In stochastic calculus it is common to work with processes adapted to a filtered probability space 
Extending a probability space is a relatively straightforward concept, which I covered in an earlier post. Extending a filtered probability space is the same, except that it also involves enlarging the filtration 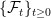
Let’s consider a filtered probability space 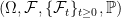
 |
is, firstly, an extension of the probability spaces. It is a map from Ω′ to Ω measurable with respect to 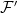

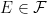
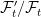

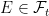
As with extensions of probability spaces, this can be considered in two steps. First, we extend to the filtered probability space on Ω′ with induced sigma-algebra 
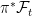

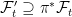
Such arbitrary extensions are too general for many uses in stochastic calculus where we merely want to add in some additional source of randomness. Consider, for example, a standard Brownian motion B defined on the original space so that, for any times s < t, Bt – Bs is normal and independent of 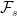
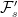
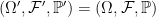
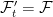

The idea is that, if ![{ Y={\mathbb E}[X\vert\mathcal F_t]}](https://s0.wp.com/latex.php?latex=%7B+Y%3D%7B%5Cmathbb+E%7D%5BX%5Cvert%5Cmathcal+F_t%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{ Y^*={\mathbb E}[X^*\vert\mathcal F'_t]}](https://s0.wp.com/latex.php?latex=%7B+Y%5E%2A%3D%7B%5Cmathbb+E%7D%5BX%5E%2A%5Cvert%5Cmathcal+F%27_t%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
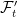
Recall that two sigma-algebras 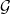
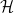
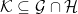
![\displaystyle {\mathbb P}(A\cap B) = {\mathbb E}\left[{\mathbb P}(A\vert\mathcal K){\mathbb P}(B\vert\mathcal K)\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7B%5Cmathbb+P%7D%28A%5Ccap+B%29+%3D+%7B%5Cmathbb+E%7D%5Cleft%5B%7B%5Cmathbb+P%7D%28A%5Cvert%5Cmathcal+K%29%7B%5Cmathbb+P%7D%28B%5Cvert%5Cmathcal+K%29%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002) |
for all 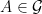
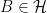
for all bounded
for all bounded
for all bounded
This leads us to the idea of a standard extension of filtered probability spaces.
Definition 1 An extension of filtered probability spaces
is standard if, for each time t ≥ 0, the sigma-algebras
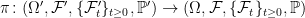
The definition above can be stated as saying that the extension is standard if, given
An obvious way to try to extend a filtered probability space 
 |
(1) |
with 

Lemma 2 The extension π to the product filtered probability space
defined above is standard.
Proof: Let ρ: Ω′ → Λ be the projection ρ(ω, λ) = λ. By definition of the product measure, 
Consider ![{ Y^*={\mathbb E}[X^*\vert\pi^*\mathcal F_t]}](https://s0.wp.com/latex.php?latex=%7B+Y%5E%2A%3D%7B%5Cmathbb+E%7D%5BX%5E%2A%5Cvert%5Cpi%5E%2A%5Cmathcal+F_t%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle {\mathbb E}[Y^*UV]={\mathbb E}[Y^*U]{\mathbb E}[V]={\mathbb E}[X^*U]{\mathbb E}[V]={\mathbb E}[X^*UV].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7B%5Cmathbb+E%7D%5BY%5E%2AUV%5D%3D%7B%5Cmathbb+E%7D%5BY%5E%2AU%5D%7B%5Cmathbb+E%7D%5BV%5D%3D%7B%5Cmathbb+E%7D%5BX%5E%2AU%5D%7B%5Cmathbb+E%7D%5BV%5D%3D%7B%5Cmathbb+E%7D%5BX%5E%2AUV%5D.+&bg=ffffff&fg=000000&s=0&c=20201002) |
The first and last inequalities are using independence of 
![{ Y^*={\mathbb E}[X^*\vert\mathcal F_t\otimes\mathcal G_t]}](https://s0.wp.com/latex.php?latex=%7B+Y%5E%2A%3D%7B%5Cmathbb+E%7D%5BX%5E%2A%5Cvert%5Cmathcal+F_t%5Cotimes%5Cmathcal+G_t%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Preserved Properties
Consider, again, our Brownian motion B lifted to B∗ under a standard extension. For times s < t, Bt – Bs is independent of
Lemma 3 Suppose that X is a Markov process with transition function {Pt}t≥0, and π is a standard extension of the underlying probability space. Then, X∗ is a Markov process with the same transition function
Proof: Let X be a Markov process with transition function P· on measurable space E. For times s < t this means that ![{{\mathbb E}[f(X_t)\vert \mathcal F_s]=P_{t-s}f(X_s)}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5Bf%28X_t%29%5Cvert+%5Cmathcal+F_s%5D%3DP_%7Bt-s%7Df%28X_s%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{{\mathbb E}[f(X^*_t)\vert \mathcal F'_s]=P_{t-s}f(X^*_s)}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5Bf%28X%5E%2A_t%29%5Cvert+%5Cmathcal+F%27_s%5D%3DP_%7Bt-s%7Df%28X%5E%2A_s%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Look again at the situation where we take the product with an auxiliary space 
In situations where the filtration is generated by the Markov process, lemma 3 generalizes to an ‘if and only if’ condition.
Lemma 4 Suppose that X is a Markov process on the underlying filtered probability space, and that
. Then, extension π of the filtered probability space is standard if and only if X∗ is Markov.
Proof: Saying that the filtration is generated by X and
If the extension is standard, then X∗ is standard by lemma 3, so only the reverse implication needs to be shown. Suppose that X∗ Markov, and fix a time t ≥ 0. For bounded random variable Y measurable with respect to {Xs}s≥t, the Markov property says that ![{{\mathbb E}[Y\vert\mathcal F_t]={\mathbb E}[Y\vert X_t]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BY%5Cvert%5Cmathcal+F_t%5D%3D%7B%5Cmathbb+E%7D%5BY%5Cvert+X_t%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{{\mathbb E}[Y^*\vert\mathcal F'_t]={\mathbb E}[Y^*\vert X^*_t]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5BY%5E%2A%5Cvert%5Cmathcal+F%27_t%5D%3D%7B%5Cmathbb+E%7D%5BY%5E%2A%5Cvert+X%5E%2A_t%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
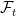
![\displaystyle \begin{aligned} {\mathbb E}[U^*\;\vert\pi^*\mathcal F_t] &=\pi^*{\mathbb E}[U\;\vert\mathcal F_t]\\ &=\pi^*(Z{\mathbb E}[Y\;\vert X_t])\\ &=Z^*{\mathbb E}[Y^*\vert X^*_t]\\ &=Z^*{\mathbb E}[Y^*\vert\mathcal F'_t]\\ &={\mathbb E}[U^*\vert\mathcal F'_t]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%7B%5Cmathbb+E%7D%5BU%5E%2A%5C%3B%5Cvert%5Cpi%5E%2A%5Cmathcal+F_t%5D+%26%3D%5Cpi%5E%2A%7B%5Cmathbb+E%7D%5BU%5C%3B%5Cvert%5Cmathcal+F_t%5D%5C%5C+%26%3D%5Cpi%5E%2A%28Z%7B%5Cmathbb+E%7D%5BY%5C%3B%5Cvert+X_t%5D%29%5C%5C+%26%3DZ%5E%2A%7B%5Cmathbb+E%7D%5BY%5E%2A%5Cvert+X%5E%2A_t%5D%5C%5C+%26%3DZ%5E%2A%7B%5Cmathbb+E%7D%5BY%5E%2A%5Cvert%5Cmathcal+F%27_t%5D%5C%5C+%26%3D%7B%5Cmathbb+E%7D%5BU%5E%2A%5Cvert%5Cmathcal+F%27_t%5D.+%5Cend%7Baligned%7D+&bg=ffffff&fg=000000&s=0&c=20201002) |
As the condition of the lemma says that
Lemma 4 implies that any space containing a Markov process can be considered as a standard extension of the process defined on its own canonical space. That is, we start with a Markov process X∗ taking values in a measurable space E and defined on 
Standard extensions also preserve other important properties of processes.
Lemma 5 A standard extension of a filtered probability space preserves the (local) martingale, submartingale and supermartingale properties.
Proof: It is sufficient to consider the case where X is a (local) submartingale, since applying this to –X covers the supermartingale case and applying to both X and –X gives the result for martingales. So, suppose that X is a submartingale and s < t are fixed times. By conditional independence,
![\displaystyle {\mathbb E}\left[X^*_t\vert\mathcal F'_s\right]={\mathbb E}\left[X_t\vert\mathcal F_s\right]^*\ge X_s^*,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7B%5Cmathbb+E%7D%5Cleft%5BX%5E%2A_t%5Cvert%5Cmathcal+F%27_s%5Cright%5D%3D%7B%5Cmathbb+E%7D%5Cleft%5BX_t%5Cvert%5Cmathcal+F_s%5Cright%5D%5E%2A%5Cge+X_s%5E%2A%2C+&bg=ffffff&fg=000000&s=0&c=20201002) |
so that X∗ is a submartingale. Now, suppose that X is a local submartingale, so there exist stopping times τn increasing to infinity such that 1{τn>0}Xτn are submartingales. From what we have already proven,
 |
are submartingales and, as τ∗n are 
An important class of processes is that of semimartingales. These are good integrators in the sense of stochastic integration, so if we are using stochastic integrals then it will be important to know that these remain semimartingales in an extension of the underlying space, with integrals which are preserved by the extension. That is,
 |
(2) |
If we already know that X∗ is a semimartingale then this is indeed true.
Before proceeding, I make a brief comment regarding stochastic integrals in general. In these notes, the underlying filtration was assumed to be complete in order to choose cadlag versions. I do not do that here, since extending filtrations by taking a product (1) could break this assumption. You can add the step of completing each filtration if you like, although I will just assume that stochastic integration and semimartingale decompositions are performed with respect to the completion.
Lemma 6 Let π be an extension of the underlying filtered probability space and X be an adapted process such that X∗ is a semimartingale. Then, X is a semimartingale and if ξ is a predictable process such that ξ∗ is X∗-integrable, then ξ is X-integrable and (2) holds.
Proof: For any elementary predictable process ξ, it is immediate from the definition that ξ∗ is elementary and the elementary integrals (2) agree. As extensions preserve probability, they also preserve convergence in probability and, by bounded convergence in probability, it follows that ∫0tξ∗ dX∗ is
 |
guaranteeing that (2) holds. As this satisfies bounded convergence in probability and agrees with the definition for elementary integrands, it follows that X is a semimartingale satisfying (2) for bounded integrands.
Now, suppose that ξ is a predictable process such that ξ∗ is X∗ integrable, we need to show that ξ is X-integrable. So, let |ζn| ≤ |ξ| be a sequence of bounded predictable processes tending to zero. Applying (2) for bounded integrands,
 |
by dominated convergence in probability as n goes to infinity. Hence, ∫t0ζn dX tends to zero in probability, showing that ξ is X-integrable. Finally, in a similar way, suppose that |ζn| ≤ |ξ| be a sequence of bounded predictable processes tending to ξ. By bounded convergence in probability,
 |
as required. ⬜
In general, however, knowing that X is a semimartingale is not sufficient to guarantee that X∗ is, so that lemma 6 cannot be applied. For example, X could be a standard Brownian motion, and if we enlarge the filtration so that
These deficiencies in preserving stochastic integration and the semimartingale property are all fixed in standard extensions.
Lemma 7 Let π be a standard extension of the underlying filtered probability space. Then, a semimartingale X remains a semimartingale in the extension.
Furthermore, a predictable process ξ in the original space is X-integrable if and only if ξ∗ is X∗-integrable, in which case the stochastic integrals (2) agree.
Proof: Proving that X∗ is a semimartingale is actually rather tricky if we try to directly show that it satisfies the original definition used in these notes. That is, the stochastic integral exists for bounded integrands satisfying bounded convergence in probability. The problem is, when we pass to the extension, there can be many more predictable processes, and constructing their integral in terms of integration in the original space can be tricky. However, the alternative definition of semimartingales as the sum of a local martingale and an FV process, as stated by the Bichteler-Dellacherie theorem, tells us that X∗ is a semimartingale as an immediate consequence of lemma 5.
I will make use of the alternative condition that ξ is X-integrable if there is a semimartingale Y satisfying
 |
We know that Y∗ is a semimartingale from what we have already shown. As the integrands are bounded, lemma 6 says that (2) can be used,
 |
So, ξ∗ is X∗-integrable as required. ⬜
Let’s now look back at the example of extending a filtered probability space by taking its product with another such space. We saw in lemma 2 that this is a standard extension so, by lemma 7, it preserves the values of stochastic integrals. However, it is possible to go much further and describe the value of stochastic integrals in the extended space in terms of integrals in the original space. To recap, we take the product (1) of the base space Ω with an auxiliary space Λ to obtain the product Ω′= Ω × Λ with product filtration also described by (1). The extension map π is just projection π(ω, λ) = ω onto the first component of Ω × Λ.
For any λ ∈ Λ we can project a stochastic process ξ defined on the extended space Ω′ to a process ξλ on the base space,
 |
This is a left-inverse of lifting, so that lifting a process ξ from the base space and projecting it back down gives the original process, (π∗ξ)λ = ξ. By lemma 7, any semimartingale X on the base space lifts to a semimartingale X∗.
Lemma 8 Let X be a semimartingale on Ω and ξ be a real-valued predictable process on Ω′= Ω × Λ. Then, ξλ is predictable and ξ is X∗-integrable if and only if ξλ is X-integrable for ℚ-almost all λ ∈ Λ. In that case,
(3) for ℙ′-almost all (ω, λ).

Just a word on the notation in (3). As stochastic integrals are just random variables, they are really functions on the underlying probability space and can expressed by their values corresponding to each ω ∈ Ω or (ω, λ) ∈ Ω′. While we usually do not explicitly include these sample points in expressions involving random variables, it does simplify things in this case, so they are included.
Proof: For any elementary predictable process ξ, it is immediate from the definition that ξλ is elementary and the elementary integrals (3) agree. By the monotone class theorem, ξλ is predictable whenever ξ is predictable and, by bounded convergence in probability, (3) extends to all bounded predictable ξ.
Now, suppose that ξλ is X-integrable for almost all λ. We need to show that ξ is X∗-integrable. So, consider any sequence of bounded predictable processes |αn| ≤ |ξ| tending to zero. Hence, by (3)
 |
For any λ such that ξλ is X-integrable, the right hand side of this identity tends to zero in probability, by dominated convergence. Since this holds for almost all λ, it tends to zero in probability jointly w.r.t. (ω, λ), showing that ξ is X∗-integrable. If instead we choose αn → ξ then, again by dominated convergence in probability, the equality tends to (3).
It remains to show that, if ξ is X∗-integrable then ξλ is X-integrable for almost all λ, which is the trickiest part of this proof. Continuous semimartingales are easiest, since they decompose uniquely as
 |
(4) |
for local martingale M and continuous FV process A starting from 0. As noted following equation (2) above, such decompositions are understood to be adapted to the completion of the filtration. By lemma 5, this decomposition is preserved by standard extensions, X∗ = M∗ + A∗ for local martingale M∗ and continuous FV process A∗. That ξ is X∗-integrable is equivalent to
![\displaystyle \int_0^t\xi^2\,d[M^*]+\int_0^t\lvert\xi\rvert\,\lvert dA^*\rvert < \infty](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cint_0%5Et%5Cxi%5E2%5C%2Cd%5BM%5E%2A%5D%2B%5Cint_0%5Et%5Clvert%5Cxi%5Crvert%5C%2C%5Clvert+dA%5E%2A%5Crvert+%3C+%5Cinfty+&bg=ffffff&fg=000000&s=0&c=20201002) |
(5) |
almost surely for each time t. As quadratic variations are defined by taking limits in probability of finite sums and extensions preserve probability, they also preserve quadratic variations, [M∗] = [M]∗. So, evaluating (5) on sample paths gives
![\displaystyle \int_0^t(\xi^\lambda)^2\,d[M]+\int_0^t\lvert\xi^\lambda\rvert\,\lvert dA\rvert < \infty](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cint_0%5Et%28%5Cxi%5E%5Clambda%29%5E2%5C%2Cd%5BM%5D%2B%5Cint_0%5Et%5Clvert%5Cxi%5E%5Clambda%5Crvert%5C%2C%5Clvert+dA%5Crvert+%3C+%5Cinfty+&bg=ffffff&fg=000000&s=0&c=20201002) |
almost surely, for ℚ-almost all λ and, hence, ξλ is X-integrable.
Only the noncontinuous case remains, which we will handle in a similar way after extracting out any problematic jumps. First, consider subtracting out large jumps by looking at X – Y where Yt = Σs≤t1{|ΔXs|>1}ΔXs. As Y just consists of finitely many jumps over finite horizons, ξλ is automatically Y-integrable and ξ is Y∗-integrable. So, it is enough to prove the result with X replaced by X – Y, which has jumps bounded by 1.
Without loss of generality, we assume that X has jumps bounded by 1. In particular, this means that it is locally integrable, so decomposition (4) holds where, now, A is a predictable FV process rather than being necessarily continuous. Furthermore, if ξΔX∗ was locally integrable, then ξ is X∗-integrable if and only if (5) holds almost surely. Then, we could argue as in the continuous case. As we include non locally integrable situations, then we subtract out the large values of ξΔX∗. To do this, set
 |
This is a process defined on Ω′ with finitely many jumps over finite horizons, all of which are bounded by 1. So, it has locally integrable variation and decomposition (4) can be applied,
 |
for local martingale N and predictable FV process B. The idea is that restricting to the base space preserves the decomposition. That is, Yλ = Nλ + Bλ, where Nλ is a local martingale and Bλ is predictable FV for almost all λ. The fact that Nλ is a local martingale is not immediately obvious, so I prove this in a moment, but first show why it gives the result.
As ξ is Y-integrable, it is also (X∗ - Y)-integrable, and this integral has jumps bounded by 1 and hence is locally integrable. So, (5) applies
![\displaystyle \int_0^t\xi^2\,d[M^*-N]+\int_0^t\lvert\xi\rvert\,\lvert d(A^*-B)\rvert < \infty](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cint_0%5Et%5Cxi%5E2%5C%2Cd%5BM%5E%2A-N%5D%2B%5Cint_0%5Et%5Clvert%5Cxi%5Crvert%5C%2C%5Clvert+d%28A%5E%2A-B%29%5Crvert+%3C+%5Cinfty+&bg=ffffff&fg=000000&s=0&c=20201002) |
(almost surely). Equivalently, evaluating along sample paths,
![\displaystyle \int_0^t(\xi^\lambda)^2\,d[M-N^\lambda]+\int_0^t\lvert\xi^\lambda\rvert\,\lvert d(A-B^\lambda)\rvert < \infty](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cint_0%5Et%28%5Cxi%5E%5Clambda%29%5E2%5C%2Cd%5BM-N%5E%5Clambda%5D%2B%5Cint_0%5Et%5Clvert%5Cxi%5E%5Clambda%5Crvert%5C%2C%5Clvert+d%28A-B%5E%5Clambda%29%5Crvert+%3C+%5Cinfty+&bg=ffffff&fg=000000&s=0&c=20201002) |
almost surely for almost all λ. From the fact that ξλΔ(X - Yλ) is bounded by 1 and so locally integrable, combined with the decomposition
 |
into local martingale and predictable FV terms, this means that ξλ is (X - Yλ)-integrable and, hence, is X-integrable for almost all λ.
It just remains to provide the promised proof of the statement above that Nλ is a local martingale for almost all λ. Start by choosing measurable Uk, Vk ⊆ ℝ (k = 1, 2, …) such that Uk × Vk partition the set {(x, y) ∈ ℝ2: |xy| > 1} and define the processes,
 |
These have finitely many jumps bounded by 1 over each finite horizon, so decompose as Zk = Pk + Ck for local martingales Pk and predictable FV processes Ck. Lifting up to the product space and integrating gives,
 |
Here, P̃k and C̃k are used to represent the integrals in the right hand side and, being an integral with respect to a local martingale, P̃k is a local martingale. For any stopping time τ such that Y has integrable variation on the interval [0, τ], then C̃k has expected variation bounded by that of the left hand side in the expression above. Summing over k this is absolutely convergent in L1 over each such interval,
 |
So, by uniqueness of the decomposition into local martingale and predictable FV terms, N = ΣkP̃k. Hence, we obtain
 |
almost surely. Each summand on the right hand side is an integral with respect to a local martingale, so is a local martingale and, as the sum is locally convergent in L1, this implies that Nλ is almost surely a local martingale. ⬜
Combining Extensions
Since we sometimes want to extend a filtered probability space more than a single time, I look at how these combine. Consider an extension π of the original filtered probability space, and then a further extension ρ of this.
 |
These can be combined into a single extension ϕ = π○ρ of the original space,
 |
Lemma 9 If π and ρ are standard extensions, then so is ϕ = π○ρ.
Proof: For time t ≥ 0 and bounded ![{\pi^*Y={\mathbb E}[\pi^*X\vert\mathcal F'_t]}](https://s0.wp.com/latex.php?latex=%7B%5Cpi%5E%2AY%3D%7B%5Cmathbb+E%7D%5B%5Cpi%5E%2AX%5Cvert%5Cmathcal+F%27_t%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \phi^*Y=\rho^*\pi^*Y=\rho^*{\mathbb E}[\pi^*X\vert\mathcal F'_t]={\mathbb E}[\rho^*\pi^*X\vert\mathcal F''_t]={\mathbb E}[\phi^*X\vert\mathcal F''_t]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cphi%5E%2AY%3D%5Crho%5E%2A%5Cpi%5E%2AY%3D%5Crho%5E%2A%7B%5Cmathbb+E%7D%5B%5Cpi%5E%2AX%5Cvert%5Cmathcal+F%27_t%5D%3D%7B%5Cmathbb+E%7D%5B%5Crho%5E%2A%5Cpi%5E%2AX%5Cvert%5Cmathcal+F%27%27_t%5D%3D%7B%5Cmathbb+E%7D%5B%5Cphi%5E%2AX%5Cvert%5Cmathcal+F%27%27_t%5D+&bg=ffffff&fg=000000&s=0&c=20201002) |
so ϕ is a standard extension. ⬜
Next, consider two separate extensions of the same underlying space. Both of these will add in some additional source of randomness, and we would like to combine them into a single extension.
 |
As extensions of probability spaces, these can be combined into a single extension known as the relative product ϕ = π1○ρ1 = π2○ρ2,
 |
The sample space Ω′= Ω1 ⊗Ω Ω2 is the fiber product consisting of pairs (ω1, ω2) in Ω1 × Ω2 with π1(ω1) = π(ω2), and ρ1, ρ2 are the projection maps taking (ω1, ω2) to, respectively, ω1 and ω2. The sigma-algebra 


The relative product generalizes to filtered probability spaces. All that needs to be done is to define the filtration 


 |
with ϕ = π1○ρ1 = π2○ρ2 containing π1 and π2 as sub-extensions.
Definition 10 The filtered probability space extension
constructed above is the relative product of π1 and π2.

If we have two standard extensions of the same underlying filtered probability space then their relative product combines them into a single standard extension containing both of the original ones as sub-extensions.
Lemma 11 Let π1 and π2 be extensions of a filtered probability space with relative product ϕ = π1○ρ1 = π2○ρ2.
If π1 is standard then so is ρ2 and, similarly, if π2 is standard then so is ρ1.
In particular, if π1 and π2 are both standard, then so are ρ1, ρ2 and ϕ.
Proof: For brevity, I will use 



![\displaystyle {\mathbb E}[U\vert\mathcal F^{2*}]={\mathbb E}[U\vert\mathcal F^*]={\mathbb E}[U\vert\mathcal F_t^*].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7B%5Cmathbb+E%7D%5BU%5Cvert%5Cmathcal+F%5E%7B2%2A%7D%5D%3D%7B%5Cmathbb+E%7D%5BU%5Cvert%5Cmathcal+F%5E%2A%5D%3D%7B%5Cmathbb+E%7D%5BU%5Cvert%5Cmathcal+F_t%5E%2A%5D.+&bg=ffffff&fg=000000&s=0&c=20201002) |
The first equality uses the fact that 

![\displaystyle {\mathbb E}[U\vert\mathcal F^{2*}]={\mathbb E}[U\vert\mathcal F_t^{2*}].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7B%5Cmathbb+E%7D%5BU%5Cvert%5Cmathcal+F%5E%7B2%2A%7D%5D%3D%7B%5Cmathbb+E%7D%5BU%5Cvert%5Cmathcal+F_t%5E%7B2%2A%7D%5D.+&bg=ffffff&fg=000000&s=0&c=20201002) |
So, if X = UV for V bounded and 
![\displaystyle {\mathbb E}[X\vert\mathcal F^{2*}] ={\mathbb E}[U\vert\mathcal F^{2*}]V ={\mathbb E}[U\vert\mathcal F_t^{2*}]V ={\mathbb E}[X\vert\mathcal F_t^{2*}].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7B%5Cmathbb+E%7D%5BX%5Cvert%5Cmathcal+F%5E%7B2%2A%7D%5D+%3D%7B%5Cmathbb+E%7D%5BU%5Cvert%5Cmathcal+F%5E%7B2%2A%7D%5DV+%3D%7B%5Cmathbb+E%7D%5BU%5Cvert%5Cmathcal+F_t%5E%7B2%2A%7D%5DV+%3D%7B%5Cmathbb+E%7D%5BX%5Cvert%5Cmathcal+F_t%5E%7B2%2A%7D%5D.+&bg=ffffff&fg=000000&s=0&c=20201002) |
The monotone class theorem extends this to all bounded
If π2 is standard then, in exactly the same way, this implies that ρ1 is standard. If both π1 and π2 are standard, lemma 9 shows that ϕ = π1○ρ1 is standard. ⬜
Notes
Extending filtered probability spaces is a basic underlying concept although, in much of the theory, we do not need to invoke it explicitly. Some constructions or results may require the existence of a Brownian motion, and simply state that it exists as a condition for the result to hold. See, for example, the stochastic differential equation for Bessel processes of order 0, or the representation of local martingales as Brownian integrals. However, to apply the results, we may need to extend the space to introduce a Brownian motion if one does not already exist. One area where extensions are required in the theory is that of weak solutions to stochastic differential equations which, by definition, exist in an extension of the original space.
