![\displaystyle \begin{aligned} E[F(\lvert Z\rvert)] &\ge{\mathbb E}\left[1_{\{Z\ge\epsilon\lVert Z\rVert_p\}}F(\epsilon\lVert Z\rVert_p)\right]\\ &={\mathbb P}(\lvert Z\rvert\ge\epsilon\lVert Z\rVert_p)F(\epsilon\lVert Z\rVert_p)\\ &\ge\delta F(\epsilon\lVert Z\rVert_p), \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+E%5BF%28%5Clvert+Z%5Crvert%29%5D+%26%5Cge%7B%5Cmathbb+E%7D%5Cleft%5B1_%7B%5C%7BZ%5Cge%5Cepsilon%5ClVert+Z%5CrVert_p%5C%7D%7DF%28%5Cepsilon%5ClVert+Z%5CrVert_p%29%5Cright%5D%5C%5C+%26%3D%7B%5Cmathbb+P%7D%28%5Clvert+Z%5Crvert%5Cge%5Cepsilon%5ClVert+Z%5CrVert_p%29F%28%5Cepsilon%5ClVert+Z%5CrVert_p%29%5C%5C+%26%5Cge%5Cdelta+F%28%5Cepsilon%5ClVert+Z%5CrVert_p%29%2C+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
as required. ⬜
The (left-hand) Khintchine inequality is then expressed by
![\displaystyle \delta F(\epsilon\lVert a\rVert_2)\le{\mathbb E}[F(\lvert a\cdot X\rvert)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cdelta+F%28%5Cepsilon%5ClVert+a%5CrVert_2%29%5Cle%7B%5Cmathbb+E%7D%5BF%28%5Clvert+a%5Ccdot+X%5Crvert%29%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
for some constants and every increasing function . This form also makes clear that the left-hand inequality for all follows from the version. We simply take  and
and  .
.
Although the Khintchine inequality is only concerning Rademacher sequences, it does have implications for much more general sequences. For example, the following consequence does not place any restriction on the distribution of the random variables , which are not even required to be independent. This was central to the construction of the stochastic integral given earlier in my notes, which only required the most basic properties of semimartingales.
Theorem 8 Let 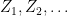 be a sequence of random variables in such that the set
be a sequence of random variables in such that the set
 |
(6) |
is bounded, for some . Then,  is in .
is in .
Proof: Set  . Then, if
. Then, if  is the uniform probability measure on
is the uniform probability measure on  , we can write
, we can write
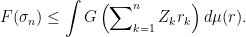
for some  which are increasing unbounded functions of
which are increasing unbounded functions of  . Specifically for , the left-hand Khintchine inequality says that this holds with
. Specifically for , the left-hand Khintchine inequality says that this holds with 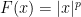 and
and  . For , lemma 7 says that we can choose
. For , lemma 7 says that we can choose  however we like, and
however we like, and 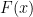 of the form
of the form 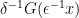 . We choose to be left-continuous and, by boundedness in probability, such that
. We choose to be left-continuous and, by boundedness in probability, such that ![{{\mathbb E}[G(Z)]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BG%28Z%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is bounded over
is bounded over 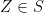 .
.
In either case, we can take expectations,
![\displaystyle {\mathbb E}[F(\sigma_n)]\le\int{\mathbb E}\left[G\left(\sum\nolimits_{k=1}^nZ_kr_k\right)\right]d\mu(r),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5BF%28%5Csigma_n%29%5D%5Cle%5Cint%7B%5Cmathbb+E%7D%5Cleft%5BG%5Cleft%28%5Csum%5Cnolimits_%7Bk%3D1%7D%5EnZ_kr_k%5Cright%29%5Cright%5Dd%5Cmu%28r%29%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
and the right hand side is bounded by some constant K independently of n. Hence, letting n go to infinity and applying Fatou’s lemma on the left gives
![\displaystyle {\mathbb E}\left[F\left(\left(\sum\nolimits_{k=1}^\infty Z_k^2\right)^{1/2}\right)\right] \le K < \infty](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Cleft%5BF%5Cleft%28%5Cleft%28%5Csum%5Cnolimits_%7Bk%3D1%7D%5E%5Cinfty+Z_k%5E2%5Cright%29%5E%7B1%2F2%7D%5Cright%29%5Cright%5D+%5Cle+K+%3C+%5Cinfty+&bg=ffffff&fg=000000&s=0&c=20201002)
as required. ⬜
The conclusion of theorem 8 directly implies that the sequence converges to zero in the topology. It was this consequence which was important in my construction of the stochastic integral.
Corollary 9 Let be a sequence of random variables such that the set (6) is bounded, for some . Then, 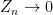 in .
in .
Proof: Since theorem 8 says that 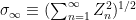 is in and, in particular, is almost surely finite, we see that almost surely. This implies that in and, for , as
is in and, in particular, is almost surely finite, we see that almost surely. This implies that in and, for , as  , dominated convergence gives in . ⬜
, dominated convergence gives in . ⬜
I only made use of the version of corollary 9 in the construction of the stochastic integral, as this is sufficient for the property of bounded convergence in probability. However, the corollary can also be used in its versions to obtain an theory of stochastic integration. For a semimartingale X, we require that

is bounded, for each positive time t. The resulting stochastic integral will then satisfy bounded convergence in . This approach dates back to the 1981 paper Stochastic Integration and Lp-Theory of Semimartingales by Bichteler, and is used in his book Stochastic Integration with Jumps.
Note that the statement of corollary 9 makes sense in any topological vector space. So, for any such space V, we can ask whether, for every sequence 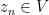 such that the set
such that the set

is bounded, does 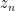 necessarily tend to zero? It is not difficult to show that this is true in Hilbert spaces and, more generally, in uniformly convex spaces. However, it does not hold in all spaces. Take, for example,
necessarily tend to zero? It is not difficult to show that this is true in Hilbert spaces and, more generally, in uniformly convex spaces. However, it does not hold in all spaces. Take, for example, 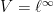 , which is the space of bounded real sequences
, which is the space of bounded real sequences  under uniform convergence. Then consider
under uniform convergence. Then consider  such that
such that  for
for  and
and  . The sums
. The sums  all have uniform norm equal to 1, so form a bounded set. However, does not tend to zero.
all have uniform norm equal to 1, so form a bounded set. However, does not tend to zero.
The spaces for  fail many of the usual `nice’ properties that are often required when working with topological vector spaces. For example,
fail many of the usual `nice’ properties that are often required when working with topological vector spaces. For example, 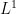 is generally not uniformly convex and, for
is generally not uniformly convex and, for 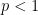 , is not even locally convex. So, corollary 9 gives a fundamental and nontrivial property that spaces do satisfy, and which is sufficient to ensure a well behaved theory of stochastic integration.
, is not even locally convex. So, corollary 9 gives a fundamental and nontrivial property that spaces do satisfy, and which is sufficient to ensure a well behaved theory of stochastic integration.
Optimal Khintchine Constants
In the discussion above, I paid no concern to the optimal values of the constants in the Khintchine inequality. All that we were concerned with is that finite and positive constants do exist. However, the inequality is clearly improved if 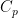 can be made as small as possible, and
can be made as small as possible, and 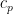 is as large as possible. In fact, the optimal values of these constants are known. I will not give full proofs here, but the actual values are enlightening, so I will mention them, and prove the `easy’ case of over
is as large as possible. In fact, the optimal values of these constants are known. I will not give full proofs here, but the actual values are enlightening, so I will mention them, and prove the `easy’ case of over 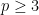 .
.
Use 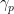 to denote the p‘th absolute Gaussian moment, which can be computed explicitly in terms of the gamma function. Letting N be a standard normal random variable, on some probability space,
to denote the p‘th absolute Gaussian moment, which can be computed explicitly in terms of the gamma function. Letting N be a standard normal random variable, on some probability space,
![\displaystyle \begin{aligned} \gamma_p &\equiv{\mathbb E}[\lvert N\rvert^p]\\ &=2^{\frac p2}\pi^{-\frac12}\Gamma\left(\frac{p+1}2\right). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%5Cgamma_p+%26%5Cequiv%7B%5Cmathbb+E%7D%5B%5Clvert+N%5Crvert%5Ep%5D%5C%5C+%26%3D2%5E%7B%5Cfrac+p2%7D%5Cpi%5E%7B-%5Cfrac12%7D%5CGamma%5Cleft%28%5Cfrac%7Bp%2B1%7D2%5Cright%29.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
It is straightforward (using Jensen’s inequality) to show that is strictly increasing in p, and  . So,
. So,  for and
for and  for . It turns out that, over , moments of Khintchine series are bounded above by Gaussian moments.
for . It turns out that, over , moments of Khintchine series are bounded above by Gaussian moments.
Theorem 10 The optimal Khintchine constants are,
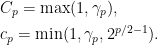 |
(7) |
The first thing to note is that, for any p, it is always possible to achieve the bounds given in (7) or, at least, approximate them as closely as we like. Specifically, consider with  in the following cases.
in the following cases.
- If
 then
then ![{{\mathbb E}[\lvert a\cdot X\rvert^p]=1}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5B%5Clvert+a%5Ccdot+X%5Crvert%5Ep%5D%3D1%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
- If
 then
then ![{{\mathbb E}[\lvert a\cdot X\rvert^p]=2^{p/2-1}}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5B%5Clvert+a%5Ccdot+X%5Crvert%5Ep%5D%3D2%5E%7Bp%2F2-1%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
- By lemma 6 of the post on Rademacher series, if we let
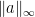 go to zero then
go to zero then ![{{\mathbb E}[\lvert a\cdot X\rvert^p]\rightarrow\gamma_p}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5B%5Clvert+a%5Ccdot+X%5Crvert%5Ep%5D%5Crightarrow%5Cgamma_p%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
This shows that, if it can be shown that the Khintchine inequality holds with the constants in (7), then it is optimal. We already noted above that the inequality holds with for  and for , so this is optimal. The remaining cases are,
and for , so this is optimal. The remaining cases are,

Incidentally, we already showed that  in the process of proving lemma 5. A similar method, simply expanding out the power of the series, can be applied for all even integer p.
in the process of proving lemma 5. A similar method, simply expanding out the power of the series, can be applied for all even integer p.
Lemma 11 For each even integer , the Khintchine inequality holds with 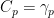 .
.
Proof: Writing , expanding the power of the sum gives
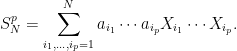 |
(8) |
For the product of the X‘s, by collecting together equal terms, we can write

where the 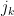 are distinct. By symmetry in switching the sign of
are distinct. By symmetry in switching the sign of  , if any of the powers
, if any of the powers 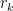 are odd, then this will have zero expectation. On the other hand, if all of the powers are even, then it is equal to 1.
are odd, then this will have zero expectation. On the other hand, if all of the powers are even, then it is equal to 1.
In order to simplify relating this sum to , we employ a devious trick. Let  be an IID sequence of standard normal random variables defined on some probability space. As above,
be an IID sequence of standard normal random variables defined on some probability space. As above,
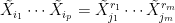
will have zero mean if any of the powers are odd and, if they are all even then,
![\displaystyle \begin{aligned} {\mathbb E}[\tilde X_{i_1}\cdots \tilde X_{i_p}] &={\mathbb E}[\tilde X_{j_1}^{r_1}]\cdots{\mathbb E}[\tilde X_{j_m}^{r_m}]\\ &=\gamma_{r_1}\cdots\gamma_{r_m}\ge1. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5B%5Ctilde+X_%7Bi_1%7D%5Ccdots+%5Ctilde+X_%7Bi_p%7D%5D+%26%3D%7B%5Cmathbb+E%7D%5B%5Ctilde+X_%7Bj_1%7D%5E%7Br_1%7D%5D%5Ccdots%7B%5Cmathbb+E%7D%5B%5Ctilde+X_%7Bj_m%7D%5E%7Br_m%7D%5D%5C%5C+%26%3D%5Cgamma_%7Br_1%7D%5Ccdots%5Cgamma_%7Br_m%7D%5Cge1.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
In any case, if we set 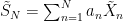 then taking expectations of (8) gives,
then taking expectations of (8) gives,
![\displaystyle \begin{aligned} {\mathbb E}[S_N^p] &=\sum_{i_1,\ldots,i_p=1}^Na_{i_1}\cdots a_{i_p}{\mathbb E}[X_{i_1}\cdots X_{i_p}]\\ &\le\sum_{i_1,\ldots,i_p=1}^Na_{i_1}\cdots a_{i_p}{\mathbb E}[\tilde X_{i_1}\cdots\tilde X_{i_p}]\\ &={\mathbb E}[\tilde S_N^p]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5BS_N%5Ep%5D+%26%3D%5Csum_%7Bi_1%2C%5Cldots%2Ci_p%3D1%7D%5ENa_%7Bi_1%7D%5Ccdots+a_%7Bi_p%7D%7B%5Cmathbb+E%7D%5BX_%7Bi_1%7D%5Ccdots+X_%7Bi_p%7D%5D%5C%5C+%26%5Cle%5Csum_%7Bi_1%2C%5Cldots%2Ci_p%3D1%7D%5ENa_%7Bi_1%7D%5Ccdots+a_%7Bi_p%7D%7B%5Cmathbb+E%7D%5B%5Ctilde+X_%7Bi_1%7D%5Ccdots%5Ctilde+X_%7Bi_p%7D%5D%5C%5C+%26%3D%7B%5Cmathbb+E%7D%5B%5Ctilde+S_N%5Ep%5D.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
As sums of independent normals are normal, 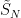 is normal with variance
is normal with variance  ,
,
![\displaystyle {\mathbb E}[S_N^p]\le{\mathbb E}[\tilde S_N^p]=\gamma_p\sigma_N^p\le\gamma_p\lVert a\rVert_2^p](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5BS_N%5Ep%5D%5Cle%7B%5Cmathbb+E%7D%5B%5Ctilde+S_N%5Ep%5D%3D%5Cgamma_p%5Csigma_N%5Ep%5Cle%5Cgamma_p%5ClVert+a%5CrVert_2%5Ep+&bg=ffffff&fg=000000&s=0&c=20201002)
Finally, letting N go to infinity and applying Fatou’s lemma on the left hand side gives the result. ⬜
I extend this result to all real . As we can no longer simply expand out the power of the sum, a convexity argument employing Jensen’s inequality will be used.
Lemma 12 For each , the function

is convex on the nonnegative reals.
Proof: Differentiating  twice, and using
twice, and using 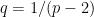 and
and  , gives
, gives
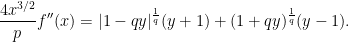
Note that both terms on the right are positive so long as 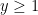 . On the other hand, for
. On the other hand, for 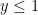 , compute the derivative
, compute the derivative
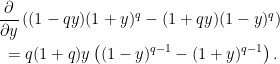
As  , this is nonnegative, so
, this is nonnegative, so
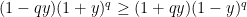
and substituting into the expression for 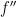 gives
gives  as required. ⬜
as required. ⬜
Unfortunately, for  , the function in lemma 12 is not convex, and a different approach is required. I concentrate on . We will use a similar trick as in lemma 11 whereby we replace the Rademacher random variables by normals. To simplify the argument a bit, rather than replacing them all in one go, here we will replace them one at a time.
, the function in lemma 12 is not convex, and a different approach is required. I concentrate on . We will use a similar trick as in lemma 11 whereby we replace the Rademacher random variables by normals. To simplify the argument a bit, rather than replacing them all in one go, here we will replace them one at a time.
Lemma 13 For each real , the Khintchine inequality holds with .
Proof: Applying lemma 12, and scaling, the function

is convex for any real  . Hence, if X is a Rademacher random variable and Y is standard normal, then
. Hence, if X is a Rademacher random variable and Y is standard normal, then ![{{\mathbb E}[Y^2]=1}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BY%5E2%5D%3D1%7D&bg=ffffff&fg=000000&s=0&c=20201002) and Jensen’s inequality gives
and Jensen’s inequality gives
![\displaystyle {\mathbb E}[\lvert a+bX\rvert^p]=f(1) \le{\mathbb E}[f(Y^2)] ={\mathbb E}[\lvert a+bY\rvert^p].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5B%5Clvert+a%2BbX%5Crvert%5Ep%5D%3Df%281%29+%5Cle%7B%5Cmathbb+E%7D%5Bf%28Y%5E2%29%5D+%3D%7B%5Cmathbb+E%7D%5B%5Clvert+a%2BbY%5Crvert%5Ep%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
Next, if S is any random variable and X, Y are as above, independently of S, then
![\displaystyle \begin{aligned} {\mathbb E}[\lvert S+bX\rvert^p] &={\mathbb E}[{\mathbb E}[\lvert S+bX\rvert^p\mid S]]\\ &\le{\mathbb E}[{\mathbb E}[\lvert S+bY\rvert^p\mid S]]\\ &={\mathbb E}[\lvert S+bY\rvert^p]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5B%5Clvert+S%2BbX%5Crvert%5Ep%5D+%26%3D%7B%5Cmathbb+E%7D%5B%7B%5Cmathbb+E%7D%5B%5Clvert+S%2BbX%5Crvert%5Ep%5Cmid+S%5D%5D%5C%5C+%26%5Cle%7B%5Cmathbb+E%7D%5B%7B%5Cmathbb+E%7D%5B%5Clvert+S%2BbY%5Crvert%5Ep%5Cmid+S%5D%5D%5C%5C+%26%3D%7B%5Cmathbb+E%7D%5B%5Clvert+S%2BbY%5Crvert%5Ep%5D.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
(9) |
We now consider the finite sum . Replacing the Rademacher random variables one-by-one by IID standard normals  , we obtain the sums
, we obtain the sums
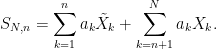
If we also consider the same sum with the n‘the term excluded,
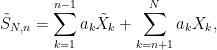
then, assuming that the series 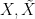 are chosen independent of each other,
are chosen independent of each other,  will be independent of both
will be independent of both 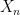 and . So, applying (9),
and . So, applying (9),
![\displaystyle \begin{aligned} {\mathbb E}[\lvert S_{N,n}\rvert^p] &={\mathbb E}[\lvert\tilde S_{N,n}+a_n\tilde X_n\rvert^p]\\ &\ge{\mathbb E}[\lvert\tilde S_{N,n}+a_nX_n\rvert^p]\\ &={\mathbb E}[\lvert S_{N,n-1}\rvert^p]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5B%5Clvert+S_%7BN%2Cn%7D%5Crvert%5Ep%5D+%26%3D%7B%5Cmathbb+E%7D%5B%5Clvert%5Ctilde+S_%7BN%2Cn%7D%2Ba_n%5Ctilde+X_n%5Crvert%5Ep%5D%5C%5C+%26%5Cge%7B%5Cmathbb+E%7D%5B%5Clvert%5Ctilde+S_%7BN%2Cn%7D%2Ba_nX_n%5Crvert%5Ep%5D%5C%5C+%26%3D%7B%5Cmathbb+E%7D%5B%5Clvert+S_%7BN%2Cn-1%7D%5Crvert%5Ep%5D.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
As sums of independent normals are normal,  is normal with variance . Also,
is normal with variance . Also, 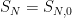 , so we obtain
, so we obtain
![\displaystyle {\mathbb E}[\lvert S_N\rvert^p]\le{\mathbb E}[\lvert S_{N,N}\rvert^p] =\gamma_p\sigma_N^p\le\gamma_p\lVert a\rVert_2^p.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5B%5Clvert+S_N%5Crvert%5Ep%5D%5Cle%7B%5Cmathbb+E%7D%5B%5Clvert+S_%7BN%2CN%7D%5Crvert%5Ep%5D+%3D%5Cgamma_p%5Csigma_N%5Ep%5Cle%5Cgamma_p%5ClVert+a%5CrVert_2%5Ep.+&bg=ffffff&fg=000000&s=0&c=20201002)
Letting N increase to infinity and applying Fatou’s lemma on the left hand side gives the result. ⬜
The optimal left-hand inequality for and right-hand inequality for require some further techniques, as the function in lemma 12 is neither convex nor concave. I refer to the paper Ball, Haagerup, and Distribution Functions for these cases, and also to The optimal constants in Khintchine’s inequality for the case 2 < p < 3.
Finally, using the fact that and 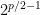 are both less than one on the range , I note that the optimal left-hand inequality is given by theorem 10 as,
are both less than one on the range , I note that the optimal left-hand inequality is given by theorem 10 as,

However, it is not immediately obvious which of the two terms in the minimum is smaller. Writing
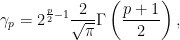
we see that we should take 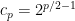 whenever
whenever

By log-convexity, there will be a unique  solving
solving  and, hence, the expression for can be written more clearly as
and, hence, the expression for can be written more clearly as

Solving numerically gives  .
.


Hi George! You claim that Corollary 9 can be generalized to Hilbert spaces (or more generally, uniformly convex spaces). Do you have a reference of this result? Also, I was wondering if you know about an analogous result for the Bochner space $L^0_H$ of equivalence classes of Hilbert space valued random elements?
Thanks for yet another interesting blog entry!
No reference, this is something I came up with while writing the post. Actually, I did consider if the result holds for all reflexive Banach spaces. Maybe it does, but I am not sure, and did not want to spend too long on what was a side-comment and not the focus of the post. For a Hilbert space it is easy. If the norm of elements of the set is bounded by K, then
is bounded by K, then
and it follows that . Uniformly convex spaces are a little trickier. Consider
. Uniformly convex spaces are a little trickier. Consider  , where
, where  are chosen inductively to maximize
are chosen inductively to maximize 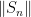 (given the values of
(given the values of  for k less than n). It can be seen that
for k less than n). It can be seen that 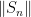 is non-decreasing and, as it is bounded by assumption, tends to a limit K (we have not used uniform convexity yet…). The uniform convex property can be used to show that for each fixed positive
is non-decreasing and, as it is bounded by assumption, tends to a limit K (we have not used uniform convexity yet…). The uniform convex property can be used to show that for each fixed positive  , there exists a
, there exists a  such that
such that
whenever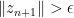 , which is a contradiction unless
, which is a contradiction unless  for all large n, showing that it converges to zero.
for all large n, showing that it converges to zero.
It extends to Bochner spaces (defined wrt a Hilbert space H), you can generalise the Khintchine inequality to a_n lying in an arbitrary Hilbert space, so the result should still hold.
Indeed you are right! Thanks for this nice proof and your insight into these special cases!
In your second equation line, where you bound the sum by $K^2$, should not the first equality be replaced by an inequality? Since you take the sum over all permutations of +-1, you will get some extra terms. Of course, this will change nothing and your elegant argument still holds.
No, it should be an equality, basically it is the parallelogram law extended to arbitrarily many terms, and is an identity in any Hilbert space.
Thanks for another nice post!
Two minor typos: should be 2?
should be 2?
(1) Proof of lemma 4: inequality should be reversed before “contradicting (3)”.
(2) Proof of lemma 5: the last inequality should be reversed… and it seems the coefficient before
[George: Fixed, thanks!]
I’m sorry, but I don’t think the proof to the right hand side of Theorem 1 is right. The term $\Vert a \Vert_2$ is over an exponential term, how does dividing $\lambda^p$ implies the inequality?
I mean, lambda is an arbitrary positive number, so can be replaced by lambda / ||a||_2, in which case you get the required inequality.
Thank you for this post! I just used your Lemma 2 and the proof therein to upper bound unknown moments of a non-negative random variable via an interpolation of the moments that I know. This saved a proof within the last hours before submitting an article 🙂