Many years ago, while in high school, I tried my hand at solving cubic and quartic formulas. Although there are entirely systematic approaches, using Galois theory, this was not something that I was familiar with at the time. I had just heard that it is possible. Here, ‘solving’ means to find an expression for the roots of the polynomial in terms of its coefficients, involving the standard arithmetical operations of addition, subtraction, multiplication and division, as well as extracting square roots, cube roots, etc.
The solution for cubics went very well. In class one day, the teacher wrote a specific example of a quartic on the blackboard, and proceeded to solve it by reducing to two easy quadratics. The reason that his example worked so easily is because the coefficients formed a palindrome. That is, they were the same when written in reverse order. As an example, consider the equation,
If we divide through by 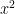 then, with a little rearranging, this gives,
then, with a little rearranging, this gives,
As a quadratic in  , this is easily solved. One solution is
, this is easily solved. One solution is 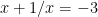 . Multiplying by x and rearranging gives a new quadratic,
. Multiplying by x and rearranging gives a new quadratic,
By the standard formula for quadratics, we obtain
It can be checked that this does give two real solutions to the original quartic.
Now, the approach that I attempted for the general quartic was to apply a substitution in order to simplify it, so that a similar method can be applied. Unfortunately, this resulted in a very messy equation, which seemed to be giving a sextic. That is, I went from the original fourth order polynomial, to what was looking like a sixth order one. This was complicating the problem, and getting further away from the goal than where I had started. I am not sure why I did not give up at that point, but I continued. Then, something amazing happened. Computing the coefficients of the sixth, fifth and fourth powers in this sextic, they all vanished! In fact, I had succeeded in reducing the quartic to a cubic, which can be solved. This still seems surprising, that such a messy looking expression should cancel out like this, in just the way that was needed. See equation (2) below for what I am talking about. As this was such a surprise at the time, and is still so now, I have decided to write it up in this post. It just demonstrates that, even if something seems hopeless, if you continue regardless then everything might just fall into place. Continue reading “An Unexpected Quartic Solution” →


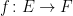

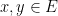

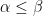




be a real-valued stochastic process such that there exists positive constants
satisfying
. Then, X has a continuous modification which, with probability one, is locally
.
![\displaystyle {\mathbb E}\left[\lvert X_t-X_s\rvert^\alpha\right]\le C\lvert t-s\vert^{1+\beta},](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D%5Cleft%5B%5Clvert+X_t-X_s%5Crvert%5E%5Calpha%5Cright%5D%5Cle+C%5Clvert+t-s%5Cvert%5E%7B1%2B%5Cbeta%7D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
![{[X]^{c}}](https://s0.wp.com/latex.php?latex=%7B%5BX%5D%5E%7Bc%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) ,
,![\displaystyle L^x_t=\int_0^t\delta(X-x)d[X]^c.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++L%5Ex_t%3D%5Cint_0%5Et%5Cdelta%28X-x%29d%5BX%5D%5Ec.+&bg=ffffff&fg=000000&s=0&c=20201002)
 and integrating over x. Commuting the order of integration on the right hand side, and applying the defining property of the delta function, that
and integrating over x. Commuting the order of integration on the right hand side, and applying the defining property of the delta function, that 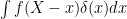 is equal to
is equal to  , gives
, gives![\displaystyle \int_{-\infty}^{\infty} L^x_t f(x)dx=\int_0^tf(X)d[X]^c.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cint_%7B-%5Cinfty%7D%5E%7B%5Cinfty%7D+L%5Ex_t+f%28x%29dx%3D%5Cint_0%5Etf%28X%29d%5BX%5D%5Ec.+&bg=ffffff&fg=000000&s=0&c=20201002)
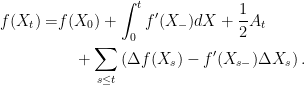
![{A_t=\int_0^t f^{\prime\prime}(X)d[X]^c}](https://s0.wp.com/latex.php?latex=%7BA_t%3D%5Cint_0%5Et+f%5E%7B%5Cprime%5Cprime%7D%28X%29d%5BX%5D%5Ec%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Equation (
. Equation (
 exists, and is itself of locally finite variation. Hence, the Stieltjes integral
exists, and is itself of locally finite variation. Hence, the Stieltjes integral  exists. The infinitesimal
exists. The infinitesimal 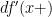 is alternatively written
is alternatively written 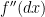 and, in the twice continuously differentiable case, equals
and, in the twice continuously differentiable case, equals 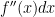 . Then,
. Then,
 and
and 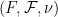 be finite measure spaces, and
be finite measure spaces, and  be a bounded
be a bounded 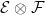 -measurable function. Then,
-measurable function. Then, 
 -measurable,
-measurable, 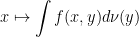
 -measurable, and,
-measurable, and, 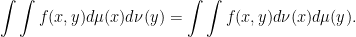
 .
.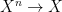

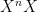
![{[S]_\infty}](https://s0.wp.com/latex.php?latex=%7B%5BS%5D_%5Cinfty%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![[S]_\infty](https://s0.wp.com/latex.php?latex=%5BS%5D_%5Cinfty&bg=ffffff&fg=000000&s=0&c=20201002)
![[S]](https://s0.wp.com/latex.php?latex=%5BS%5D&bg=ffffff&fg=000000&s=0&c=20201002)


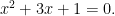
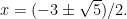

 That which we call a rose, by any other name would smell as sweet.
That which we call a rose, by any other name would smell as sweet.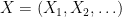 and square summable sequence of real numbers
and square summable sequence of real numbers  , the
, the 
 for the space of square summable real sequences and
for the space of square summable real sequences and
 , there exists positive constants
, there exists positive constants  such that,
such that, ![\displaystyle c_p\lVert a\rVert_2^p\le{\mathbb E}\left[\lvert a\cdot X\rvert^p\right]\le C_p\lVert a\rVert_2^p,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++c_p%5ClVert+a%5CrVert_2%5Ep%5Cle%7B%5Cmathbb+E%7D%5Cleft%5B%5Clvert+a%5Ccdot+X%5Crvert%5Ep%5Cright%5D%5Cle+C_p%5ClVert+a%5CrVert_2%5Ep%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
 .
. 